 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Dec 29, 2025One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
Evaluating Gemini in an arena for learning
May 30, 2025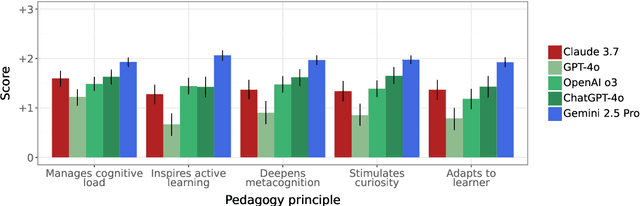

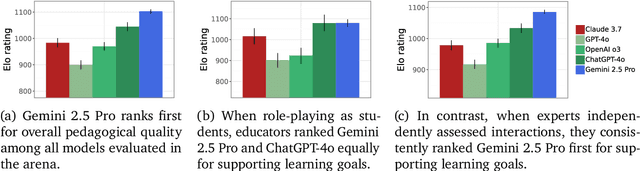
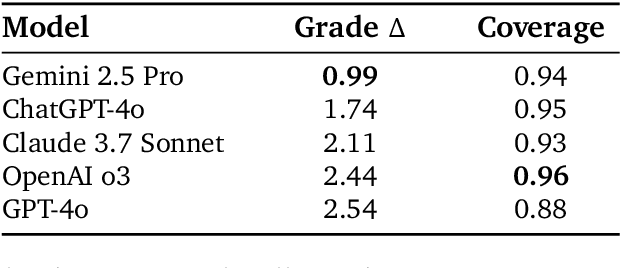
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
A social path to human-like artificial intelligence
May 22, 2024Traditionally, cognitive and computer scientists have viewed intelligence solipsistically, as a property of unitary agents devoid of social context. Given the success of contemporary learning algorithms, we argue that the bottleneck in artificial intelligence (AI) progress is shifting from data assimilation to novel data generation. We bring together evidence showing that natural intelligence emerges at multiple scales in networks of interacting agents via collective living, social relationships and major evolutionary transitions, which contribute to novel data generation through mechanisms such as population pressures, arms races, Machiavellian selection, social learning and cumulative culture. Many breakthroughs in AI exploit some of these processes, from multi-agent structures enabling algorithms to master complex games like Capture-The-Flag and StarCraft II, to strategic communication in Diplomacy and the shaping of AI data streams by other AIs. Moving beyond a solipsistic view of agency to integrate these mechanisms suggests a path to human-like compounding innovation through ongoing novel data generation.
Recourse for reclamation: Chatting with generative language models
Mar 21, 2024


Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023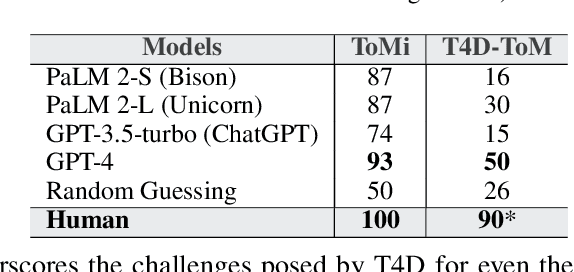


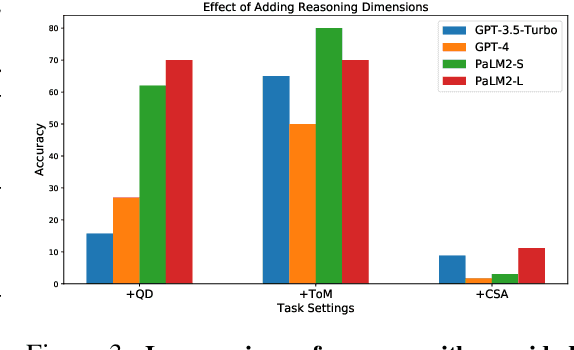
"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
Heterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas
May 01, 2023



In social psychology, Social Value Orientation (SVO) describes an individual's propensity to allocate resources between themself and others. In reinforcement learning, SVO has been instantiated as an intrinsic motivation that remaps an agent's rewards based on particular target distributions of group reward. Prior studies show that groups of agents endowed with heterogeneous SVO learn diverse policies in settings that resemble the incentive structure of Prisoner's dilemma. Our work extends this body of results and demonstrates that (1) heterogeneous SVO leads to meaningfully diverse policies across a range of incentive structures in sequential social dilemmas, as measured by task-specific diversity metrics; and (2) learning a best response to such policy diversity leads to better zero-shot generalization in some situations. We show that these best-response agents learn policies that are conditioned on their co-players, which we posit is the reason for improved zero-shot generalization results.
Combining Tree-Search, Generative Models, and Nash Bargaining Concepts in Game-Theoretic Reinforcement Learning
Feb 01, 2023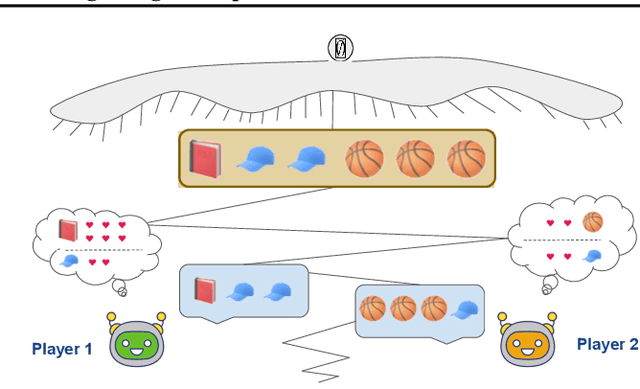
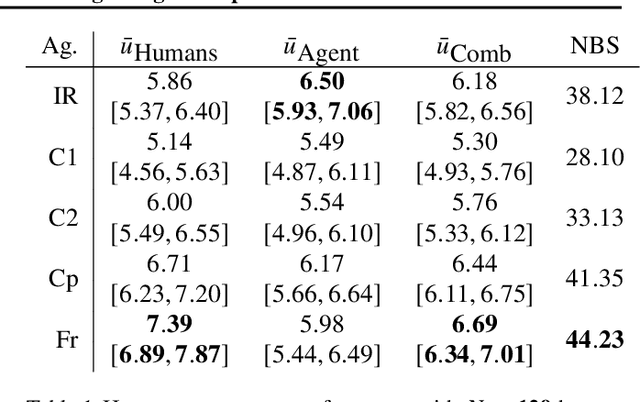
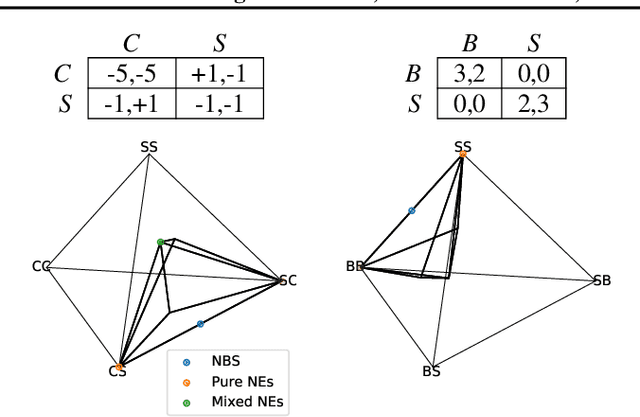
Multiagent reinforcement learning (MARL) has benefited significantly from population-based and game-theoretic training regimes. One approach, Policy-Space Response Oracles (PSRO), employs standard reinforcement learning to compute response policies via approximate best responses and combines them via meta-strategy selection. We augment PSRO by adding a novel search procedure with generative sampling of world states, and introduce two new meta-strategy solvers based on the Nash bargaining solution. We evaluate PSRO's ability to compute approximate Nash equilibrium, and its performance in two negotiation games: Colored Trails, and Deal or No Deal. We conduct behavioral studies where human participants negotiate with our agents ($N = 346$). We find that search with generative modeling finds stronger policies during both training time and test time, enables online Bayesian co-player prediction, and can produce agents that achieve comparable social welfare negotiating with humans as humans trading among themselves.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Subverting machines, fluctuating identities: Re-learning human categorization
May 27, 2022
Most machine learning systems that interact with humans construct some notion of a person's "identity," yet the default paradigm in AI research envisions identity with essential attributes that are discrete and static. In stark contrast, strands of thought within critical theory present a conception of identity as malleable and constructed entirely through interaction; a doing rather than a being. In this work, we distill some of these ideas for machine learning practitioners and introduce a theory of identity as autopoiesis, circular processes of formation and function. We argue that the default paradigm of identity used by the field immobilizes existing identity categories and the power differentials that co$\unicode{x2010}$occur, due to the absence of iterative feedback to our models. This includes a critique of emergent AI fairness practices that continue to impose the default paradigm. Finally, we apply our theory to sketch approaches to autopoietic identity through multilevel optimization and relational learning. While these ideas raise many open questions, we imagine the possibilities of machines that are capable of expressing human identity as a relationship perpetually in flux.