 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Agents using Social Choice Theory
Dec 07, 2023

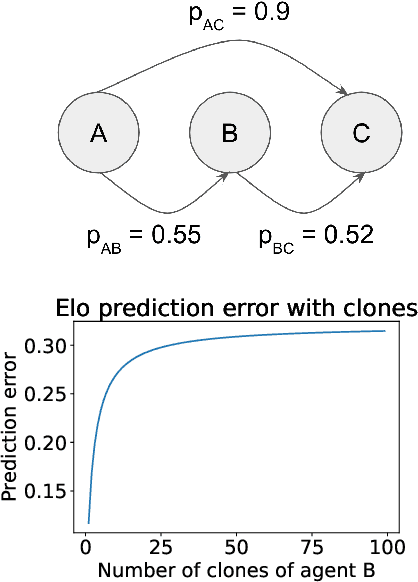

We argue that many general evaluation problems can be viewed through the lens of voting theory. Each task is interpreted as a separate voter, which requires only ordinal rankings or pairwise comparisons of agents to produce an overall evaluation. By viewing the aggregator as a social welfare function, we are able to leverage centuries of research in social choice theory to derive principled evaluation frameworks with axiomatic foundations. These evaluations are interpretable and flexible, while avoiding many of the problems currently facing cross-task evaluation. We apply this Voting-as-Evaluation (VasE) framework across multiple settings, including reinforcement learning, large language models, and humans. In practice, we observe that VasE can be more robust than popular evaluation frameworks (Elo and Nash averaging), discovers properties in the evaluation data not evident from scores alone, and can predict outcomes better than Elo in a complex seven-player game. We identify one particular approach, maximal lotteries, that satisfies important consistency properties relevant to evaluation, is computationally efficient (polynomial in the size of the evaluation data), and identifies game-theoretic cycles.
Reward-Respecting Subtasks for Model-Based Reinforcement Learning
Feb 09, 2022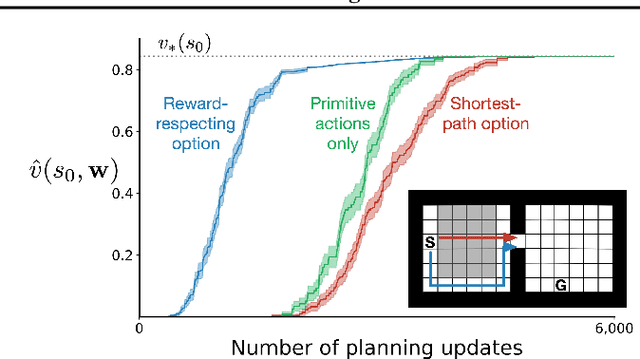
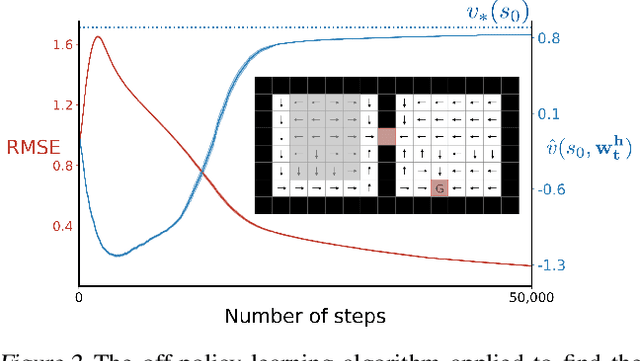
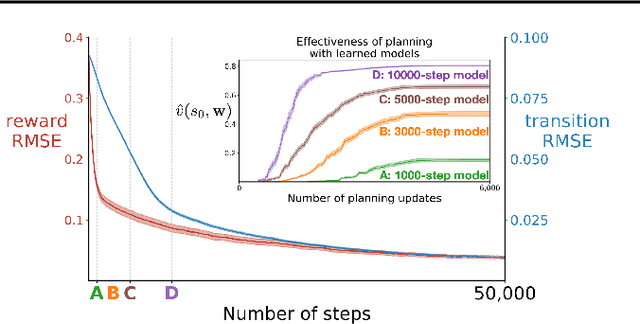
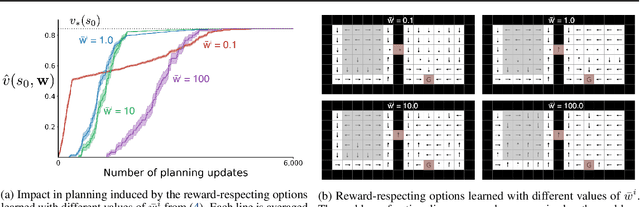
To achieve the ambitious goals of artificial intelligence, reinforcement learning must include planning with a model of the world that is abstract in state and time. Deep learning has made progress in state abstraction, but, although the theory of time abstraction has been extensively developed based on the options framework, in practice options have rarely been used in planning. One reason for this is that the space of possible options is immense and the methods previously proposed for option discovery do not take into account how the option models will be used in planning. Options are typically discovered by posing subsidiary tasks such as reaching a bottleneck state, or maximizing a sensory signal other than the reward. Each subtask is solved to produce an option, and then a model of the option is learned and made available to the planning process. The subtasks proposed in most previous work ignore the reward on the original problem, whereas we propose subtasks that use the original reward plus a bonus based on a feature of the state at the time the option stops. We show that options and option models obtained from such reward-respecting subtasks are much more likely to be useful in planning and can be learned online and off-policy using existing learning algorithms. Reward respecting subtasks strongly constrain the space of options and thereby also provide a partial solution to the problem of option discovery. Finally, we show how the algorithms for learning values, policies, options, and models can be unified using general value functions.
Temporal-Difference Networks
Apr 21, 2015



We introduce a generalization of temporal-difference (TD) learning to networks of interrelated predictions. Rather than relating a single prediction to itself at a later time, as in conventional TD methods, a TD network relates each prediction in a set of predictions to other predictions in the set at a later time. TD networks can represent and apply TD learning to a much wider class of predictions than has previously been possible. Using a random-walk example, we show that these networks can be used to learn to predict by a fixed interval, which is not possible with conventional TD methods. Secondly, we show that if the inter-predictive relationships are made conditional on action, then the usual learning-efficiency advantage of TD methods over Monte Carlo (supervised learning) methods becomes particularly pronounced. Thirdly, we demonstrate that TD networks can learn predictive state representations that enable exact solution of a non-Markov problem. A very broad range of inter-predictive temporal relationships can be expressed in these networks. Overall we argue that TD networks represent a substantial extension of the abilities of TD methods and bring us closer to the goal of representing world knowledge in entirely predictive, grounded terms.