 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquilibrium Aggregation: Encoding Sets via Optimization
Feb 25, 2022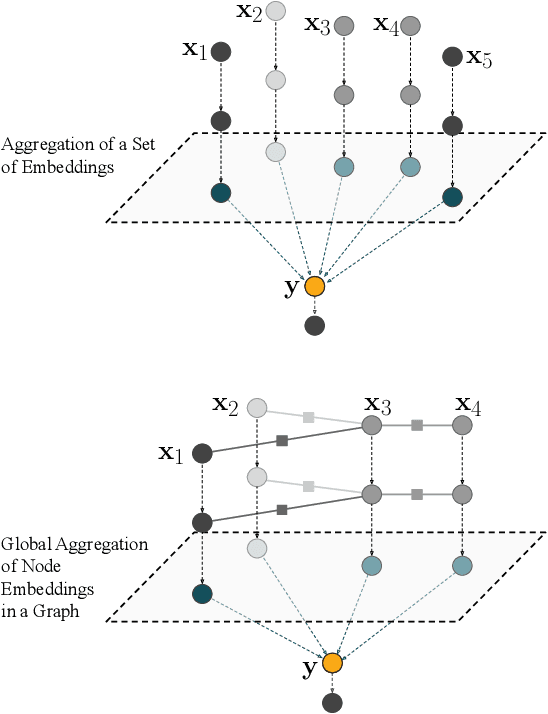

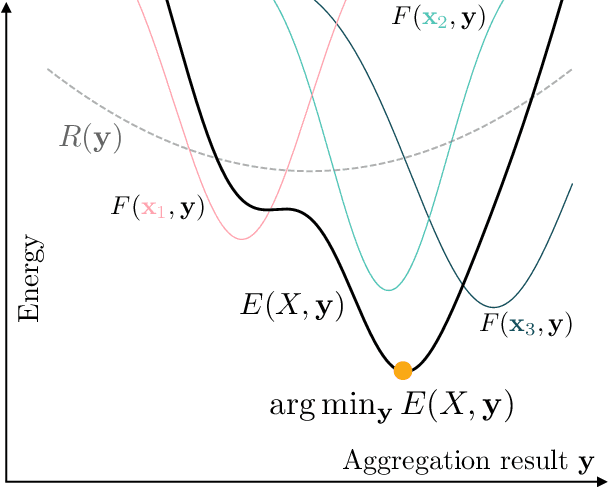
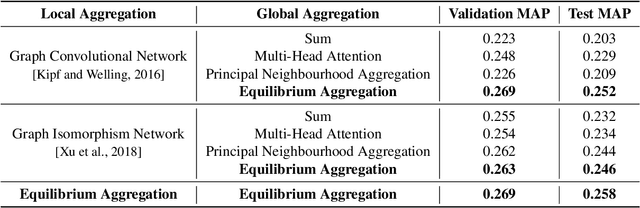
Processing sets or other unordered, potentially variable-sized inputs in neural networks is usually handled by \emph{aggregating} a number of input tensors into a single representation. While a number of aggregation methods already exist from simple sum pooling to multi-head attention, they are limited in their representational power both from theoretical and empirical perspectives. On the search of a principally more powerful aggregation strategy, we propose an optimization-based method called Equilibrium Aggregation. We show that many existing aggregation methods can be recovered as special cases of Equilibrium Aggregation and that it is provably more efficient in some important cases. Equilibrium Aggregation can be used as a drop-in replacement in many existing architectures and applications. We validate its efficiency on three different tasks: median estimation, class counting, and molecular property prediction. In all experiments, Equilibrium Aggregation achieves higher performance than the other aggregation techniques we test.
Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs
Jul 22, 2021
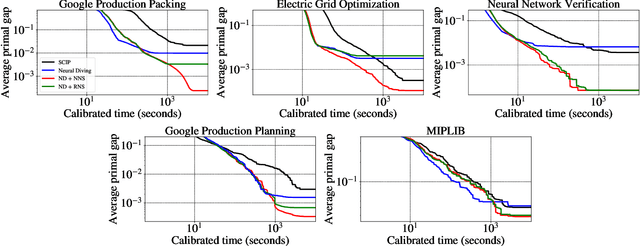
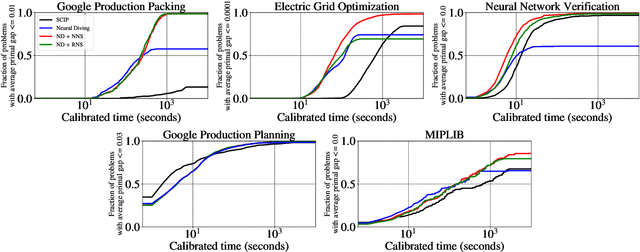
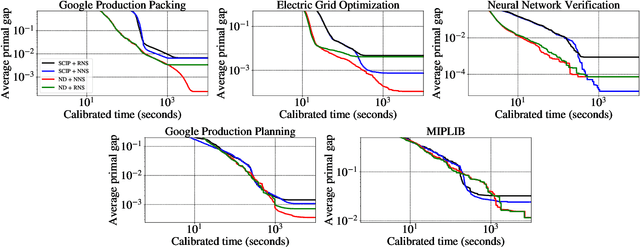
Large Neighborhood Search (LNS) is a combinatorial optimization heuristic that starts with an assignment of values for the variables to be optimized, and iteratively improves it by searching a large neighborhood around the current assignment. In this paper we consider a learning-based LNS approach for mixed integer programs (MIPs). We train a Neural Diving model to represent a probability distribution over assignments, which, together with an off-the-shelf MIP solver, generates an initial assignment. Formulating the subsequent search steps as a Markov Decision Process, we train a Neural Neighborhood Selection policy to select a search neighborhood at each step, which is searched using a MIP solver to find the next assignment. The policy network is trained using imitation learning. We propose a target policy for imitation that, given enough compute resources, is guaranteed to select the neighborhood containing the optimal next assignment amongst all possible choices for the neighborhood of a specified size. Our approach matches or outperforms all the baselines on five real-world MIP datasets with large-scale instances from diverse applications, including two production applications at Google. It achieves $2\times$ to $37.8\times$ better average primal gap than the best baseline on three of the datasets at large running times.
Computer-Aided Design as Language
May 06, 2021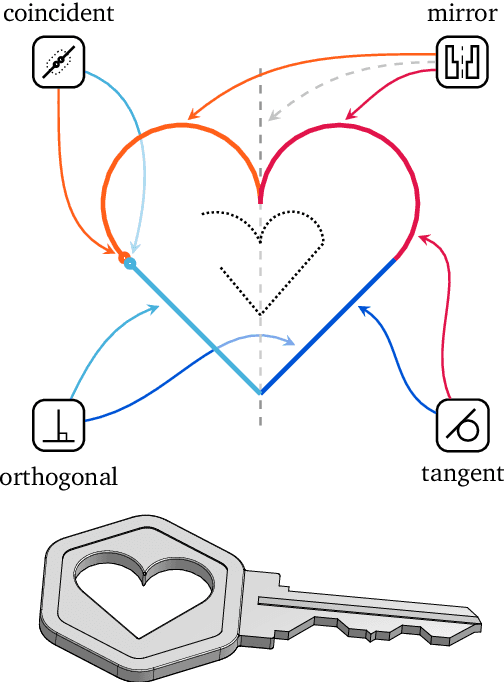
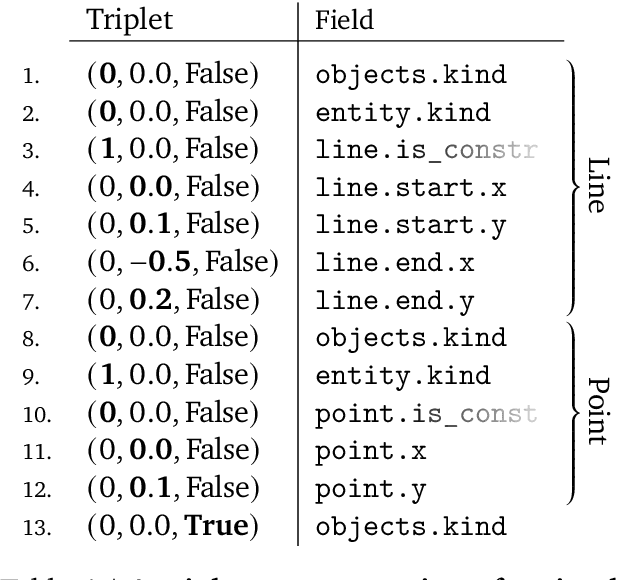
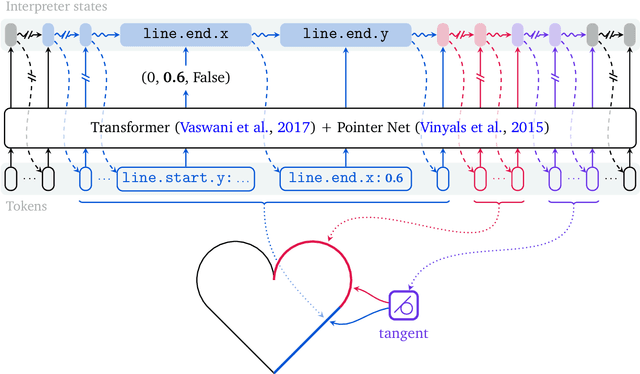
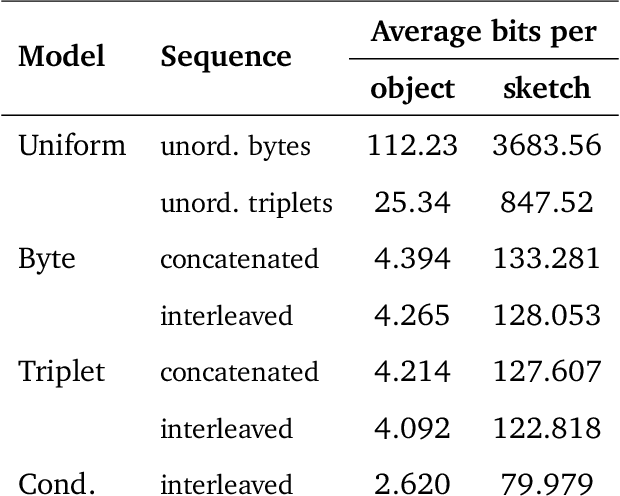
Computer-Aided Design (CAD) applications are used in manufacturing to model everything from coffee mugs to sports cars. These programs are complex and require years of training and experience to master. A component of all CAD models particularly difficult to make are the highly structured 2D sketches that lie at the heart of every 3D construction. In this work, we propose a machine learning model capable of automatically generating such sketches. Through this, we pave the way for developing intelligent tools that would help engineers create better designs with less effort. Our method is a combination of a general-purpose language modeling technique alongside an off-the-shelf data serialization protocol. We show that our approach has enough flexibility to accommodate the complexity of the domain and performs well for both unconditional synthesis and image-to-sketch translation.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020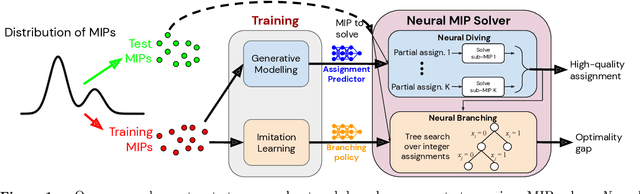
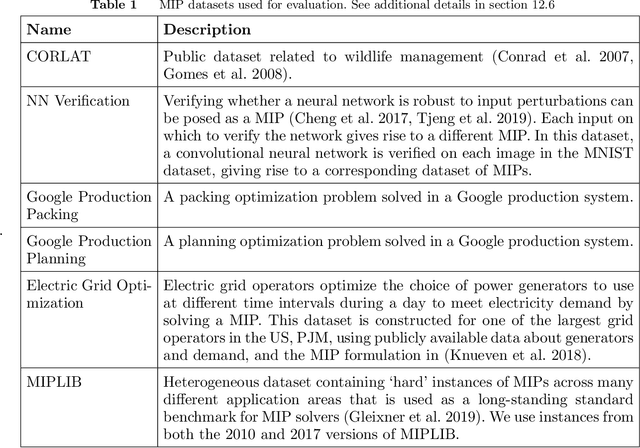
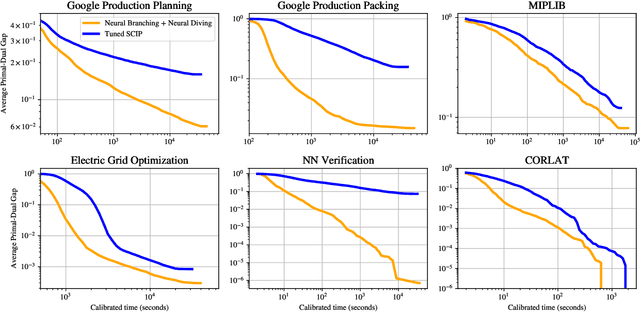
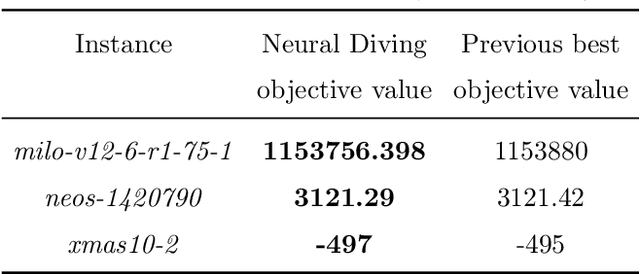
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.
Meta-Learning Deep Energy-Based Memory Models
Oct 07, 2019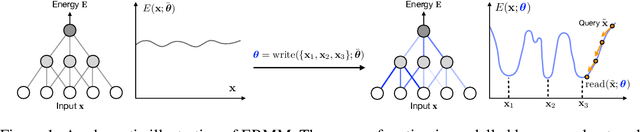
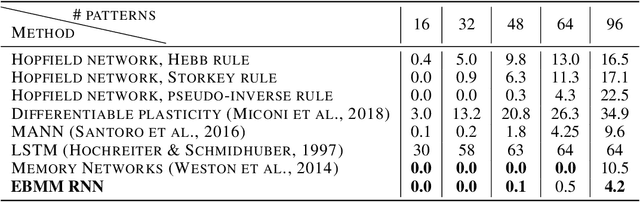
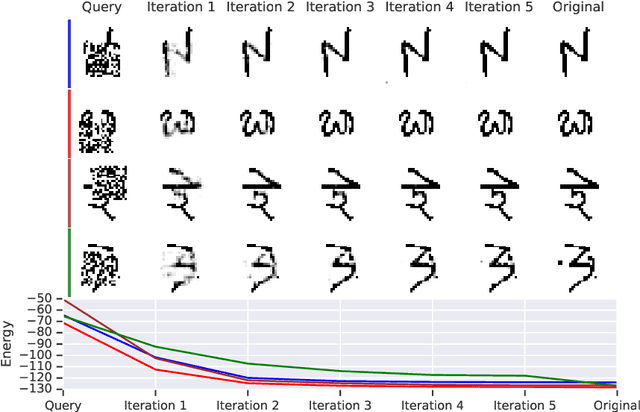
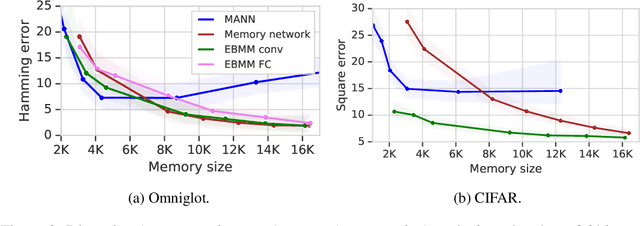
We study the problem of learning associative memory -- a system which is able to retrieve a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associative memory: patterns are stored as attractors of the network dynamics and associative retrieval is performed by running the dynamics starting from a query pattern until it converges to an attractor. In such models the dynamics are often implemented as an optimization procedure that minimizes an energy function, such as in the classical Hopfield network. In general it is difficult to derive a writing rule for a given dynamics and energy that is both compressive and fast. Thus, most research in energy-based memory has been limited either to tractable energy models not expressive enough to handle complex high-dimensional objects such as natural images, or to models that do not offer fast writing. We present a novel meta-learning approach to energy-based memory models (EBMM) that allows one to use an arbitrary neural architecture as an energy model and quickly store patterns in its weights. We demonstrate experimentally that our EBMM approach can build compressed memories for synthetic and natural data, and is capable of associative retrieval that outperforms existing memory systems in terms of the reconstruction error and compression rate.
Meta-Learning Neural Bloom Filters
Jun 10, 2019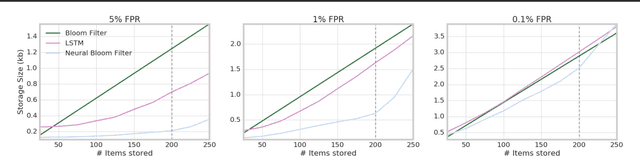
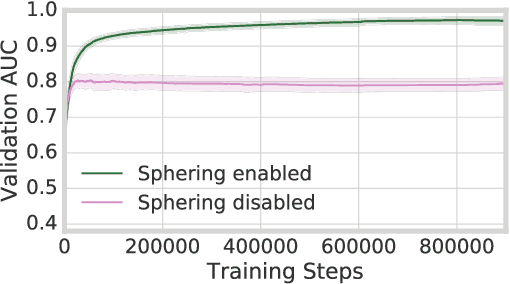
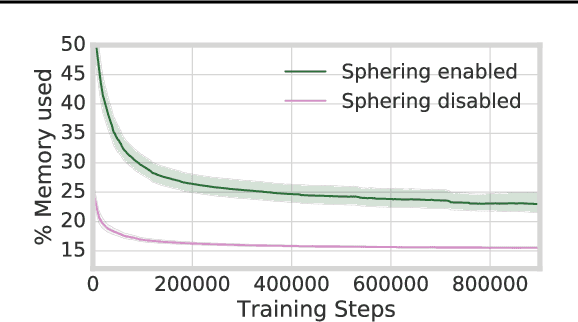
There has been a recent trend in training neural networks to replace data structures that have been crafted by hand, with an aim for faster execution, better accuracy, or greater compression. In this setting, a neural data structure is instantiated by training a network over many epochs of its inputs until convergence. In applications where inputs arrive at high throughput, or are ephemeral, training a network from scratch is not practical. This motivates the need for few-shot neural data structures. In this paper we explore the learning of approximate set membership over a set of data in one-shot via meta-learning. We propose a novel memory architecture, the Neural Bloom Filter, which is able to achieve significant compression gains over classical Bloom Filters and existing memory-augmented neural networks.
Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures
Jul 12, 2018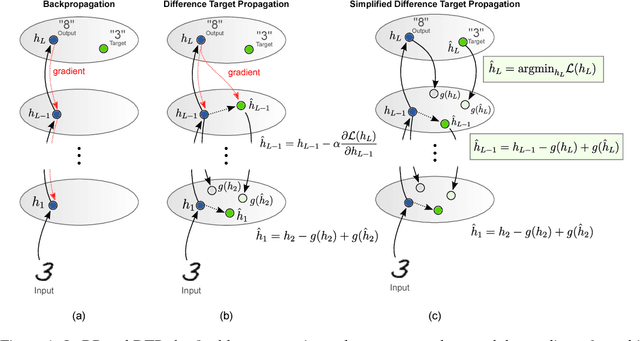
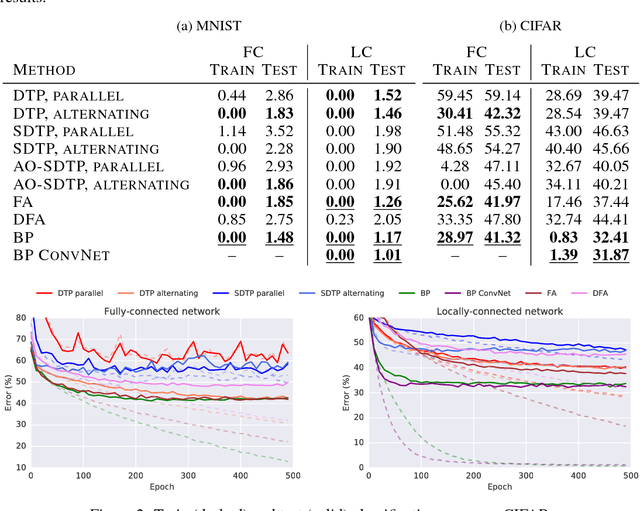
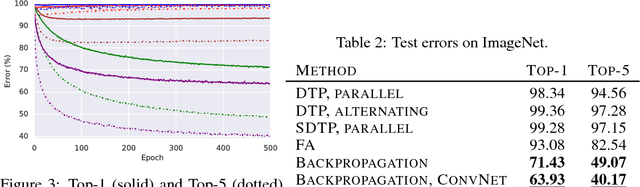

The backpropagation of error algorithm (BP) is often said to be impossible to implement in a real brain. The recent success of deep networks in machine learning and AI, however, has inspired proposals for understanding how the brain might learn across multiple layers, and hence how it might implement or approximate BP. As of yet, none of these proposals have been rigorously evaluated on tasks where BP-guided deep learning has proved critical, or in architectures more structured than simple fully-connected networks. Here we present the first results on scaling up biologically motivated models of deep learning on datasets which need deep networks with appropriate architectures to achieve good performance. We present results on the MNIST, CIFAR-10, and ImageNet datasets and explore variants of target-propagation (TP) and feedback alignment (FA) algorithms, and explore performance in both fully- and locally-connected architectures. We also introduce weight-transport-free variants of difference target propagation (DTP) modified to remove backpropagation from the penultimate layer. Many of these algorithms perform well for MNIST, but for CIFAR and ImageNet we find that TP and FA variants perform significantly worse than BP, especially for networks composed of locally connected units, opening questions about whether new architectures and algorithms are required to scale these approaches. Our results and implementation details help establish baselines for biologically motivated deep learning schemes going forward.
Adaptive Cardinality Estimation
Nov 22, 2017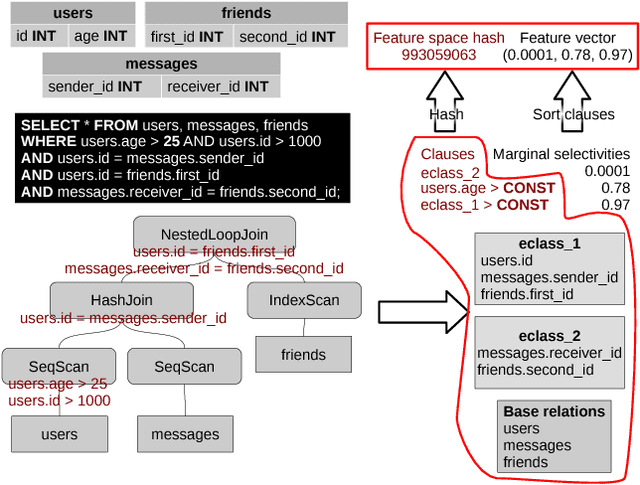
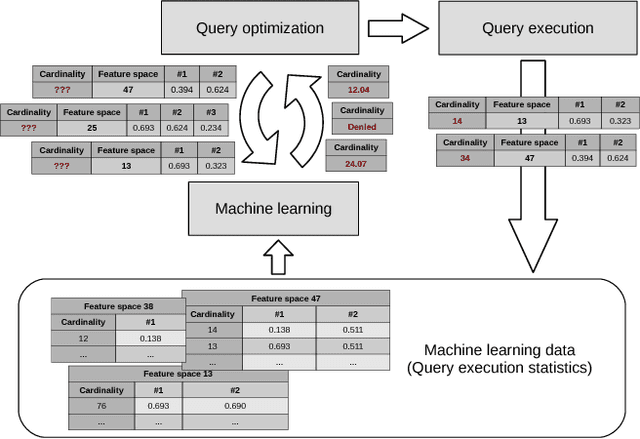
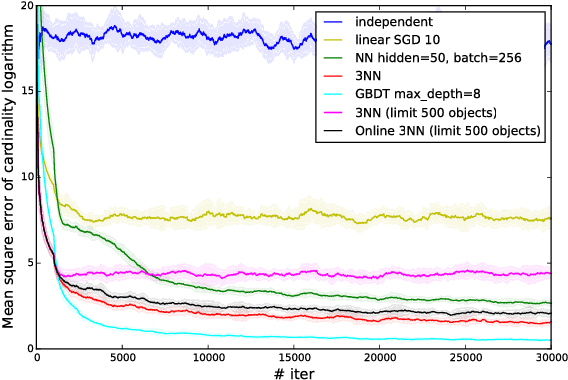
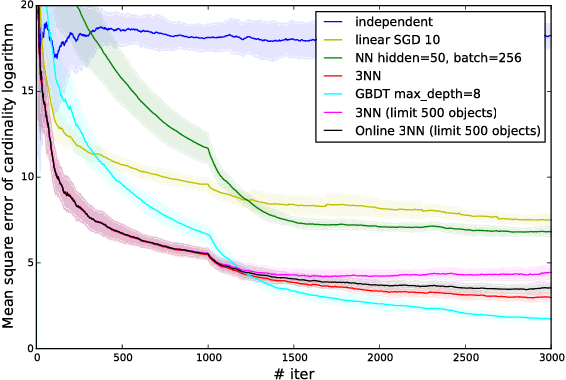
In this paper we address cardinality estimation problem which is an important subproblem in query optimization. Query optimization is a part of every relational DBMS responsible for finding the best way of the execution for the given query. These ways are called plans. The execution time of different plans may differ by several orders, so query optimizer has a great influence on the whole DBMS performance. We consider cost-based query optimization approach as the most popular one. It was observed that cost-based optimization quality depends much on cardinality estimation quality. Cardinality of the plan node is the number of tuples returned by it. In the paper we propose a novel cardinality estimation approach with the use of machine learning methods. The main point of the approach is using query execution statistics of the previously executed queries to improve cardinality estimations. We called this approach adaptive cardinality estimation to reflect this point. The approach is general, flexible, and easy to implement. The experimental evaluation shows that this approach significantly increases the quality of cardinality estimation, and therefore increases the DBMS performance for some queries by several times or even by several dozens of times.
Fast Adaptation in Generative Models with Generative Matching Networks
Sep 05, 2017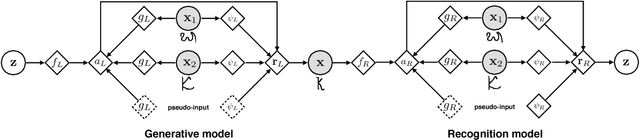
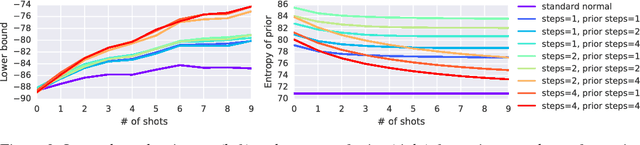
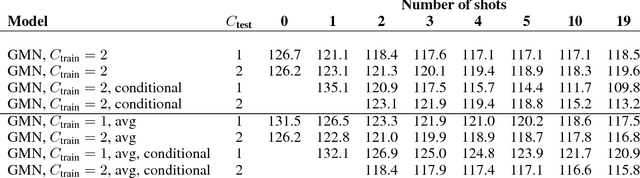
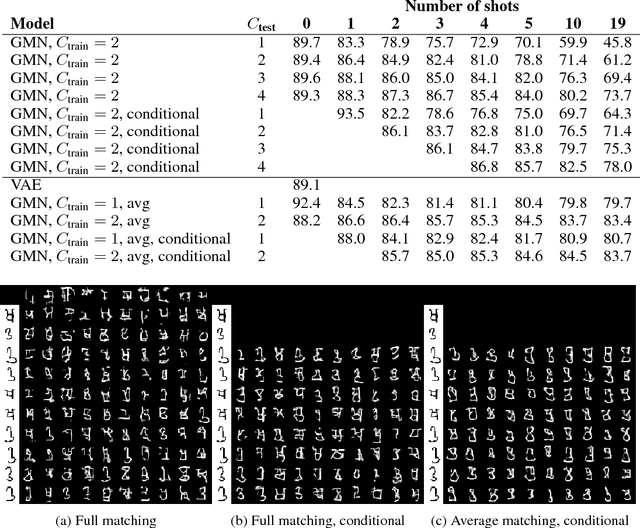
Despite recent advances, the remaining bottlenecks in deep generative models are necessity of extensive training and difficulties with generalization from small number of training examples. We develop a new generative model called Generative Matching Network which is inspired by the recently proposed matching networks for one-shot learning in discriminative tasks. By conditioning on the additional input dataset, our model can instantly learn new concepts that were not available in the training data but conform to a similar generative process. The proposed framework does not explicitly restrict diversity of the conditioning data and also does not require an extensive inference procedure for training or adaptation. Our experiments on the Omniglot dataset demonstrate that Generative Matching Networks significantly improve predictive performance on the fly as more additional data is available and outperform existing state of the art conditional generative models.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017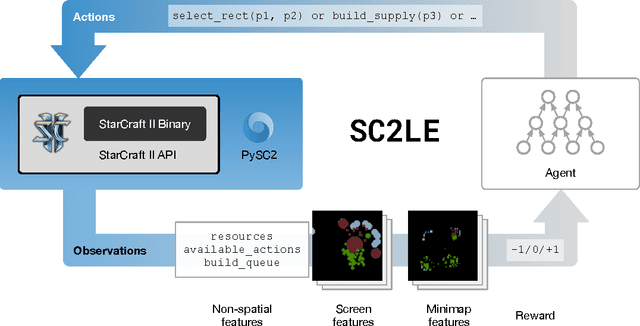
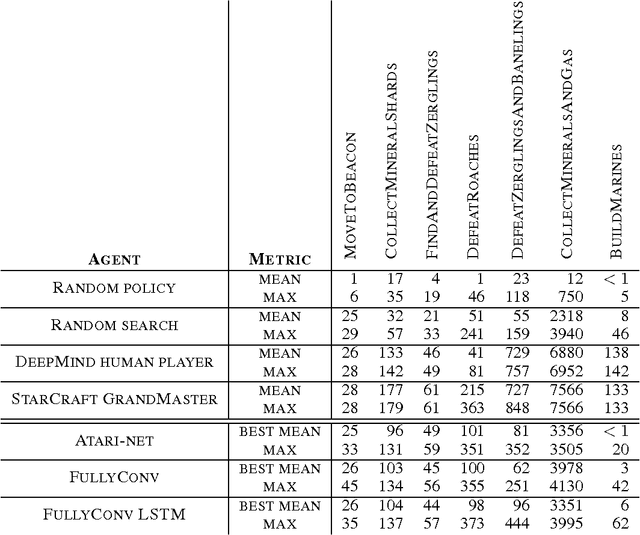

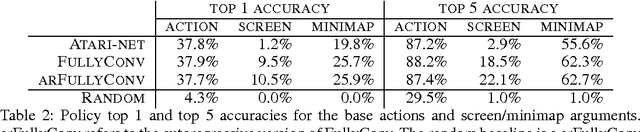
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.