 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Ensemble Improves Video-Language Models for Low-Level Workflow Understanding from Human Demonstrations
Sep 26, 2024



A Standard Operating Procedure (SOP) defines a low-level, step-by-step written guide for a business software workflow based on a video demonstration. SOPs are a crucial step toward automating end-to-end software workflows. Manually creating SOPs can be time-consuming. Recent advancements in large video-language models offer the potential for automating SOP generation by analyzing recordings of human demonstrations. However, current large video-language models face challenges with zero-shot SOP generation. We explore in-context learning with video-language models for SOP generation. We report that in-context learning sometimes helps video-language models at SOP generation. We then propose an in-context ensemble learning to further enhance the capabilities of the models in SOP generation.
Training a Vision Language Model as Smartphone Assistant
Apr 12, 2024


Addressing the challenge of a digital assistant capable of executing a wide array of user tasks, our research focuses on the realm of instruction-based mobile device control. We leverage recent advancements in large language models (LLMs) and present a visual language model (VLM) that can fulfill diverse tasks on mobile devices. Our model functions by interacting solely with the user interface (UI). It uses the visual input from the device screen and mimics human-like interactions, encompassing gestures such as tapping and swiping. This generality in the input and output space allows our agent to interact with any application on the device. Unlike previous methods, our model operates not only on a single screen image but on vision-language sentences created from sequences of past screenshots along with corresponding actions. Evaluating our method on the challenging Android in the Wild benchmark demonstrates its promising efficacy and potential.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022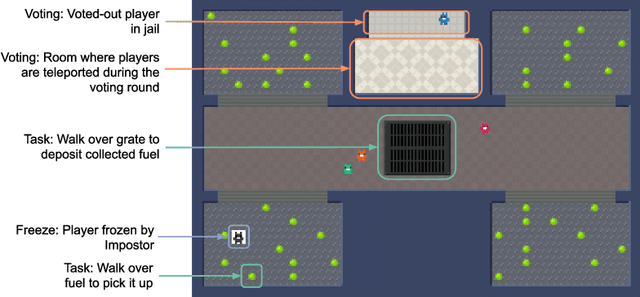

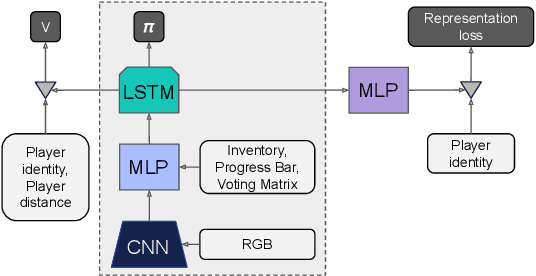
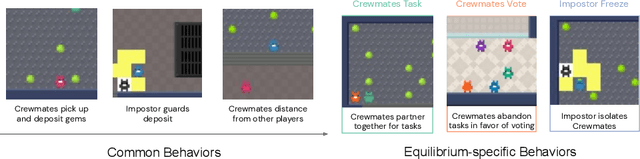
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Solution Methods for Constrained Markov Decision Process with Continuous Probability Modulation
Sep 26, 2013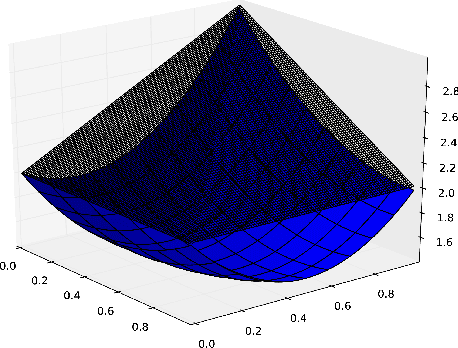

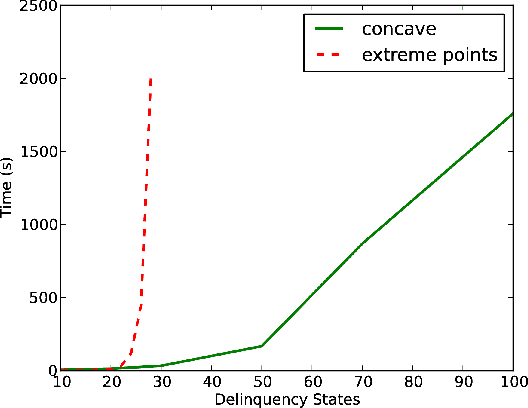

We propose solution methods for previously-unsolved constrained MDPs in which actions can continuously modify the transition probabilities within some acceptable sets. While many methods have been proposed to solve regular MDPs with large state sets, there are few practical approaches for solving constrained MDPs with large action sets. In particular, we show that the continuous action sets can be replaced by their extreme points when the rewards are linear in the modulation. We also develop a tractable optimization formulation for concave reward functions and, surprisingly, also extend it to non- concave reward functions by using their concave envelopes. We evaluate the effectiveness of the approach on the problem of managing delinquencies in a portfolio of loans.
ALARMS: Alerting and Reasoning Management System for Next Generation Aircraft Hazards
Mar 15, 2012

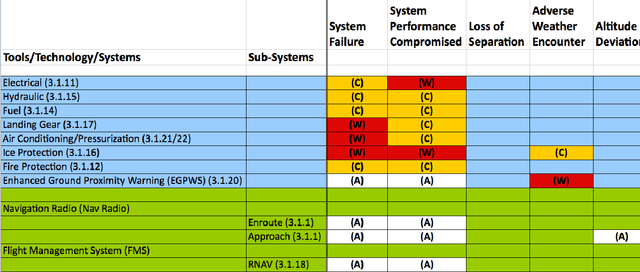

The Next Generation Air Transportation System will introduce new, advanced sensor technologies into the cockpit. With the introduction of such systems, the responsibilities of the pilot are expected to dramatically increase. In the ALARMS (ALerting And Reasoning Management System) project for NASA, we focus on a key challenge of this environment, the quick and efficient handling of aircraft sensor alerts. It is infeasible to alert the pilot on the state of all subsystems at all times. Furthermore, there is uncertainty as to the true hazard state despite the evidence of the alerts, and there is uncertainty as to the effect and duration of actions taken to address these alerts. This paper reports on the first steps in the construction of an application designed to handle Next Generation alerts. In ALARMS, we have identified 60 different aircraft subsystems and 20 different underlying hazards. In this paper, we show how a Bayesian network can be used to derive the state of the underlying hazards, based on the sensor input. Then, we propose a framework whereby an automated system can plan to address these hazards in cooperation with the pilot, using a Time-Dependent Markov Process (TMDP). Different hazards and pilot states will call for different alerting automation plans. We demonstrate this emerging application of Bayesian networks and TMDPs to cockpit automation, for a use case where a small number of hazards are present, and analyze the resulting alerting automation policies.