 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Memory Mapping Using Deep Reinforcement Learning
May 11, 2023



Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.
Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs
Jul 22, 2021
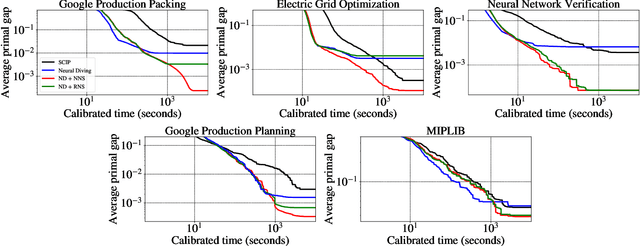
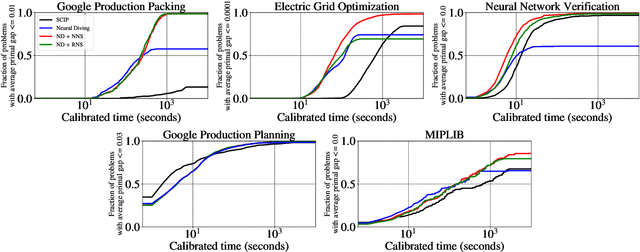
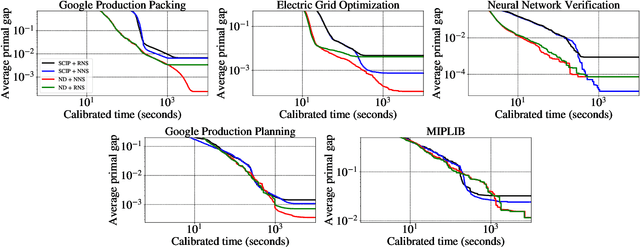
Large Neighborhood Search (LNS) is a combinatorial optimization heuristic that starts with an assignment of values for the variables to be optimized, and iteratively improves it by searching a large neighborhood around the current assignment. In this paper we consider a learning-based LNS approach for mixed integer programs (MIPs). We train a Neural Diving model to represent a probability distribution over assignments, which, together with an off-the-shelf MIP solver, generates an initial assignment. Formulating the subsequent search steps as a Markov Decision Process, we train a Neural Neighborhood Selection policy to select a search neighborhood at each step, which is searched using a MIP solver to find the next assignment. The policy network is trained using imitation learning. We propose a target policy for imitation that, given enough compute resources, is guaranteed to select the neighborhood containing the optimal next assignment amongst all possible choices for the neighborhood of a specified size. Our approach matches or outperforms all the baselines on five real-world MIP datasets with large-scale instances from diverse applications, including two production applications at Google. It achieves $2\times$ to $37.8\times$ better average primal gap than the best baseline on three of the datasets at large running times.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020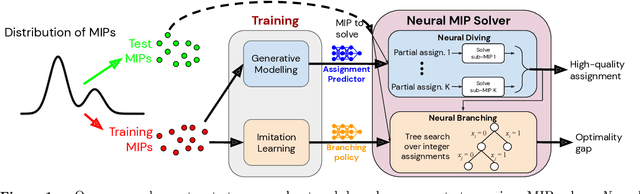
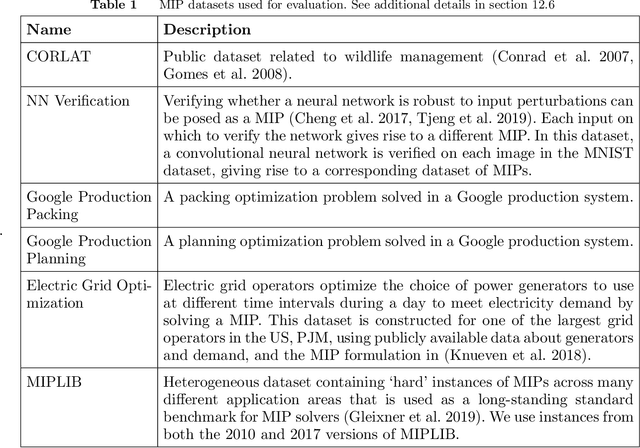
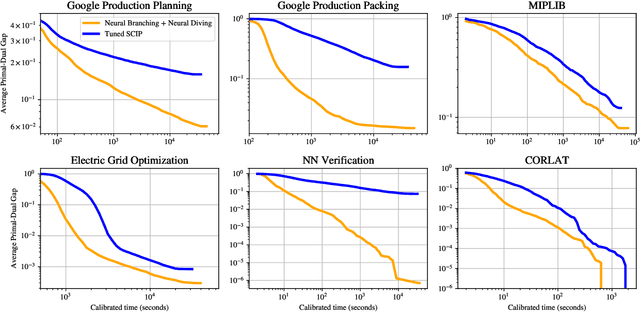
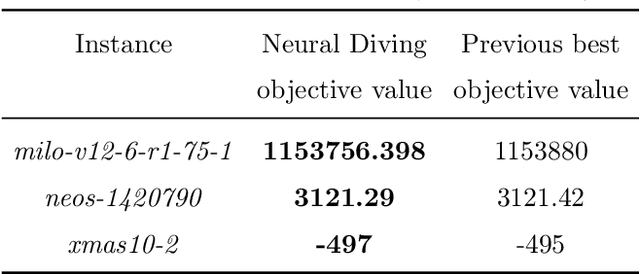
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.