 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Useful Predictions by Meta-gradient Descent to Improve Decision-making
Nov 18, 2021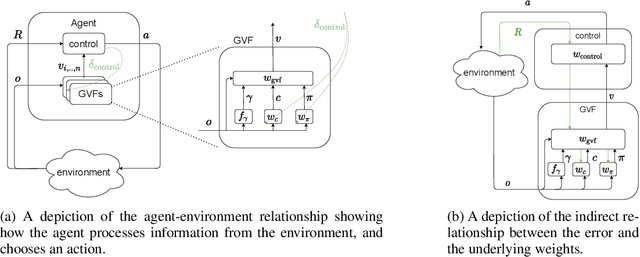

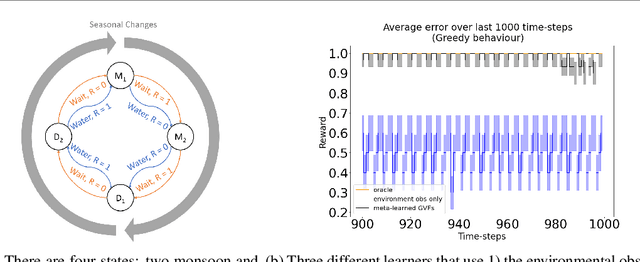
In computational reinforcement learning, a growing body of work seeks to express an agent's model of the world through predictions about future sensations. In this manuscript we focus on predictions expressed as General Value Functions: temporally extended estimates of the accumulation of a future signal. One challenge is determining from the infinitely many predictions that the agent could possibly make which might support decision-making. In this work, we contribute a meta-gradient descent method by which an agent can directly specify what predictions it learns, independent of designer instruction. To that end, we introduce a partially observable domain suited to this investigation. We then demonstrate that through interaction with the environment an agent can independently select predictions that resolve the partial-observability, resulting in performance similar to expertly chosen value functions. By learning, rather than manually specifying these predictions, we enable the agent to identify useful predictions in a self-supervised manner, taking a step towards truly autonomous systems.
What's a Good Prediction? Issues in Evaluating General Value Functions Through Error
Jan 23, 2020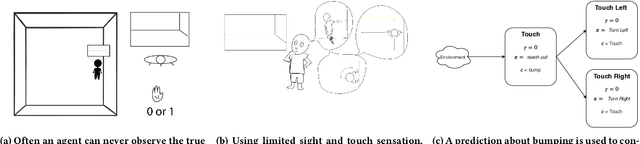
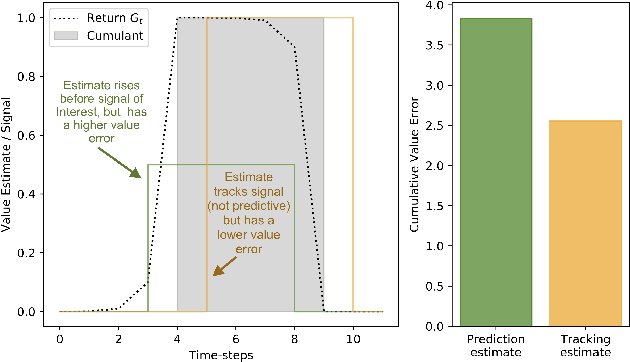
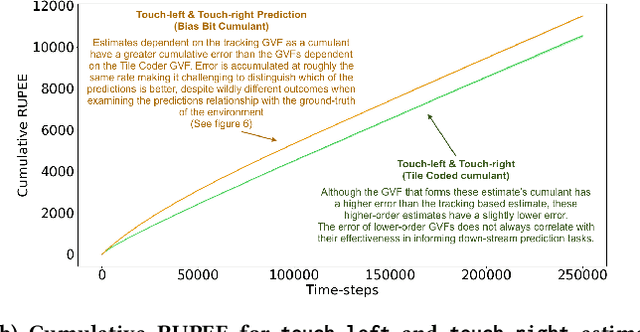

Constructing and maintaining knowledge of the world is a central problem for artificial intelligence research. Approaches to constructing an agent's knowledge using predictions have received increased amounts of interest in recent years. A particularly promising collection of research centres itself around architectures that formulate predictions as General Value Functions (GVFs), an approach commonly referred to as \textit{predictive knowledge}. A pernicious challenge for predictive knowledge architectures is determining what to predict. In this paper, we argue that evaluation methods---i.e., return error and RUPEE---are not well suited for the challenges of determining what to predict. As a primary contribution, we provide extended examples that evaluate predictions in terms of how they are used in further prediction tasks: a key motivation of predictive knowledge systems. We demonstrate that simply because a GVF's error is low, it does not necessarily follow the prediction is useful as a cumulant. We suggest evaluating 1) the relevance of a GVF's features to the prediction task at hand, and 2) evaluation of GVFs by \textit{how} they are used. To determine feature relevance, we generalize AutoStep to GTD, producing a step-size learning method suited to the life-long continual learning settings that predictive knowledge architectures are commonly deployed in. This paper contributes a first look into evaluation of predictions through their use, an integral component of predictive knowledge which is as of yet explored.
Women, politics and Twitter: Using machine learning to change the discourse
Nov 25, 2019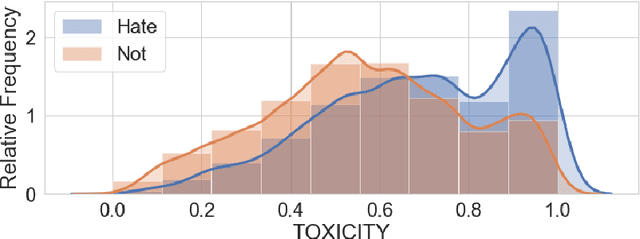
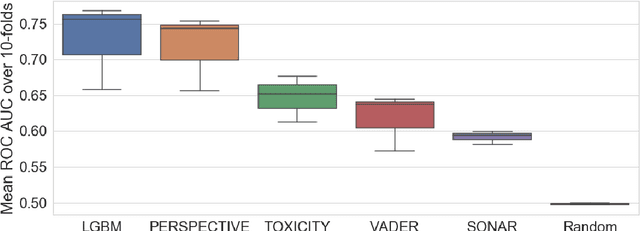
Including diverse voices in political decision-making strengthens our democratic institutions. Within the Canadian political system, there is gender inequality across all levels of elected government. Online abuse, such as hateful tweets, leveled at women engaged in politics contributes to this inequity, particularly tweets focusing on their gender. In this paper, we present ParityBOT: a Twitter bot which counters abusive tweets aimed at women in politics by sending supportive tweets about influential female leaders and facts about women in public life. ParityBOT is the first artificial intelligence-based intervention aimed at affecting online discourse for women in politics for the better. The goal of this project is to: $1$) raise awareness of issues relating to gender inequity in politics, and $2$) positively influence public discourse in politics. The main contribution of this paper is a scalable model to classify and respond to hateful tweets with quantitative and qualitative assessments. The ParityBOT abusive classification system was validated on public online harassment datasets. We conclude with analysis of the impact of ParityBOT, drawing from data gathered during interventions in both the $2019$ Alberta provincial and $2019$ Canadian federal elections.
Examining the Use of Temporal-Difference Incremental Delta-Bar-Delta for Real-World Predictive Knowledge Architectures
Aug 15, 2019
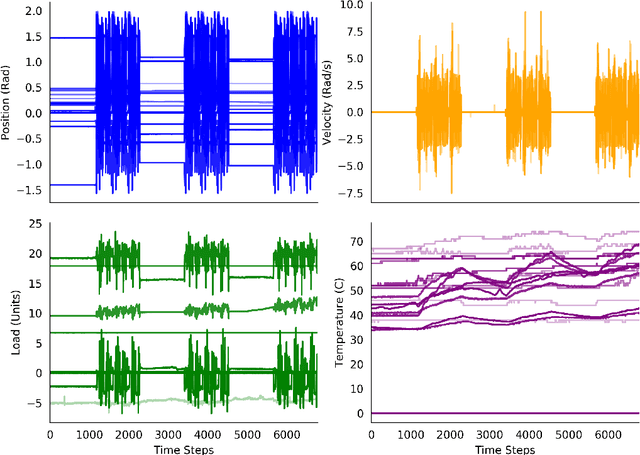


Predictions and predictive knowledge have seen recent success in improving not only robot control but also other applications ranging from industrial process control to rehabilitation. A property that makes these predictive approaches well suited for robotics is that they can be learned online and incrementally through interaction with the environment. However, a remaining challenge for many prediction-learning approaches is an appropriate choice of prediction-learning parameters, especially parameters that control the magnitude of a learning machine's updates to its predictions (the learning rate or step size). To begin to address this challenge, we examine the use of online step-size adaptation using a sensor-rich robotic arm. Our method of choice, Temporal-Difference Incremental Delta-Bar-Delta (TIDBD), learns and adapts step sizes on a feature level; importantly, TIDBD allows step-size tuning and representation learning to occur at the same time. We show that TIDBD is a practical alternative for classic Temporal-Difference (TD) learning via an extensive parameter search. Both approaches perform comparably in terms of predicting future aspects of a robotic data stream. Furthermore, the use of a step-size adaptation method like TIDBD appears to allow a system to automatically detect and characterize common sensor failures in a robotic application. Together, these results promise to improve the ability of robotic devices to learn from interactions with their environments in a robust way, providing key capabilities for autonomous agents and robots.
When is a Prediction Knowledge?
Apr 18, 2019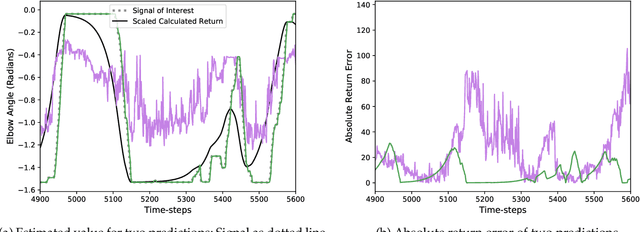
Within Reinforcement Learning, there is a growing collection of research which aims to express all of an agent's knowledge of the world through predictions about sensation, behaviour, and time. This work can be seen not only as a collection of architectural proposals, but also as the beginnings of a theory of machine knowledge in reinforcement learning. Recent work has expanded what can be expressed using predictions, and developed applications which use predictions to inform decision-making on a variety of synthetic and real-world problems. While promising, we here suggest that the notion of predictions as knowledge in reinforcement learning is as yet underdeveloped: some work explicitly refers to predictions as knowledge, what the requirements are for considering a prediction to be knowledge have yet to be well explored. This specification of the necessary and sufficient conditions of knowledge is important; even if claims about the nature of knowledge are left implicit in technical proposals, the underlying assumptions of such claims have consequences for the systems we design. These consequences manifest in both the way we choose to structure predictive knowledge architectures, and how we evaluate them. In this paper, we take a first step to formalizing predictive knowledge by discussing the relationship of predictive knowledge learning methods to existing theories of knowledge in epistemology. Specifically, we explore the relationships between Generalized Value Functions and epistemic notions of Justification and Truth.
Making Meaning: Semiotics Within Predictive Knowledge Architectures
Apr 18, 2019Within Reinforcement Learning, there is a fledgling approach to conceptualizing the environment in terms of predictions. Central to this predictive approach is the assertion that it is possible to construct ontologies in terms of predictions about sensation, behaviour, and time---to categorize the world into entities which express all aspects of the world using only predictions. This construction of ontologies is integral to predictive approaches to machine knowledge where objects are described exclusively in terms of how they are perceived. In this paper, we ground the Pericean model of semiotics in terms of Reinforcement Learning Methods, describing Peirce's Three Categories in the notation of General Value Functions. Using the Peircean model of semiotics, we demonstrate that predictions alone are insufficient to construct an ontology; however, we identify predictions as being integral to the meaning-making process. Moreover, we discuss how predictive knowledge provides a particularly stable foundation for semiosis\textemdash the process of making meaning\textemdash and suggest a possible avenue of research to design algorithmic methods which construct semantics and meaning using predictions.
Learning Feature Relevance Through Step Size Adaptation in Temporal-Difference Learning
Mar 08, 2019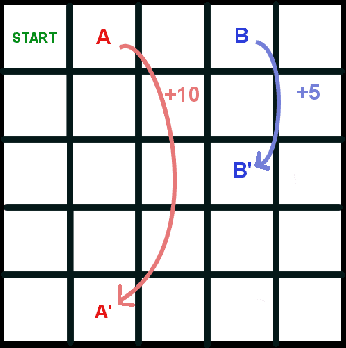


There is a long history of using meta learning as representation learning, specifically for determining the relevance of inputs. In this paper, we examine an instance of meta-learning in which feature relevance is learned by adapting step size parameters of stochastic gradient descent---building on a variety of prior work in stochastic approximation, machine learning, and artificial neural networks. In particular, we focus on stochastic meta-descent introduced in the Incremental Delta-Bar-Delta (IDBD) algorithm for setting individual step sizes for each feature of a linear function approximator. Using IDBD, a feature with large or small step sizes will have a large or small impact on generalization from training examples. As a main contribution of this work, we extend IDBD to temporal-difference (TD) learning---a form of learning which is effective in sequential, non i.i.d. problems. We derive a variety of IDBD generalizations for TD learning, demonstrating that they are able to distinguish which features are relevant and which are not. We demonstrate that TD IDBD is effective at learning feature relevance in both an idealized gridworld and a real-world robotic prediction task.
TIDBD: Adapting Temporal-difference Step-sizes Through Stochastic Meta-descent
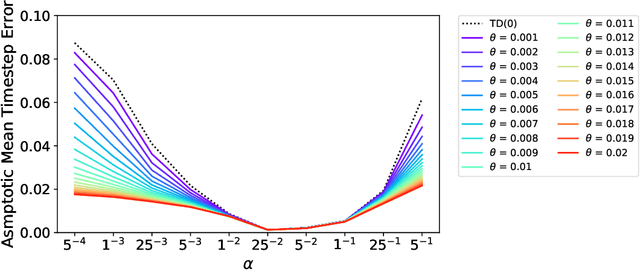
Apr 10, 2018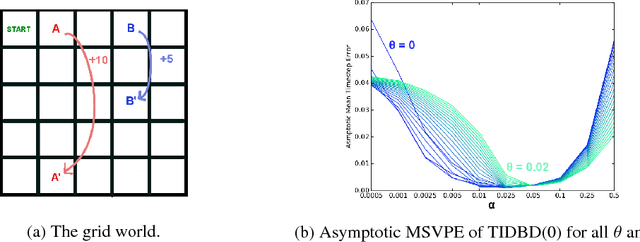
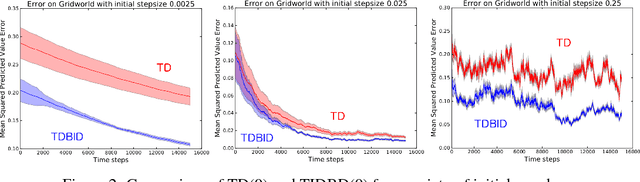
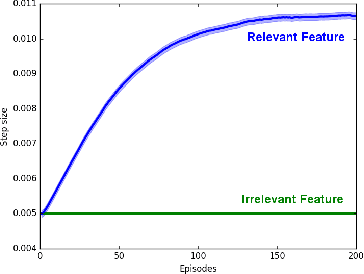
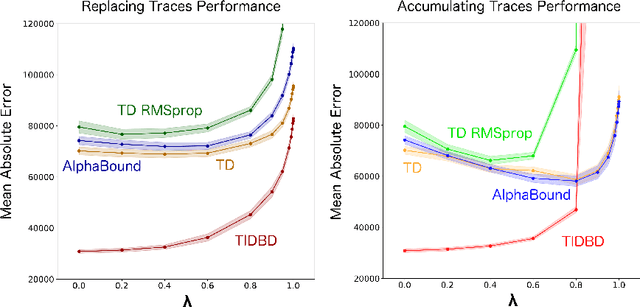
In this paper, we introduce a method for adapting the step-sizes of temporal difference (TD) learning. The performance of TD methods often depends on well chosen step-sizes, yet few algorithms have been developed for setting the step-size automatically for TD learning. An important limitation of current methods is that they adapt a single step-size shared by all the weights of the learning system. A vector step-size enables greater optimization by specifying parameters on a per-feature basis. Furthermore, adapting parameters at different rates has the added benefit of being a simple form of representation learning. We generalize Incremental Delta Bar Delta (IDBD)---a vectorized adaptive step-size method for supervised learning---to TD learning, which we name TIDBD. We demonstrate that TIDBD is able to find appropriate step-sizes in both stationary and non-stationary prediction tasks, outperforming ordinary TD methods and TD methods with scalar step-size adaptation; we demonstrate that it can differentiate between features which are relevant and irrelevant for a given task, performing representation learning; and we show on a real-world robot prediction task that TIDBD is able to outperform ordinary TD methods and TD methods augmented with AlphaBound and RMSprop.