 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024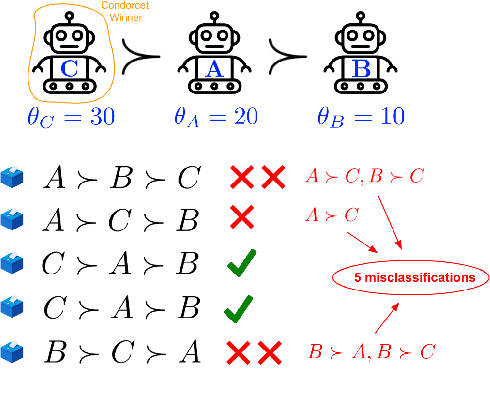
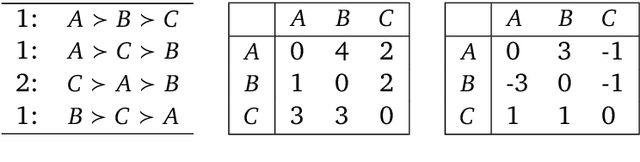
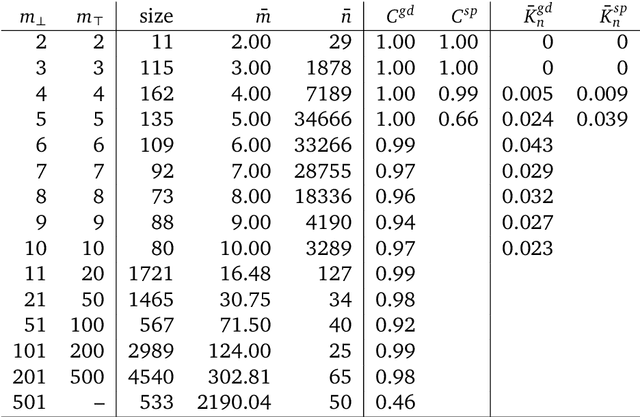
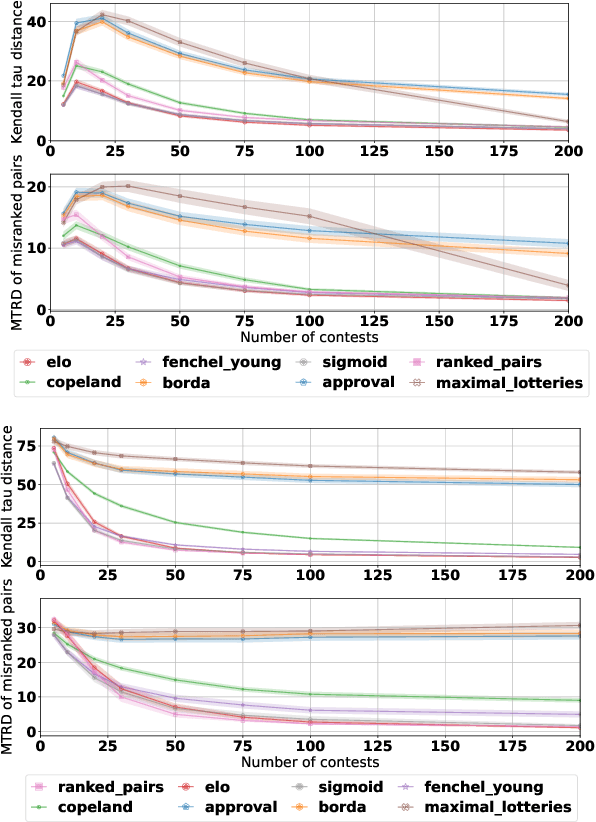
A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Evaluating Agents using Social Choice Theory
Dec 07, 2023

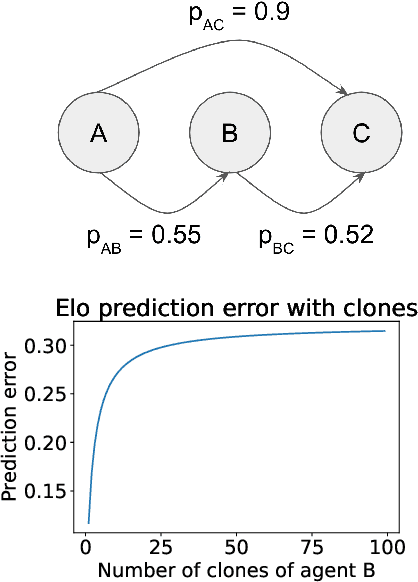

We argue that many general evaluation problems can be viewed through the lens of voting theory. Each task is interpreted as a separate voter, which requires only ordinal rankings or pairwise comparisons of agents to produce an overall evaluation. By viewing the aggregator as a social welfare function, we are able to leverage centuries of research in social choice theory to derive principled evaluation frameworks with axiomatic foundations. These evaluations are interpretable and flexible, while avoiding many of the problems currently facing cross-task evaluation. We apply this Voting-as-Evaluation (VasE) framework across multiple settings, including reinforcement learning, large language models, and humans. In practice, we observe that VasE can be more robust than popular evaluation frameworks (Elo and Nash averaging), discovers properties in the evaluation data not evident from scores alone, and can predict outcomes better than Elo in a complex seven-player game. We identify one particular approach, maximal lotteries, that satisfies important consistency properties relevant to evaluation, is computationally efficient (polynomial in the size of the evaluation data), and identifies game-theoretic cycles.
What Should I Know? Using Meta-gradient Descent for Predictive Feature Discovery in a Single Stream of Experience
Jun 13, 2022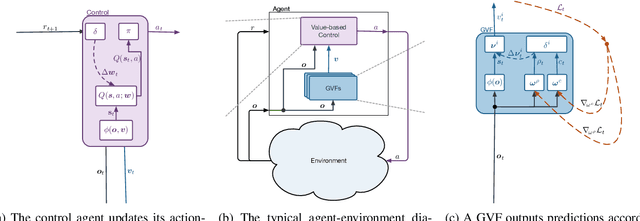
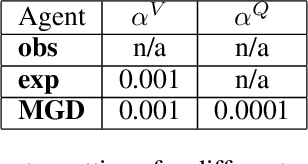
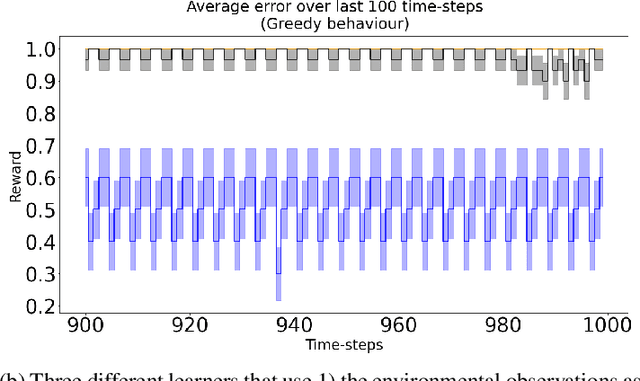
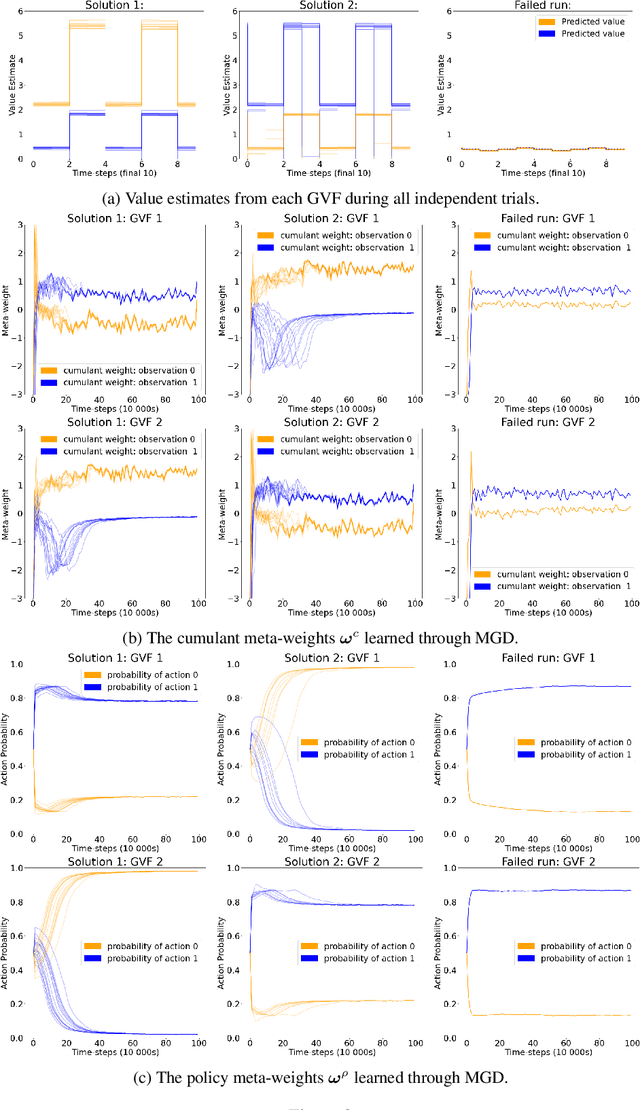
In computational reinforcement learning, a growing body of work seeks to construct an agent's perception of the world through predictions of future sensations; predictions about environment observations are used as additional input features to enable better goal-directed decision-making. An open challenge in this line of work is determining from the infinitely many predictions that the agent could possibly make which predictions might best support decision-making. This challenge is especially apparent in continual learning problems where a single stream of experience is available to a singular agent. As a primary contribution, we introduce a meta-gradient descent process by which an agent learns 1) what predictions to make, 2) the estimates for its chosen predictions, and 3) how to use those estimates to generate policies that maximize future reward -- all during a single ongoing process of continual learning. In this manuscript we consider predictions expressed as General Value Functions: temporally extended estimates of the accumulation of a future signal. We demonstrate that through interaction with the environment an agent can independently select predictions that resolve partial-observability, resulting in performance similar to expertly specified GVFs. By learning, rather than manually specifying these predictions, we enable the agent to identify useful predictions in a self-supervised manner, taking a step towards truly autonomous systems.
Should Models Be Accurate?
May 22, 2022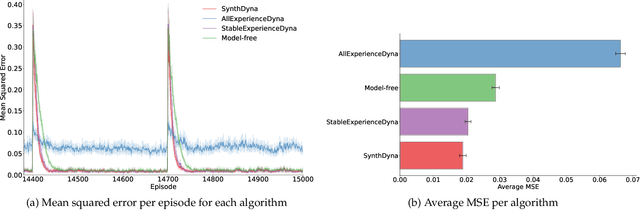
Model-based Reinforcement Learning (MBRL) holds promise for data-efficiency by planning with model-generated experience in addition to learning with experience from the environment. However, in complex or changing environments, models in MBRL will inevitably be imperfect, and their detrimental effects on learning can be difficult to mitigate. In this work, we question whether the objective of these models should be the accurate simulation of environment dynamics at all. We focus our investigations on Dyna-style planning in a prediction setting. First, we highlight and support three motivating points: a perfectly accurate model of environment dynamics is not practically achievable, is not necessary, and is not always the most useful anyways. Second, we introduce a meta-learning algorithm for training models with a focus on their usefulness to the learner instead of their accuracy in modelling the environment. Our experiments show that in a simple non-stationary environment, our algorithm enables faster learning than even using an accurate model built with domain-specific knowledge of the non-stationarity.
Finding Useful Predictions by Meta-gradient Descent to Improve Decision-making
Nov 18, 2021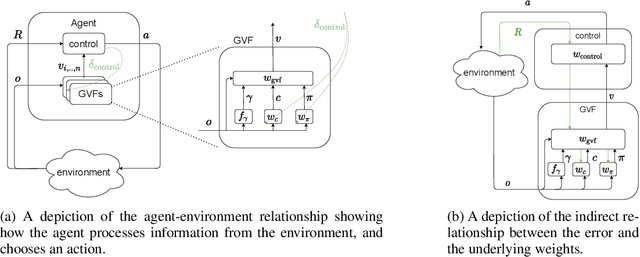

In computational reinforcement learning, a growing body of work seeks to express an agent's model of the world through predictions about future sensations. In this manuscript we focus on predictions expressed as General Value Functions: temporally extended estimates of the accumulation of a future signal. One challenge is determining from the infinitely many predictions that the agent could possibly make which might support decision-making. In this work, we contribute a meta-gradient descent method by which an agent can directly specify what predictions it learns, independent of designer instruction. To that end, we introduce a partially observable domain suited to this investigation. We then demonstrate that through interaction with the environment an agent can independently select predictions that resolve the partial-observability, resulting in performance similar to expertly chosen value functions. By learning, rather than manually specifying these predictions, we enable the agent to identify useful predictions in a self-supervised manner, taking a step towards truly autonomous systems.
What's a Good Prediction? Issues in Evaluating General Value Functions Through Error
Jan 23, 2020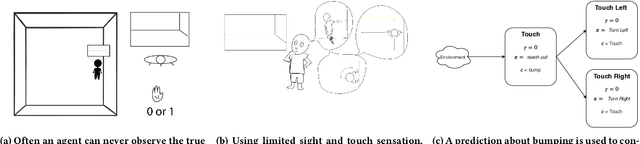
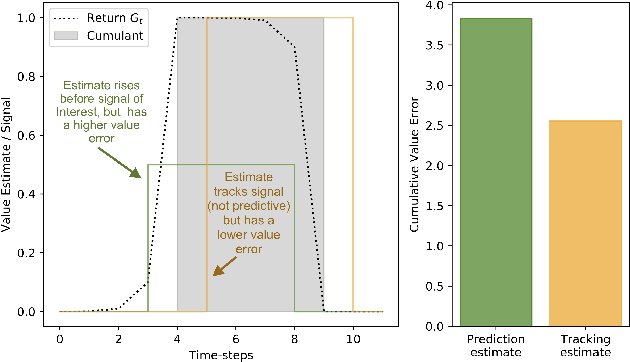
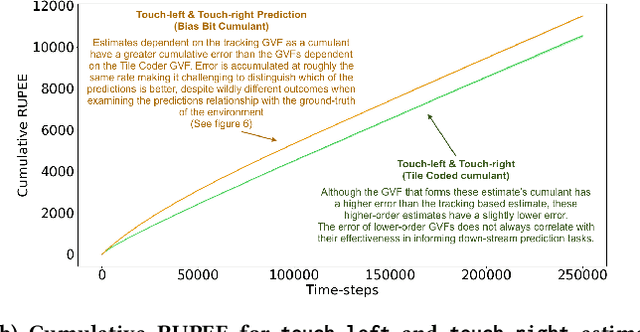

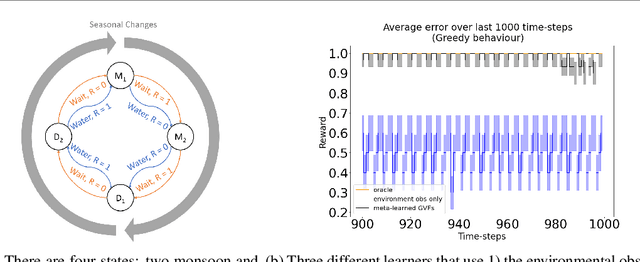
Constructing and maintaining knowledge of the world is a central problem for artificial intelligence research. Approaches to constructing an agent's knowledge using predictions have received increased amounts of interest in recent years. A particularly promising collection of research centres itself around architectures that formulate predictions as General Value Functions (GVFs), an approach commonly referred to as \textit{predictive knowledge}. A pernicious challenge for predictive knowledge architectures is determining what to predict. In this paper, we argue that evaluation methods---i.e., return error and RUPEE---are not well suited for the challenges of determining what to predict. As a primary contribution, we provide extended examples that evaluate predictions in terms of how they are used in further prediction tasks: a key motivation of predictive knowledge systems. We demonstrate that simply because a GVF's error is low, it does not necessarily follow the prediction is useful as a cumulant. We suggest evaluating 1) the relevance of a GVF's features to the prediction task at hand, and 2) evaluation of GVFs by \textit{how} they are used. To determine feature relevance, we generalize AutoStep to GTD, producing a step-size learning method suited to the life-long continual learning settings that predictive knowledge architectures are commonly deployed in. This paper contributes a first look into evaluation of predictions through their use, an integral component of predictive knowledge which is as of yet explored.