 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning for Non-monotone Submodular Maximization: From Full Information to Bandit Feedback
Paper and Code
Aug 16, 2022

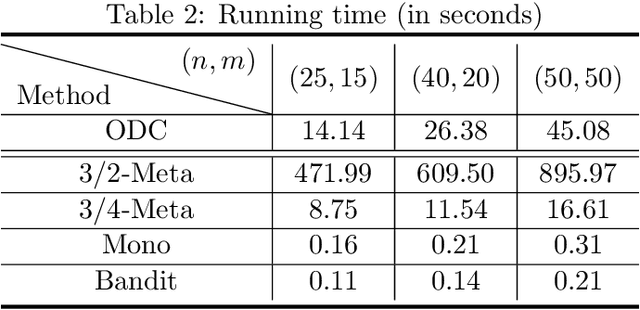
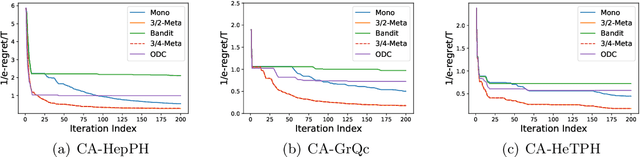
In this paper, we revisit the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, which finds wide real-world applications in the domain of machine learning, economics, and operations research. At first, we present the Meta-MFW algorithm achieving a $1/e$-regret of $O(\sqrt{T})$ at the cost of $T^{3/2}$ stochastic gradient evaluations per round. As far as we know, Meta-MFW is the first algorithm to obtain $1/e$-regret of $O(\sqrt{T})$ for the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set. Furthermore, in sharp contrast with ODC algorithm \citep{thang2021online}, Meta-MFW relies on the simple online linear oracle without discretization, lifting, or rounding operations. Considering the practical restrictions, we then propose the Mono-MFW algorithm, which reduces the per-function stochastic gradient evaluations from $T^{3/2}$ to 1 and achieves a $1/e$-regret bound of $O(T^{4/5})$. Next, we extend Mono-MFW to the bandit setting and propose the Bandit-MFW algorithm which attains a $1/e$-regret bound of $O(T^{8/9})$. To the best of our knowledge, Mono-MFW and Bandit-MFW are the first sublinear-regret algorithms to explore the one-shot and bandit setting for online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, respectively. Finally, we conduct numerical experiments on both synthetic and real-world datasets to verify the effectiveness of our methods.