 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Space Response Oracles: Generating Interpretable Multi-Agent Policies with Large Language Models
Mar 10, 2026Recent advances in multi-agent reinforcement learning, particularly Policy-Space Response Oracles (PSRO), have enabled the computation of approximate game-theoretic equilibria in increasingly complex domains. However, these methods rely on deep reinforcement learning oracles that produce `black-box' neural network policies, making them difficult to interpret, trust or debug. We introduce Code-Space Response Oracles (CSRO), a novel framework that addresses this challenge by replacing RL oracles with Large Language Models (LLMs). CSRO reframes the best response computation as a code generation task, prompting an LLM to generate policies directly as human-readable code. This approach not only yields inherently interpretable policies but also leverages the LLM's pretrained knowledge to discover complex, human-like strategies. We explore multiple ways to construct and enhance an LLM-based oracle: zero-shot prompting, iterative refinement and \emph{AlphaEvolve}, a distributed LLM-based evolutionary system. We demonstrate that CSRO achieves performance competitive with baselines while producing a diverse set of explainable policies. Our work presents a new perspective on multi-agent learning, shifting the focus from optimizing opaque policy parameters to synthesizing interpretable algorithmic behavior.
A New Lower Bound for the Random Offerer Mechanism in Bilateral Trade using AI-Guided Evolutionary Search
Mar 09, 2026The celebrated Myerson--Satterthwaite theorem shows that in bilateral trade, no mechanism can be simultaneously fully efficient, Bayesian incentive compatible (BIC), and budget balanced (BB). This naturally raises the question of how closely the gains from trade (GFT) achievable by a BIC and BB mechanism can approximate the first-best (fully efficient) benchmark. The optimal BIC and BB mechanism is typically complex and highly distribution-dependent, making it difficult to characterize directly. Consequently, much of the literature analyzes simpler mechanisms such as the Random-Offerer (RO) mechanism and establishes constant-factor guarantees relative to the first-best GFT. An important open question concerns the worst-case performance of the RO mechanism relative to first-best (FB) efficiency. While it was originally hypothesized that the approximation ratio $\frac{\text{GFT}_{\text{FB}}}{\text{GFT}_{\text{RO}}}$ is bounded by $2$, recent work provided counterexamples to this conjecture: Cai et al. proved that the ratio can be strictly larger than $2$, and Babaioff et al. exhibited an explicit example with ratio approximately $2.02$. In this work, we employ AlphaEvolve, an AI-guided evolutionary search framework, to explore the space of value distributions. We identify a new worst-case instance that yields an improved lower bound of $\frac{\text{GFT}_{\text{FB}}}{\text{GFT}_{\text{RO}}} \ge \textbf{2.0749}$. This establishes a new lower bound on the worst-case performance of the Random-Offerer mechanism, demonstrating a wider efficiency gap than previously known.
Discovering Multiagent Learning Algorithms with Large Language Models
Feb 18, 2026Much of the advancement of Multi-Agent Reinforcement Learning (MARL) in imperfect-information games has historically depended on manual iterative refinement of baselines. While foundational families like Counterfactual Regret Minimization (CFR) and Policy Space Response Oracles (PSRO) rest on solid theoretical ground, the design of their most effective variants often relies on human intuition to navigate a vast algorithmic design space. In this work, we propose the use of AlphaEvolve, an evolutionary coding agent powered by large language models, to automatically discover new multiagent learning algorithms. We demonstrate the generality of this framework by evolving novel variants for two distinct paradigms of game-theoretic learning. First, in the domain of iterative regret minimization, we evolve the logic governing regret accumulation and policy derivation, discovering a new algorithm, Volatility-Adaptive Discounted (VAD-)CFR. VAD-CFR employs novel, non-intuitive mechanisms-including volatility-sensitive discounting, consistency-enforced optimism, and a hard warm-start policy accumulation schedule-to outperform state-of-the-art baselines like Discounted Predictive CFR+. Second, in the regime of population based training algorithms, we evolve training-time and evaluation-time meta strategy solvers for PSRO, discovering a new variant, Smoothed Hybrid Optimistic Regret (SHOR-)PSRO. SHOR-PSRO introduces a hybrid meta-solver that linearly blends Optimistic Regret Matching with a smoothed, temperature-controlled distribution over best pure strategies. By dynamically annealing this blending factor and diversity bonuses during training, the algorithm automates the transition from population diversity to rigorous equilibrium finding, yielding superior empirical convergence compared to standard static meta-solvers.
Code World Models for General Game Playing
Oct 06, 2025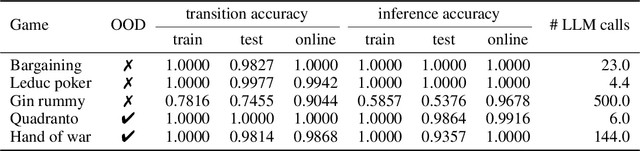

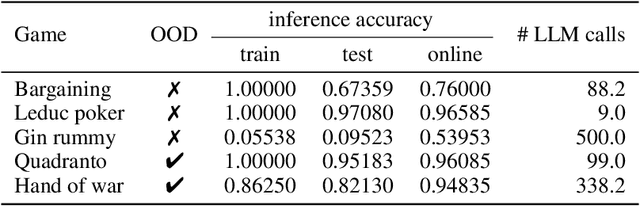
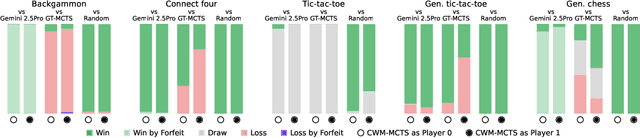
Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
Evaluating Agents using Social Choice Theory
Dec 07, 2023

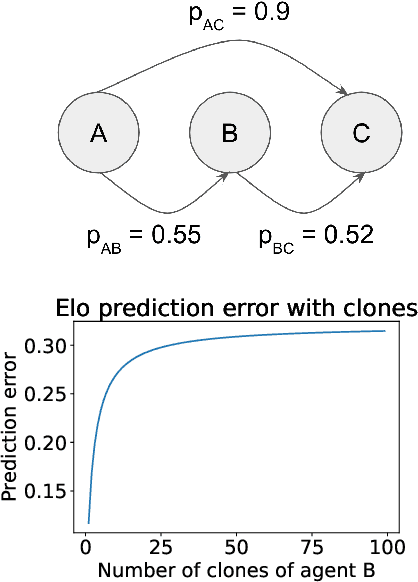

We argue that many general evaluation problems can be viewed through the lens of voting theory. Each task is interpreted as a separate voter, which requires only ordinal rankings or pairwise comparisons of agents to produce an overall evaluation. By viewing the aggregator as a social welfare function, we are able to leverage centuries of research in social choice theory to derive principled evaluation frameworks with axiomatic foundations. These evaluations are interpretable and flexible, while avoiding many of the problems currently facing cross-task evaluation. We apply this Voting-as-Evaluation (VasE) framework across multiple settings, including reinforcement learning, large language models, and humans. In practice, we observe that VasE can be more robust than popular evaluation frameworks (Elo and Nash averaging), discovers properties in the evaluation data not evident from scores alone, and can predict outcomes better than Elo in a complex seven-player game. We identify one particular approach, maximal lotteries, that satisfies important consistency properties relevant to evaluation, is computationally efficient (polynomial in the size of the evaluation data), and identifies game-theoretic cycles.
Knowledge Augmented Relation Inference for Group Activity Recognition
Mar 01, 2023



Most existing group activity recognition methods construct spatial-temporal relations merely based on visual representation. Some methods introduce extra knowledge, such as action labels, to build semantic relations and use them to refine the visual presentation. However, the knowledge they explored just stay at the semantic-level, which is insufficient for pursing notable accuracy. In this paper, we propose to exploit knowledge concretization for the group activity recognition, and develop a novel Knowledge Augmented Relation Inference framework that can effectively use the concretized knowledge to improve the individual representations. Specifically, the framework consists of a Visual Representation Module to extract individual appearance features, a Knowledge Augmented Semantic Relation Module explore semantic representations of individual actions, and a Knowledge-Semantic-Visual Interaction Module aims to integrate visual and semantic information by the knowledge. Benefiting from these modules, the proposed framework can utilize knowledge to enhance the relation inference process and the individual representations, thus improving the performance of group activity recognition. Experimental results on two public datasets show that the proposed framework achieves competitive performance compared with state-of-the-art methods.
Combining Tree-Search, Generative Models, and Nash Bargaining Concepts in Game-Theoretic Reinforcement Learning
Feb 01, 2023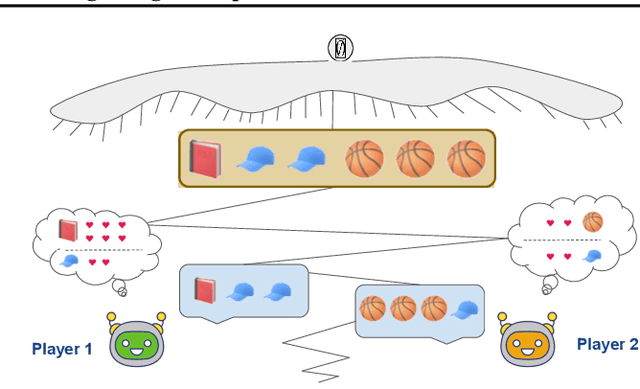
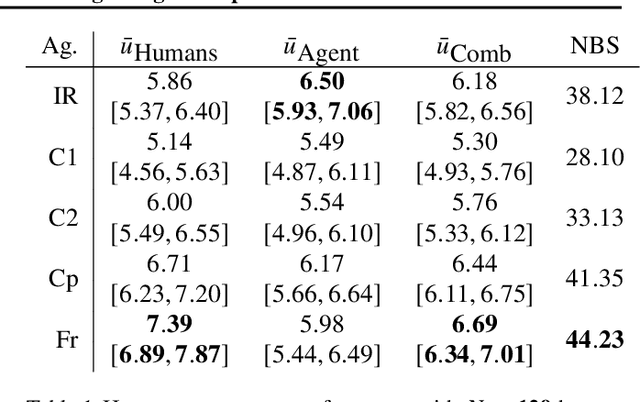
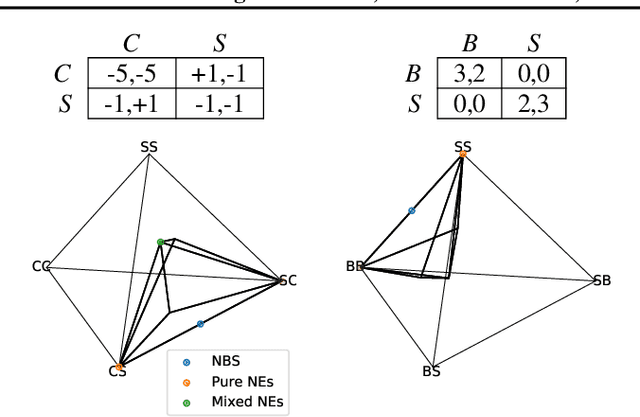
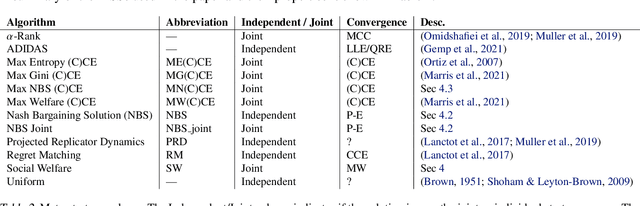
Multiagent reinforcement learning (MARL) has benefited significantly from population-based and game-theoretic training regimes. One approach, Policy-Space Response Oracles (PSRO), employs standard reinforcement learning to compute response policies via approximate best responses and combines them via meta-strategy selection. We augment PSRO by adding a novel search procedure with generative sampling of world states, and introduce two new meta-strategy solvers based on the Nash bargaining solution. We evaluate PSRO's ability to compute approximate Nash equilibrium, and its performance in two negotiation games: Colored Trails, and Deal or No Deal. We conduct behavioral studies where human participants negotiate with our agents ($N = 346$). We find that search with generative modeling finds stronger policies during both training time and test time, enables online Bayesian co-player prediction, and can produce agents that achieve comparable social welfare negotiating with humans as humans trading among themselves.
A Universal Model for Cross Modality Mapping by Relational Reasoning
Feb 26, 2021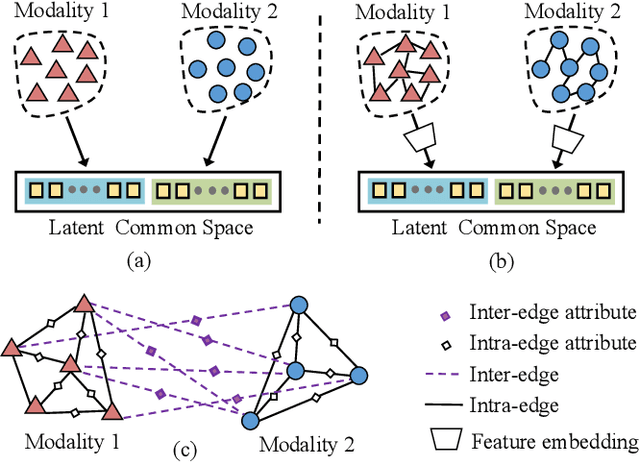
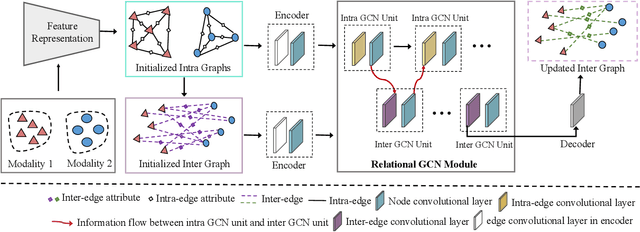
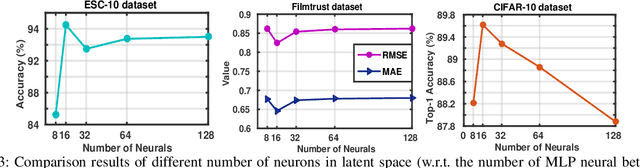
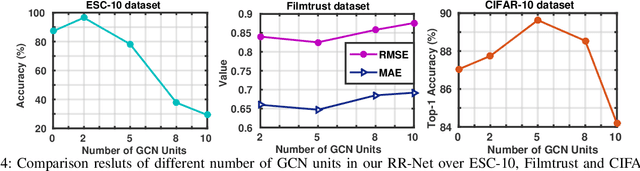
With the aim of matching a pair of instances from two different modalities, cross modality mapping has attracted growing attention in the computer vision community. Existing methods usually formulate the mapping function as the similarity measure between the pair of instance features, which are embedded to a common space. However, we observe that the relationships among the instances within a single modality (intra relations) and those between the pair of heterogeneous instances (inter relations) are insufficiently explored in previous approaches. Motivated by this, we redefine the mapping function with relational reasoning via graph modeling, and further propose a GCN-based Relational Reasoning Network (RR-Net) in which inter and intra relations are efficiently computed to universally resolve the cross modality mapping problem. Concretely, we first construct two kinds of graph, i.e., Intra Graph and Inter Graph, to respectively model intra relations and inter relations. Then RR-Net updates all the node features and edge features in an iterative manner for learning intra and inter relations simultaneously. Last, RR-Net outputs the probabilities over the edges which link a pair of heterogeneous instances to estimate the mapping results. Extensive experiments on three example tasks, i.e., image classification, social recommendation and sound recognition, clearly demonstrate the superiority and universality of our proposed model.
Multi-Miner: Object-Adaptive Region Mining for Weakly-Supervised Semantic Segmentation
Jun 14, 2020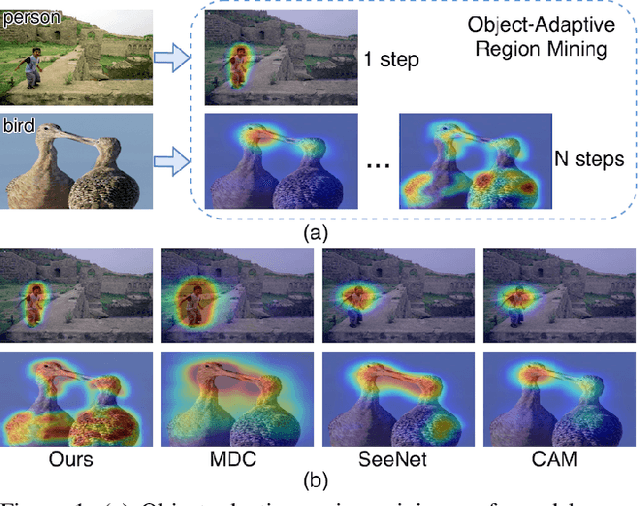
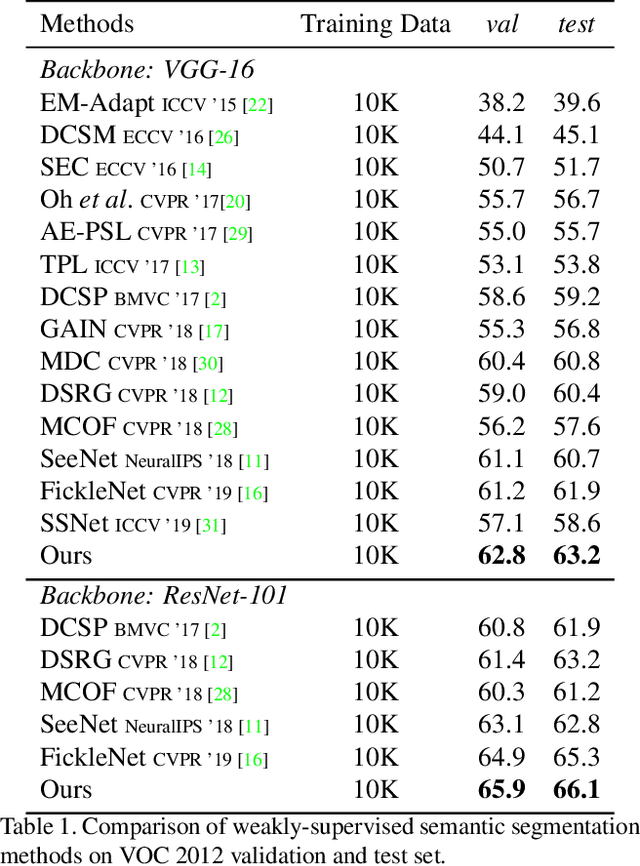
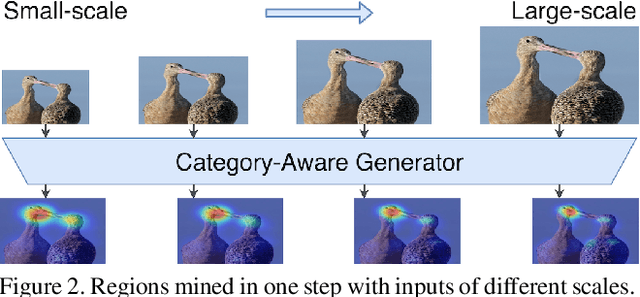

Object region mining is a critical step for weakly-supervised semantic segmentation. Most recent methods mine the object regions by expanding the seed regions localized by class activation maps. They generally do not consider the sizes of objects and apply a monotonous procedure to mining all the object regions. Thus their mined regions are often insufficient in number and scale for large objects, and on the other hand easily contaminated by surrounding backgrounds for small objects. In this paper, we propose a novel multi-miner framework to perform a region mining process that adapts to diverse object sizes and is thus able to mine more integral and finer object regions. Specifically, our multi-miner leverages a parallel modulator to check whether there are remaining object regions for each single object, and guide a category-aware generator to mine the regions of each object independently. In this way, the multi-miner adaptively takes more steps for large objects and fewer steps for small objects. Experiment results demonstrate that the multi-miner offers better region mining results and helps achieve better segmentation performance than state-of-the-art weakly-supervised semantic segmentation methods.
Cross-layer Feature Pyramid Network for Salient Object Detection
Feb 25, 2020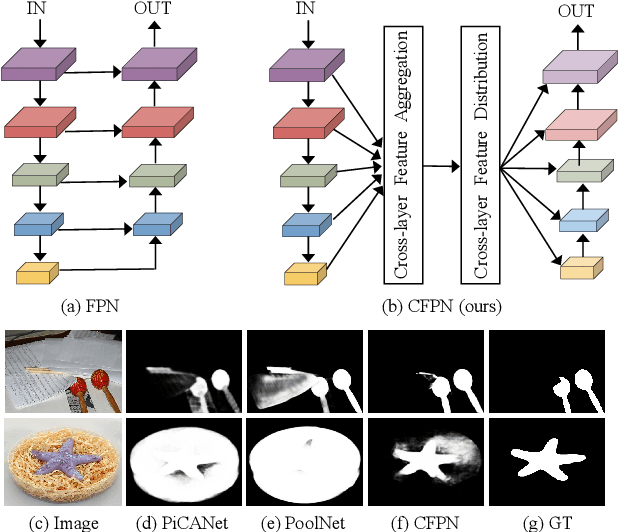
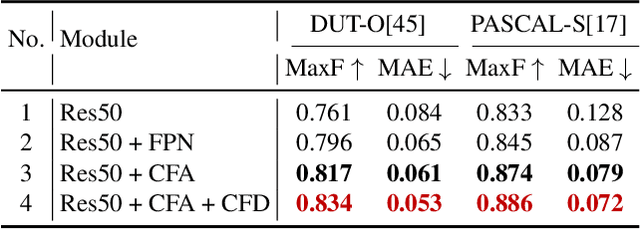
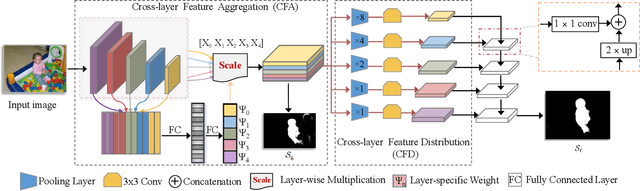

Feature pyramid network (FPN) based models, which fuse the semantics and salient details in a progressive manner, have been proven highly effective in salient object detection. However, it is observed that these models often generate saliency maps with incomplete object structures or unclear object boundaries, due to the \emph{indirect} information propagation among distant layers that makes such fusion structure less effective. In this work, we propose a novel Cross-layer Feature Pyramid Network (CFPN), in which direct cross-layer communication is enabled to improve the progressive fusion in salient object detection. Specifically, the proposed network first aggregates multi-scale features from different layers into feature maps that have access to both the high- and low-level information. Then, it distributes the aggregated features to all the involved layers to gain access to richer context. In this way, the distributed features per layer own both semantics and salient details from all other layers simultaneously, and suffer reduced loss of important information. Extensive experimental results over six widely used salient object detection benchmarks and with three popular backbones clearly demonstrate that CFPN can accurately locate fairly complete salient regions and effectively segment the object boundaries.