 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePepBenchmark: A Standardized Benchmark for Peptide Machine Learning
Apr 12, 2026Peptide therapeutics are widely regarded as the "third generation" of drugs, yet progress in peptide Machine Learning (ML) are hindered by the absence of standardized benchmarks. Here we present PepBenchmark, which unifies datasets, preprocessing, and evaluation protocols for peptide drug discovery. PepBenchmark comprises three components: (1) PepBenchData, a well-curated collection comprising 29 canonical-peptide and 6 non-canonical-peptide datasets across 7 groups, systematically covering key aspects of peptide drug development, representing, to the best of our knowledge, the most comprehensive AI-ready dataset resource to date; (2) PepBenchPipeline, a standardized preprocessing pipeline that ensures consistent dataset cleaning, construction, splitting, and feature transformation, mitigating quality issues common in ad hoc pipelines; and (3) PepBenchLeaderboard, a unified evaluation protocol and leaderboard with strong baselines across 4 major methodological families: Fingerprint-based, GNN-based, PLM-based, and SMILES-based models. Together, PepBenchmark provides the first standardized and comparable foundation for peptide drug discovery, facilitating methodological advances and translation into real-world applications. The data and code are publicly available at https://github.com/ZGCI-AI4S-Pep/PepBenchmark/.
Reachability-Aware Laplacian Representation in Reinforcement Learning
Oct 24, 2022



In Reinforcement Learning (RL), Laplacian Representation (LapRep) is a task-agnostic state representation that encodes the geometry of the environment. A desirable property of LapRep stated in prior works is that the Euclidean distance in the LapRep space roughly reflects the reachability between states, which motivates the usage of this distance for reward shaping. However, we find that LapRep does not necessarily have this property in general: two states having small distance under LapRep can actually be far away in the environment. Such mismatch would impede the learning process in reward shaping. To fix this issue, we introduce a Reachability-Aware Laplacian Representation (RA-LapRep), by properly scaling each dimension of LapRep. Despite the simplicity, we demonstrate that RA-LapRep can better capture the inter-state reachability as compared to LapRep, through both theoretical explanations and experimental results. Additionally, we show that this improvement yields a significant boost in reward shaping performance and also benefits bottleneck state discovery.
Online Learning for Non-monotone Submodular Maximization: From Full Information to Bandit Feedback
Aug 16, 2022

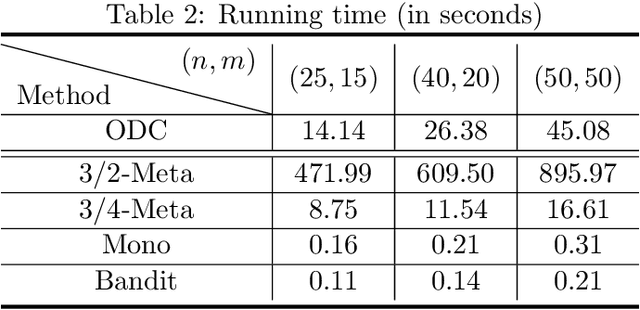
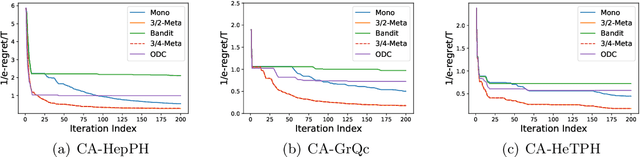
In this paper, we revisit the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, which finds wide real-world applications in the domain of machine learning, economics, and operations research. At first, we present the Meta-MFW algorithm achieving a $1/e$-regret of $O(\sqrt{T})$ at the cost of $T^{3/2}$ stochastic gradient evaluations per round. As far as we know, Meta-MFW is the first algorithm to obtain $1/e$-regret of $O(\sqrt{T})$ for the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set. Furthermore, in sharp contrast with ODC algorithm \citep{thang2021online}, Meta-MFW relies on the simple online linear oracle without discretization, lifting, or rounding operations. Considering the practical restrictions, we then propose the Mono-MFW algorithm, which reduces the per-function stochastic gradient evaluations from $T^{3/2}$ to 1 and achieves a $1/e$-regret bound of $O(T^{4/5})$. Next, we extend Mono-MFW to the bandit setting and propose the Bandit-MFW algorithm which attains a $1/e$-regret bound of $O(T^{8/9})$. To the best of our knowledge, Mono-MFW and Bandit-MFW are the first sublinear-regret algorithms to explore the one-shot and bandit setting for online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, respectively. Finally, we conduct numerical experiments on both synthetic and real-world datasets to verify the effectiveness of our methods.
Tyger: Task-Type-Generic Active Learning for Molecular Property Prediction
May 23, 2022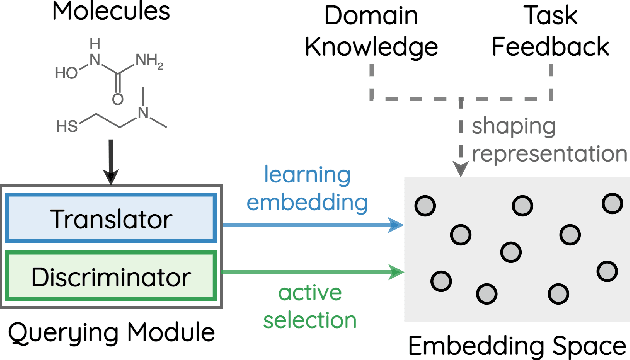
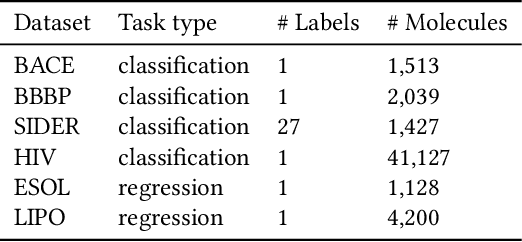
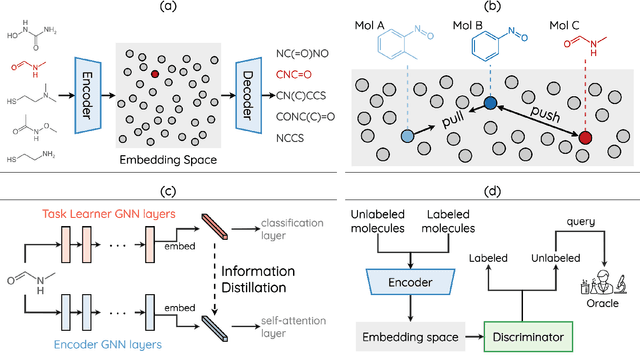
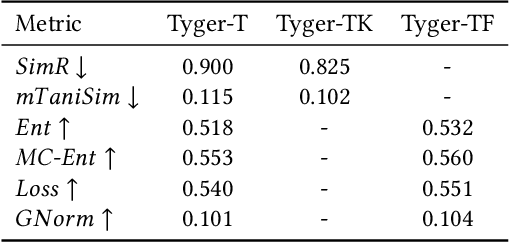
How to accurately predict the properties of molecules is an essential problem in AI-driven drug discovery, which generally requires a large amount of annotation for training deep learning models. Annotating molecules, however, is quite costly because it requires lab experiments conducted by experts. To reduce annotation cost, deep Active Learning (AL) methods are developed to select only the most representative and informative data for annotating. However, existing best deep AL methods are mostly developed for a single type of learning task (e.g., single-label classification), and hence may not perform well in molecular property prediction that involves various task types. In this paper, we propose a Task-type-generic active learning framework (termed Tyger) that is able to handle different types of learning tasks in a unified manner. The key is to learn a chemically-meaningful embedding space and perform active selection fully based on the embeddings, instead of relying on task-type-specific heuristics (e.g., class-wise prediction probability) as done in existing works. Specifically, for learning the embedding space, we instantiate a querying module that learns to translate molecule graphs into corresponding SMILES strings. Furthermore, to ensure that samples selected from the space are both representative and informative, we propose to shape the embedding space by two learning objectives, one based on domain knowledge and the other leveraging feedback from the task learner (i.e., model that performs the learning task at hand). We conduct extensive experiments on benchmark datasets of different task types. Experimental results show that Tyger consistently achieves high AL performance on molecular property prediction, outperforming baselines by a large margin. We also perform ablative experiments to verify the effectiveness of each component in Tyger.
The Geometry of Robust Value Functions
Jan 30, 2022
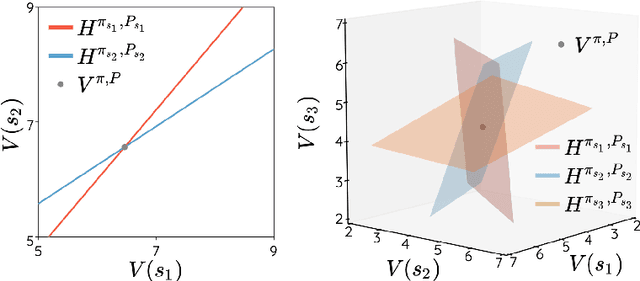

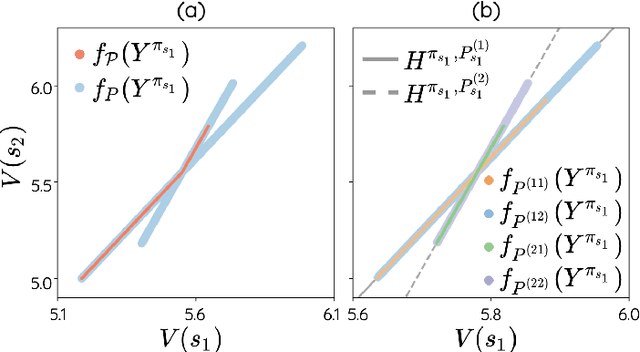
The space of value functions is a fundamental concept in reinforcement learning. Characterizing its geometric properties may provide insights for optimization and representation. Existing works mainly focus on the value space for Markov Decision Processes (MDPs). In this paper, we study the geometry of the robust value space for the more general Robust MDPs (RMDPs) setting, where transition uncertainties are considered. Specifically, since we find it hard to directly adapt prior approaches to RMDPs, we start with revisiting the non-robust case, and introduce a new perspective that enables us to characterize both the non-robust and robust value space in a similar fashion. The key of this perspective is to decompose the value space, in a state-wise manner, into unions of hypersurfaces. Through our analysis, we show that the robust value space is determined by a set of conic hypersurfaces, each of which contains the robust values of all policies that agree on one state. Furthermore, we find that taking only extreme points in the uncertainty set is sufficient to determine the robust value space. Finally, we discuss some other aspects about the robust value space, including its non-convexity and policy agreement on multiple states.
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
Jan 03, 2022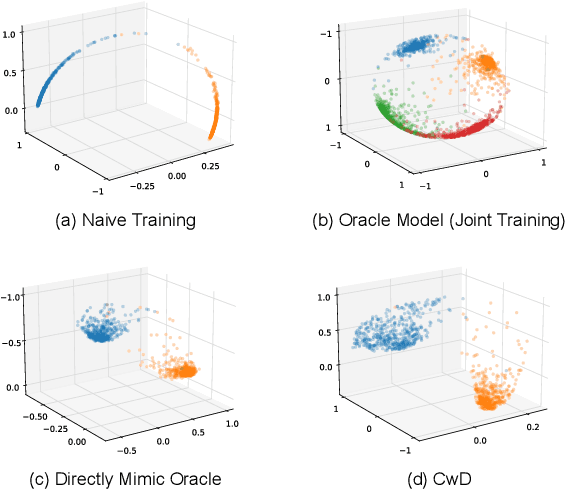
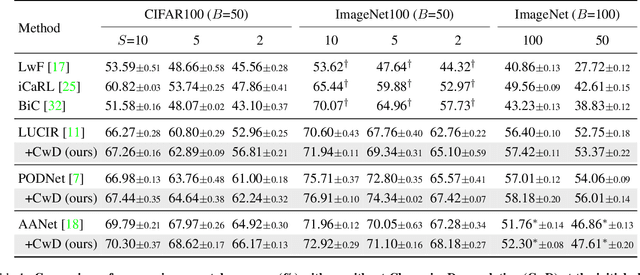
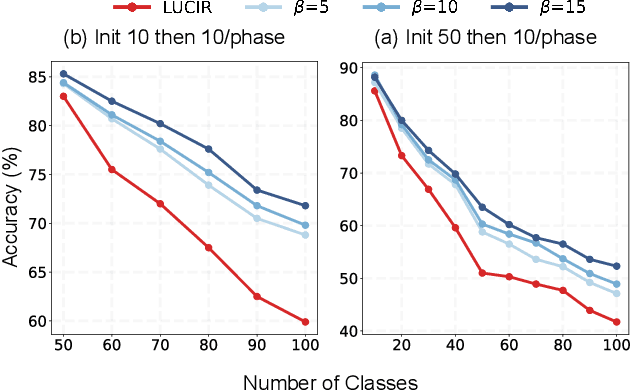
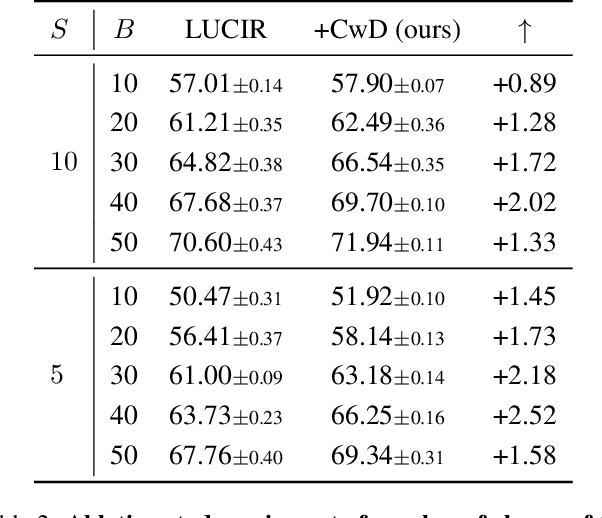
Class Incremental Learning (CIL) aims at learning a multi-class classifier in a phase-by-phase manner, in which only data of a subset of the classes are provided at each phase. Previous works mainly focus on mitigating forgetting in phases after the initial one. However, we find that improving CIL at its initial phase is also a promising direction. Specifically, we experimentally show that directly encouraging CIL Learner at the initial phase to output similar representations as the model jointly trained on all classes can greatly boost the CIL performance. Motivated by this, we study the difference between a na\"ively-trained initial-phase model and the oracle model. Specifically, since one major difference between these two models is the number of training classes, we investigate how such difference affects the model representations. We find that, with fewer training classes, the data representations of each class lie in a long and narrow region; with more training classes, the representations of each class scatter more uniformly. Inspired by this observation, we propose Class-wise Decorrelation (CwD) that effectively regularizes representations of each class to scatter more uniformly, thus mimicking the model jointly trained with all classes (i.e., the oracle model). Our CwD is simple to implement and easy to plug into existing methods. Extensive experiments on various benchmark datasets show that CwD consistently and significantly improves the performance of existing state-of-the-art methods by around 1\% to 3\%. Code will be released.
Towards Better Laplacian Representation in Reinforcement Learning with Generalized Graph Drawing
Jul 12, 2021

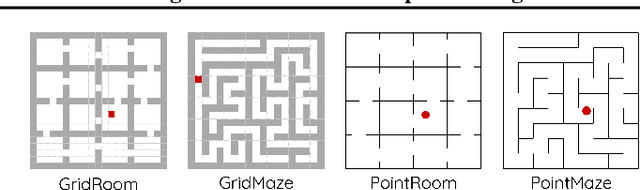
The Laplacian representation recently gains increasing attention for reinforcement learning as it provides succinct and informative representation for states, by taking the eigenvectors of the Laplacian matrix of the state-transition graph as state embeddings. Such representation captures the geometry of the underlying state space and is beneficial to RL tasks such as option discovery and reward shaping. To approximate the Laplacian representation in large (or even continuous) state spaces, recent works propose to minimize a spectral graph drawing objective, which however has infinitely many global minimizers other than the eigenvectors. As a result, their learned Laplacian representation may differ from the ground truth. To solve this problem, we reformulate the graph drawing objective into a generalized form and derive a new learning objective, which is proved to have eigenvectors as its unique global minimizer. It enables learning high-quality Laplacian representations that faithfully approximate the ground truth. We validate this via comprehensive experiments on a set of gridworld and continuous control environments. Moreover, we show that our learned Laplacian representations lead to more exploratory options and better reward shaping.
Few-shot Classification via Adaptive Attention
Aug 06, 2020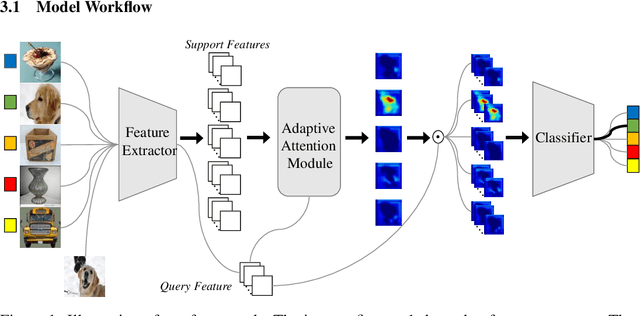
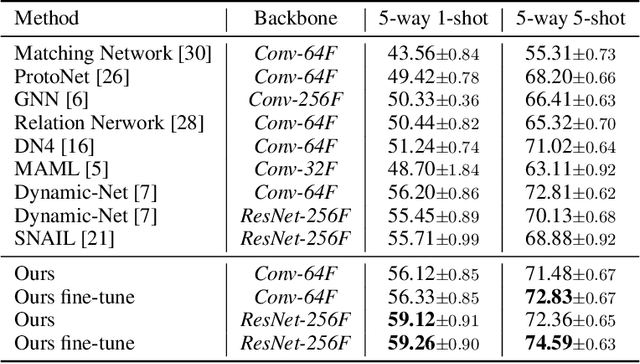
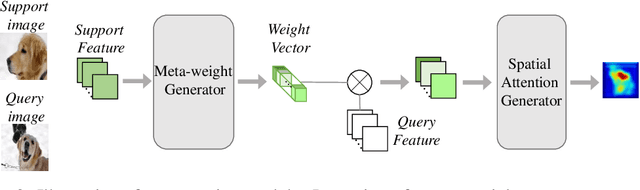

Training a neural network model that can quickly adapt to a new task is highly desirable yet challenging for few-shot learning problems. Recent few-shot learning methods mostly concentrate on developing various meta-learning strategies from two aspects, namely optimizing an initial model or learning a distance metric. In this work, we propose a novel few-shot learning method via optimizing and fast adapting the query sample representation based on very few reference samples. To be specific, we devise a simple and efficient meta-reweighting strategy to adapt the sample representations and generate soft attention to refine the representation such that the relevant features from the query and support samples can be extracted for a better few-shot classification. Such an adaptive attention model is also able to explain what the classification model is looking for as the evidence for classification to some extent. As demonstrated experimentally, the proposed model achieves state-of-the-art classification results on various benchmark few-shot classification and fine-grained recognition datasets.
Multi-Miner: Object-Adaptive Region Mining for Weakly-Supervised Semantic Segmentation
Jun 14, 2020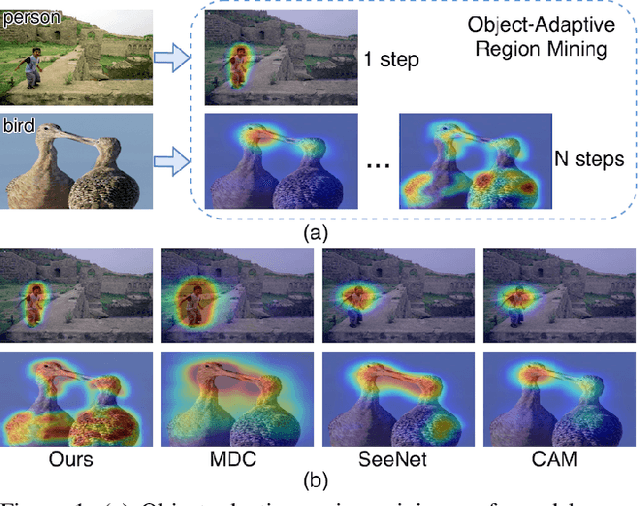
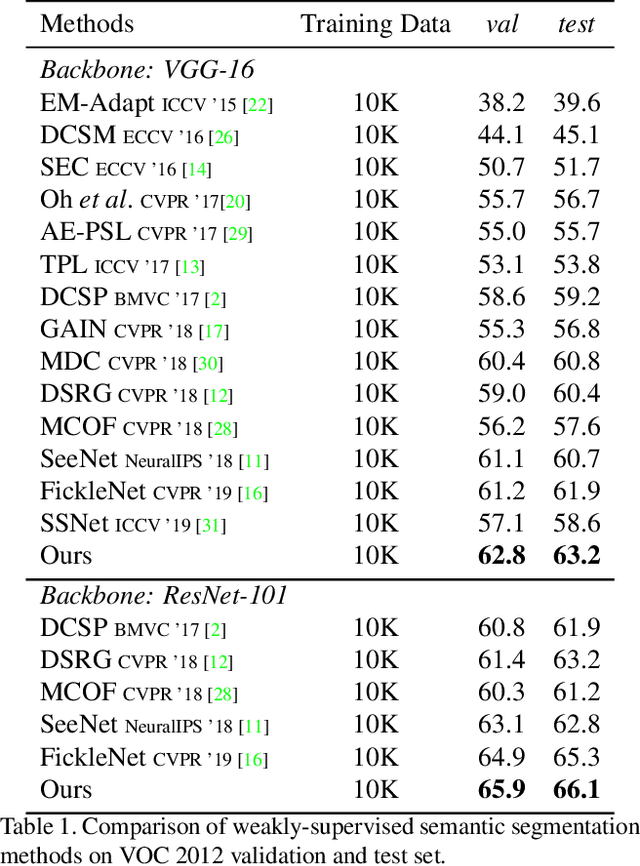
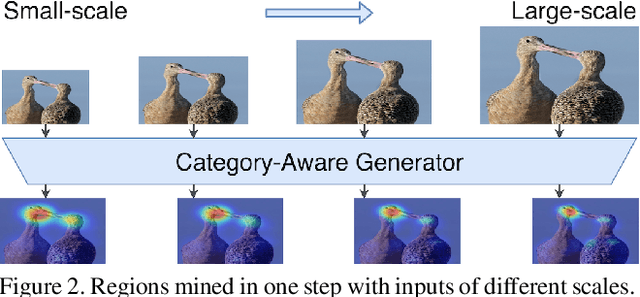

Object region mining is a critical step for weakly-supervised semantic segmentation. Most recent methods mine the object regions by expanding the seed regions localized by class activation maps. They generally do not consider the sizes of objects and apply a monotonous procedure to mining all the object regions. Thus their mined regions are often insufficient in number and scale for large objects, and on the other hand easily contaminated by surrounding backgrounds for small objects. In this paper, we propose a novel multi-miner framework to perform a region mining process that adapts to diverse object sizes and is thus able to mine more integral and finer object regions. Specifically, our multi-miner leverages a parallel modulator to check whether there are remaining object regions for each single object, and guide a category-aware generator to mine the regions of each object independently. In this way, the multi-miner adaptively takes more steps for large objects and fewer steps for small objects. Experiment results demonstrate that the multi-miner offers better region mining results and helps achieve better segmentation performance than state-of-the-art weakly-supervised semantic segmentation methods.
Effective Training Strategies for Deep Graph Neural Networks
Jun 12, 2020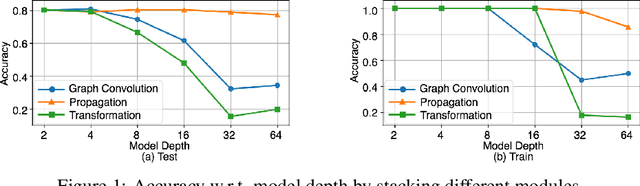
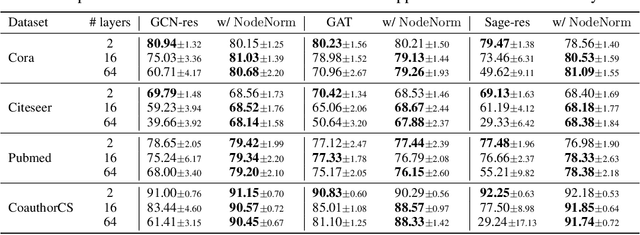
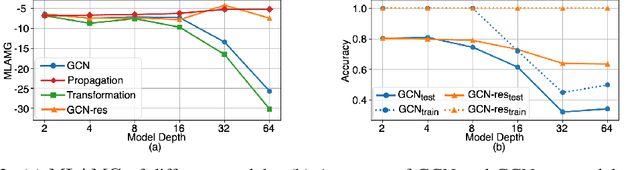
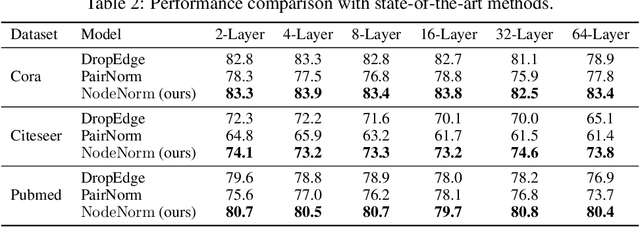
Graph Neural Networks (GNNs) tend to suffer performance degradation as model depth increases, which is usually attributed in previous works to the oversmoothing problem. However, we find that although oversmoothing is a contributing factor, the main reasons for this phenomenon are training difficulty and overfitting, which we study by experimentally investigating Graph Convolutional Networks (GCNs), a representative GNN architecture. We find that training difficulty is caused by gradient vanishing and can be solved by adding residual connections. More importantly, overfitting is the major obstacle for deep GCNs and cannot be effectively solved by existing regularization techniques. Deep GCNs also suffer training instability, which slows down the training process. To address overfitting and training instability, we propose Node Normalization (NodeNorm), which normalizes each node using its own statistics in model training. The proposed NodeNorm regularizes deep GCNs by discouraging feature-wise correlation of hidden embeddings and increasing model smoothness with respect to input node features, and thus effectively reduces overfitting. Additionally, it stabilizes the training process and hence speeds up the training. Extensive experiments demonstrate that our NodeNorm method generalizes well to other GNN architectures, enabling deep GNNs to compete with and even outperform shallow ones. Code is publicly available.