 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedProp: Cross-client Label Propagation for Federated Semi-supervised Learning
Oct 12, 2022
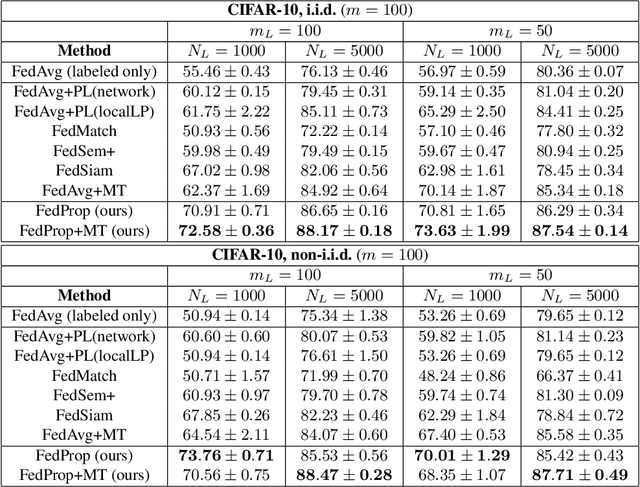
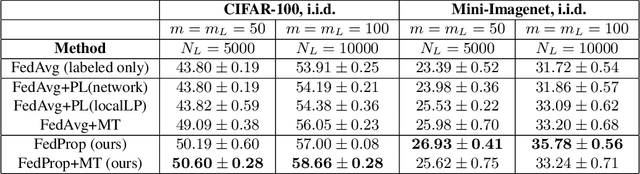
Federated learning (FL) allows multiple clients to jointly train a machine learning model in such a way that no client has to share their data with any other participating party. In the supervised setting, where all client data is fully labeled, FL has been widely adopted for learning tasks that require data privacy. However, it is an ongoing research question how to best perform federated learning in a semi-supervised setting, where the clients possess data that is only partially labeled or even completely unlabeled. In this work, we propose a new method, FedProp, that follows a manifold-based approach to semi-supervised learning (SSL). It estimates the data manifold jointly from the data of multiple clients and computes pseudo-labels using cross-client label propagation. To avoid that clients have to share their data with anyone, FedProp employs two cryptographically secure yet highly efficient protocols: secure Hamming distance computation and secure summation. Experiments on three standard benchmarks show that FedProp achieves higher classification accuracy than previous federated SSL methods. Furthermore, as a pseudolabel-based technique, FedProp is complementary to other federated SSL approaches, in particular consistency-based ones. We demonstrate experimentally that further accuracy gains are possible by combining both.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017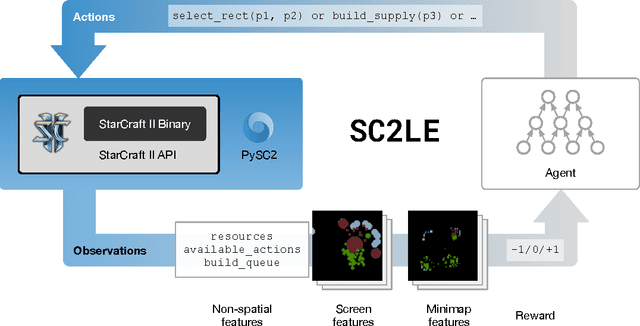
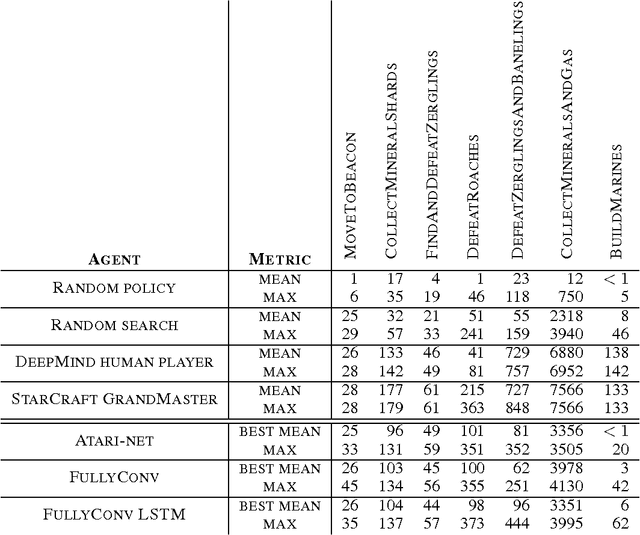

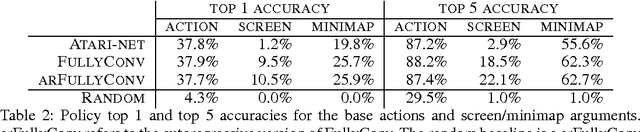
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.