 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Persona Generators: Generating Diverse Synthetic Personas at Scale
Feb 03, 2026Evaluating AI systems that interact with humans requires understanding their behavior across diverse user populations, but collecting representative human data is often expensive or infeasible, particularly for novel technologies or hypothetical future scenarios. Recent work in Generative Agent-Based Modeling has shown that large language models can simulate human-like synthetic personas with high fidelity, accurately reproducing the beliefs and behaviors of specific individuals. However, most approaches require detailed data about target populations and often prioritize density matching (replicating what is most probable) rather than support coverage (spanning what is possible), leaving long-tail behaviors underexplored. We introduce Persona Generators, functions that can produce diverse synthetic populations tailored to arbitrary contexts. We apply an iterative improvement loop based on AlphaEvolve, using large language models as mutation operators to refine our Persona Generator code over hundreds of iterations. The optimization process produces lightweight Persona Generators that can automatically expand small descriptions into populations of diverse synthetic personas that maximize coverage of opinions and preferences along relevant diversity axes. We demonstrate that evolved generators substantially outperform existing baselines across six diversity metrics on held-out contexts, producing populations that span rare trait combinations difficult to achieve in standard LLM outputs.
A Pragmatic View of AI Personhood
Oct 30, 2025The emergence of agentic Artificial Intelligence (AI) is set to trigger a "Cambrian explosion" of new kinds of personhood. This paper proposes a pragmatic framework for navigating this diversification by treating personhood not as a metaphysical property to be discovered, but as a flexible bundle of obligations (rights and responsibilities) that societies confer upon entities for a variety of reasons, especially to solve concrete governance problems. We argue that this traditional bundle can be unbundled, creating bespoke solutions for different contexts. This will allow for the creation of practical tools -- such as facilitating AI contracting by creating a target "individual" that can be sanctioned -- without needing to resolve intractable debates about an AI's consciousness or rationality. We explore how individuals fit in to social roles and discuss the use of decentralized digital identity technology, examining both "personhood as a problem", where design choices can create "dark patterns" that exploit human social heuristics, and "personhood as a solution", where conferring a bundle of obligations is necessary to ensure accountability or prevent conflict. By rejecting foundationalist quests for a single, essential definition of personhood, this paper offers a more pragmatic and flexible way to think about integrating AI agents into our society.
Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt
May 08, 2025Artificial Intelligence (AI) systems are increasingly placed in positions where their decisions have real consequences, e.g., moderating online spaces, conducting research, and advising on policy. Ensuring they operate in a safe and ethically acceptable fashion is thus critical. However, most solutions have been a form of one-size-fits-all "alignment". We are worried that such systems, which overlook enduring moral diversity, will spark resistance, erode trust, and destabilize our institutions. This paper traces the underlying problem to an often-unstated Axiom of Rational Convergence: the idea that under ideal conditions, rational agents will converge in the limit of conversation on a single ethics. Treating that premise as both optional and doubtful, we propose what we call the appropriateness framework: an alternative approach grounded in conflict theory, cultural evolution, multi-agent systems, and institutional economics. The appropriateness framework treats persistent disagreement as the normal case and designs for it by applying four principles: (1) contextual grounding, (2) community customization, (3) continual adaptation, and (4) polycentric governance. We argue here that adopting these design principles is a good way to shift the main alignment metaphor from moral unification to a more productive metaphor of conflict management, and that taking this step is both desirable and urgent.
A theory of appropriateness with applications to generative artificial intelligence
Dec 26, 2024

What is appropriateness? Humans navigate a multi-scale mosaic of interlocking notions of what is appropriate for different situations. We act one way with our friends, another with our family, and yet another in the office. Likewise for AI, appropriate behavior for a comedy-writing assistant is not the same as appropriate behavior for a customer-service representative. What determines which actions are appropriate in which contexts? And what causes these standards to change over time? Since all judgments of AI appropriateness are ultimately made by humans, we need to understand how appropriateness guides human decision making in order to properly evaluate AI decision making and improve it. This paper presents a theory of appropriateness: how it functions in human society, how it may be implemented in the brain, and what it means for responsible deployment of generative AI technology.
Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia
Dec 13, 2023



Agent-based modeling has been around for decades, and applied widely across the social and natural sciences. The scope of this research method is now poised to grow dramatically as it absorbs the new affordances provided by Large Language Models (LLM)s. Generative Agent-Based Models (GABM) are not just classic Agent-Based Models (ABM)s where the agents talk to one another. Rather, GABMs are constructed using an LLM to apply common sense to situations, act "reasonably", recall common semantic knowledge, produce API calls to control digital technologies like apps, and communicate both within the simulation and to researchers viewing it from the outside. Here we present Concordia, a library to facilitate constructing and working with GABMs. Concordia makes it easy to construct language-mediated simulations of physically- or digitally-grounded environments. Concordia agents produce their behavior using a flexible component system which mediates between two fundamental operations: LLM calls and associative memory retrieval. A special agent called the Game Master (GM), which was inspired by tabletop role-playing games, is responsible for simulating the environment where the agents interact. Agents take actions by describing what they want to do in natural language. The GM then translates their actions into appropriate implementations. In a simulated physical world, the GM checks the physical plausibility of agent actions and describes their effects. In digital environments simulating technologies such as apps and services, the GM may handle API calls to integrate with external tools such as general AI assistants (e.g., Bard, ChatGPT), and digital apps (e.g., Calendar, Email, Search, etc.). Concordia was designed to support a wide array of applications both in scientific research and for evaluating performance of real digital services by simulating users and/or generating synthetic data.
Diversity Through Exclusion (DTE): Niche Identification for Reinforcement Learning through Value-Decomposition
Feb 03, 2023



Many environments contain numerous available niches of variable value, each associated with a different local optimum in the space of behaviors (policy space). In such situations it is often difficult to design a learning process capable of evading distraction by poor local optima long enough to stumble upon the best available niche. In this work we propose a generic reinforcement learning (RL) algorithm that performs better than baseline deep Q-learning algorithms in such environments with multiple variably-valued niches. The algorithm we propose consists of two parts: an agent architecture and a learning rule. The agent architecture contains multiple sub-policies. The learning rule is inspired by fitness sharing in evolutionary computation and applied in reinforcement learning using Value-Decomposition-Networks in a novel manner for a single-agent's internal population. It can concretely be understood as adding an extra loss term where one policy's experience is also used to update all the other policies in a manner that decreases their value estimates for the visited states. In particular, when one sub-policy visits a particular state frequently this decreases the value predicted for other sub-policies for going to that state. Further, we introduce an artificial chemistry inspired platform where it is easy to create tasks with multiple rewarding strategies utilizing different resources (i.e. multiple niches). We show that agents trained this way can escape poor-but-attractive local optima to instead converge to harder-to-discover higher value strategies in both the artificial chemistry environments and in simpler illustrative environments.
Melting Pot 2.0
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022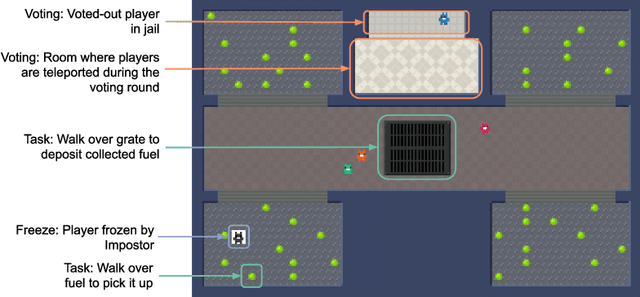

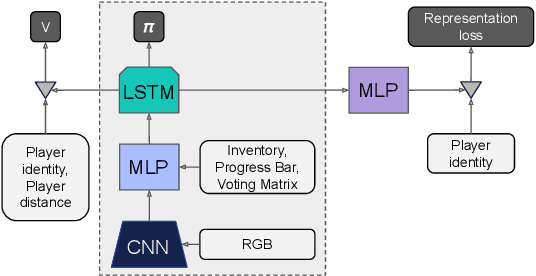
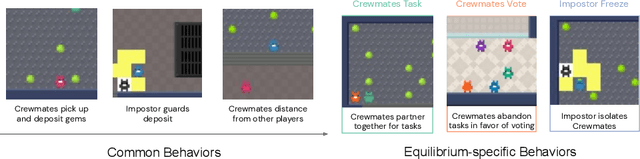
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Statistical discrimination in learning agents
Oct 21, 2021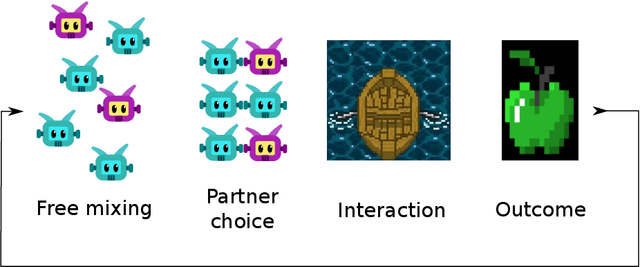
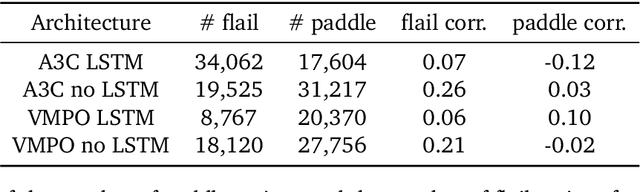
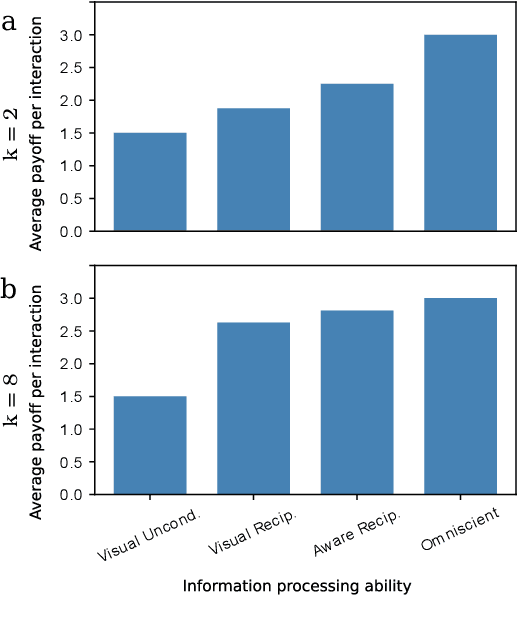
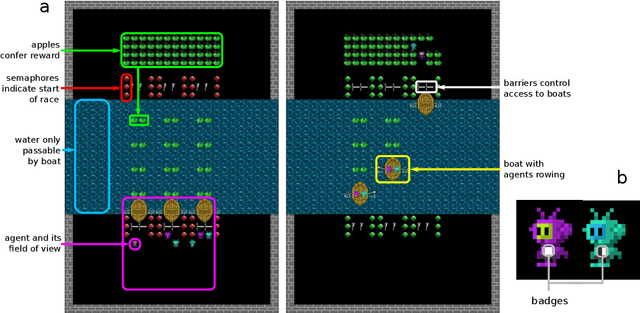
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.