 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFive Properties of Specific Curiosity You Didn't Know Curious Machines Should Have
Dec 01, 2022Curiosity for machine agents has been a focus of lively research activity. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we conduct a comprehensive, multidisciplinary survey of the field of animal and machine curiosity. As a principal contribution of this work, we use this survey as a foundation to introduce and define what we consider to be five of the most important properties of specific curiosity: 1) directedness towards inostensible referents, 2) cessation when satisfied, 3) voluntary exposure, 4) transience, and 5) coherent long-term learning. As a second main contribution of this work, we show how these properties may be implemented together in a proof-of-concept reinforcement learning agent: we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, our example of a computational specific curiosity agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work, therefore, presents a landmark synthesis and translation of specific curiosity to the domain of machine learning and reinforcement learning and provides a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making computational agents in complex environments.
What Should I Know? Using Meta-gradient Descent for Predictive Feature Discovery in a Single Stream of Experience
Jun 13, 2022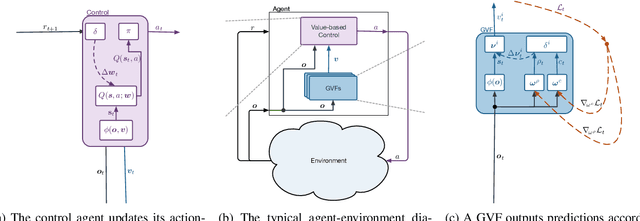
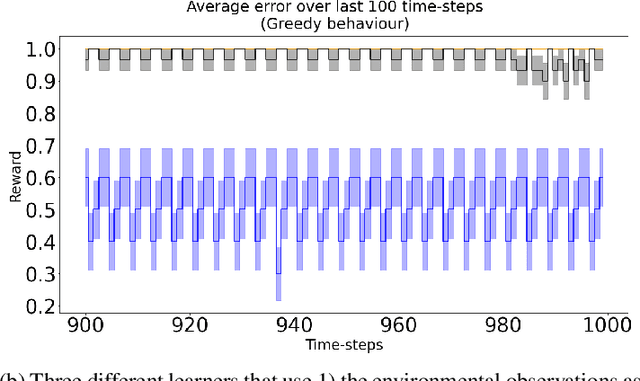
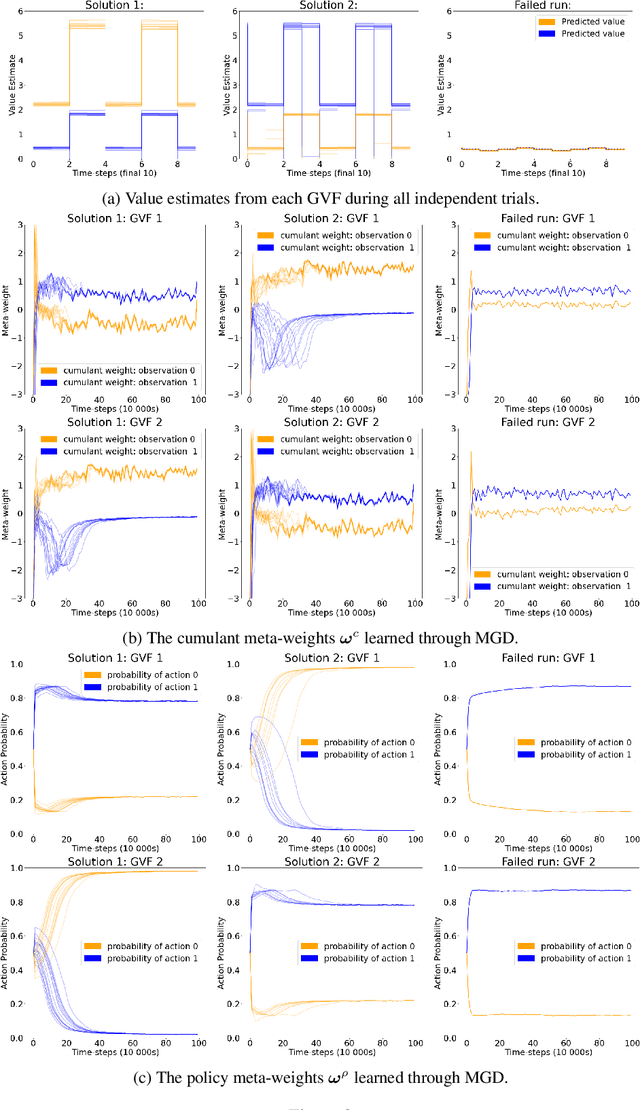
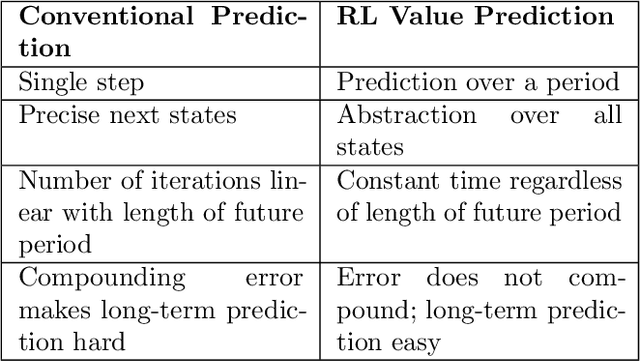
In computational reinforcement learning, a growing body of work seeks to construct an agent's perception of the world through predictions of future sensations; predictions about environment observations are used as additional input features to enable better goal-directed decision-making. An open challenge in this line of work is determining from the infinitely many predictions that the agent could possibly make which predictions might best support decision-making. This challenge is especially apparent in continual learning problems where a single stream of experience is available to a singular agent. As a primary contribution, we introduce a meta-gradient descent process by which an agent learns 1) what predictions to make, 2) the estimates for its chosen predictions, and 3) how to use those estimates to generate policies that maximize future reward -- all during a single ongoing process of continual learning. In this manuscript we consider predictions expressed as General Value Functions: temporally extended estimates of the accumulation of a future signal. We demonstrate that through interaction with the environment an agent can independently select predictions that resolve partial-observability, resulting in performance similar to expertly specified GVFs. By learning, rather than manually specifying these predictions, we enable the agent to identify useful predictions in a self-supervised manner, taking a step towards truly autonomous systems.
Prototyping three key properties of specific curiosity in computational reinforcement learning
May 20, 2022

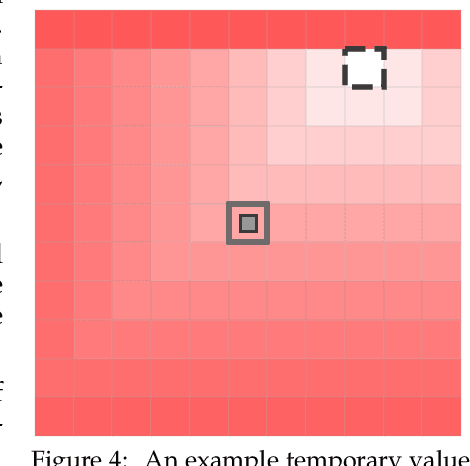
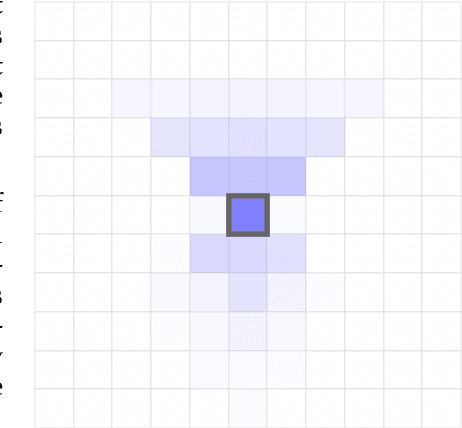
Curiosity for machine agents has been a focus of intense research. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we introduce three of the most immediate of these properties -- directedness, cessation when satisfied, and voluntary exposure -- and show how they may be implemented together in a proof-of-concept reinforcement learning agent; further, we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, the agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work therefore presents a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making agents in complex environments.
Finding Useful Predictions by Meta-gradient Descent to Improve Decision-making
Nov 18, 2021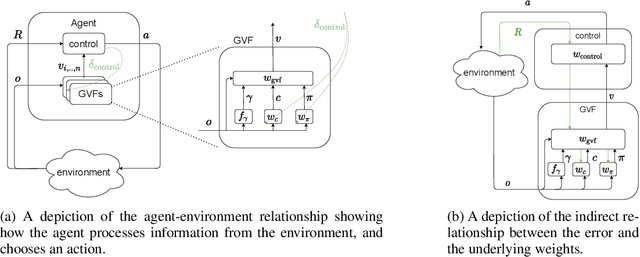

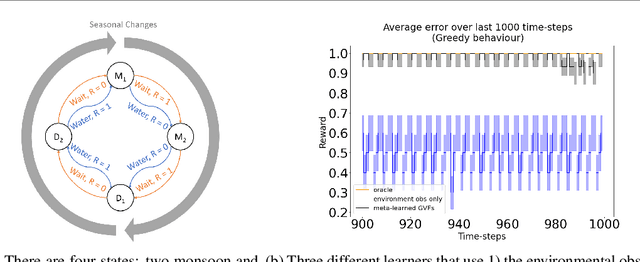
In computational reinforcement learning, a growing body of work seeks to express an agent's model of the world through predictions about future sensations. In this manuscript we focus on predictions expressed as General Value Functions: temporally extended estimates of the accumulation of a future signal. One challenge is determining from the infinitely many predictions that the agent could possibly make which might support decision-making. In this work, we contribute a meta-gradient descent method by which an agent can directly specify what predictions it learns, independent of designer instruction. To that end, we introduce a partially observable domain suited to this investigation. We then demonstrate that through interaction with the environment an agent can independently select predictions that resolve the partial-observability, resulting in performance similar to expertly chosen value functions. By learning, rather than manually specifying these predictions, we enable the agent to identify useful predictions in a self-supervised manner, taking a step towards truly autonomous systems.
Affordance as general value function: A computational model
Oct 27, 2020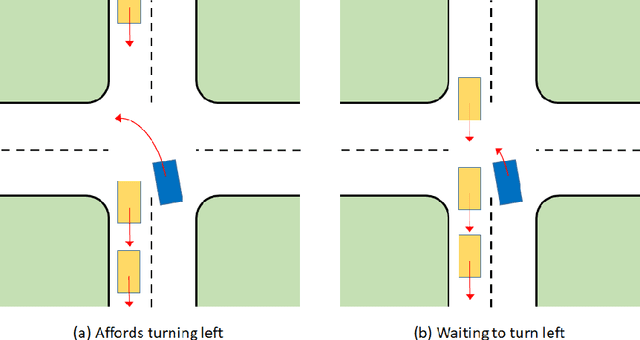
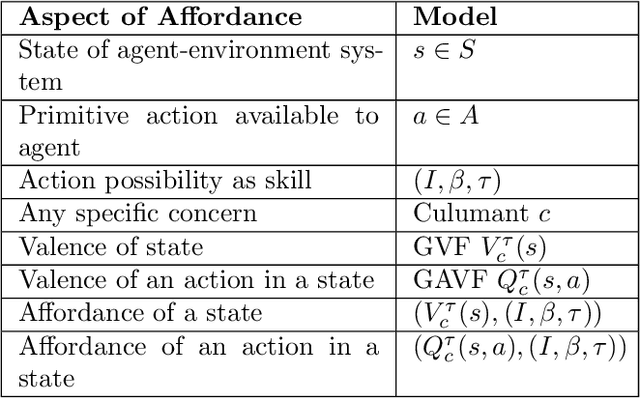

General value functions (GVFs) in the reinforcement learning (RL) literature are long-term predictive summaries of the outcomes of agents following specific policies in the environment. Affordances as perceived valences of action possibilities may be cast into predicted policy-relative goodness and modelled as GVFs. A systematic explication of this connection shows that GVFs and especially their deep learning embodiments (1) realize affordance prediction as a form of direct perception, (2) illuminate the fundamental connection between action and perception in affordance, and (3) offer a scalable way to learn affordances using RL methods. Through a comprehensive review of existing literature on recent successes of GVF applications in robotics, rehabilitation, industrial automation, and autonomous driving, we demonstrate that GVFs provide the right framework for learning affordances in real-world applications. In addition, we highlight a few new avenues of research opened up by the perspective of "affordance as GVF", including using GVFs for orchestrating complex behaviors.
Gamma-Nets: Generalizing Value Estimation over Timescale
Nov 23, 2019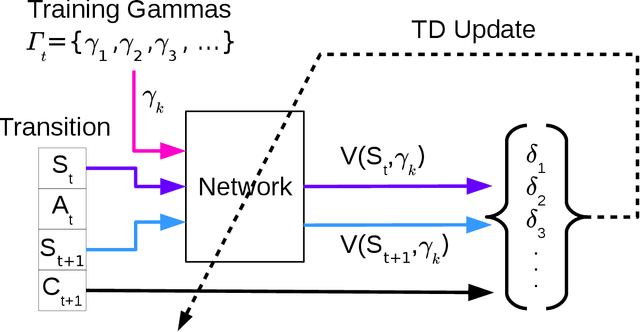
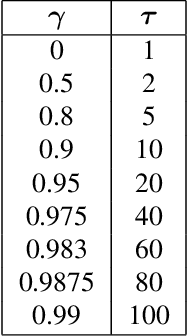
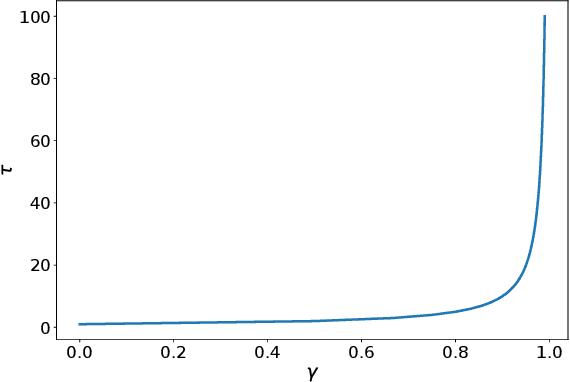

We present $\Gamma$-nets, a method for generalizing value function estimation over timescale. By using the timescale as one of the estimator's inputs we can estimate value for arbitrary timescales. As a result, the prediction target for any timescale is available and we are free to train on multiple timescales at each timestep. Here we empirically evaluate $\Gamma$-nets in the policy evaluation setting. We first demonstrate the approach on a square wave and then on a robot arm using linear function approximation. Next, we consider the deep reinforcement learning setting using several Atari video games. Our results show that $\Gamma$-nets can be effective for predicting arbitrary timescales, with only a small cost in accuracy as compared to learning estimators for fixed timescales. $\Gamma$-nets provide a method for compactly making predictions at many timescales without requiring a priori knowledge of the task, making it a valuable contribution to ongoing work on model-based planning, representation learning, and lifelong learning algorithms.
Examining the Use of Temporal-Difference Incremental Delta-Bar-Delta for Real-World Predictive Knowledge Architectures
Aug 15, 2019
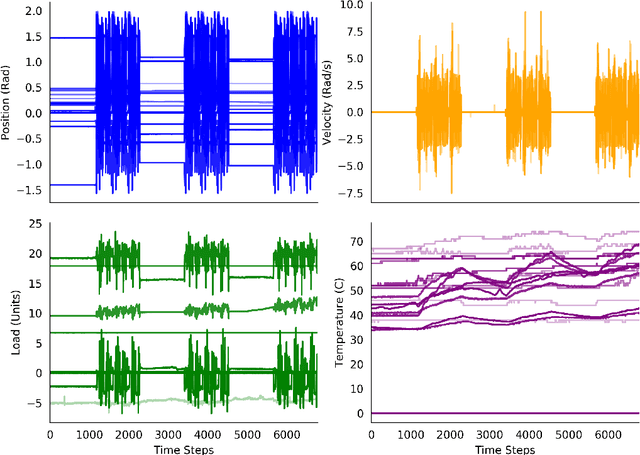


Predictions and predictive knowledge have seen recent success in improving not only robot control but also other applications ranging from industrial process control to rehabilitation. A property that makes these predictive approaches well suited for robotics is that they can be learned online and incrementally through interaction with the environment. However, a remaining challenge for many prediction-learning approaches is an appropriate choice of prediction-learning parameters, especially parameters that control the magnitude of a learning machine's updates to its predictions (the learning rate or step size). To begin to address this challenge, we examine the use of online step-size adaptation using a sensor-rich robotic arm. Our method of choice, Temporal-Difference Incremental Delta-Bar-Delta (TIDBD), learns and adapts step sizes on a feature level; importantly, TIDBD allows step-size tuning and representation learning to occur at the same time. We show that TIDBD is a practical alternative for classic Temporal-Difference (TD) learning via an extensive parameter search. Both approaches perform comparably in terms of predicting future aspects of a robotic data stream. Furthermore, the use of a step-size adaptation method like TIDBD appears to allow a system to automatically detect and characterize common sensor failures in a robotic application. Together, these results promise to improve the ability of robotic devices to learn from interactions with their environments in a robust way, providing key capabilities for autonomous agents and robots.
General Dynamic Neural Networks for explainable PID parameter tuning in control engineering: An extensive comparison
May 30, 2019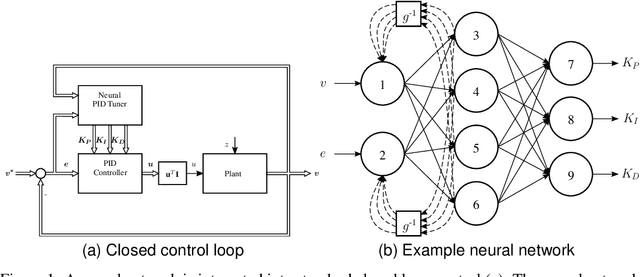
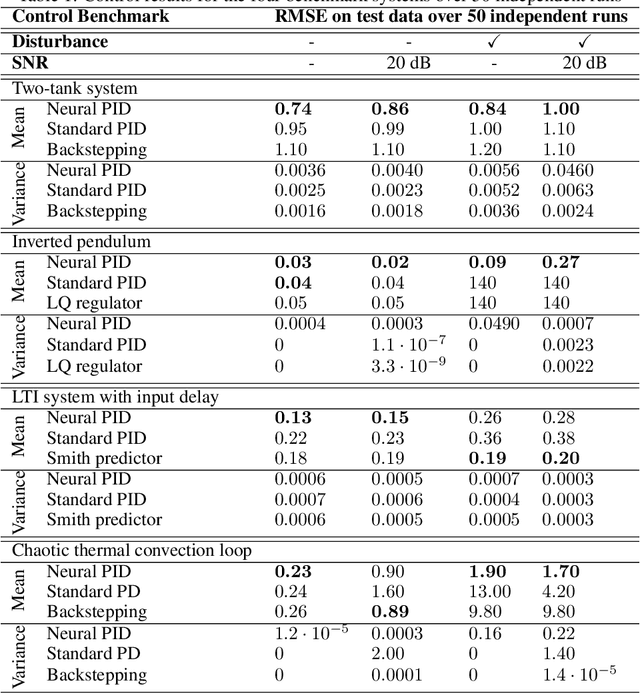
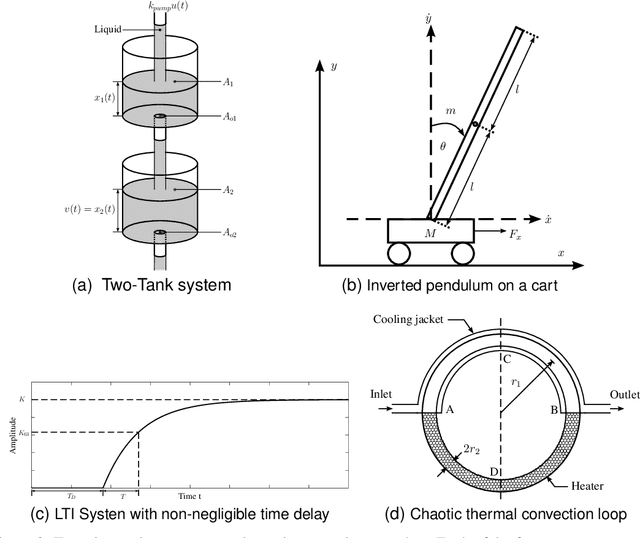
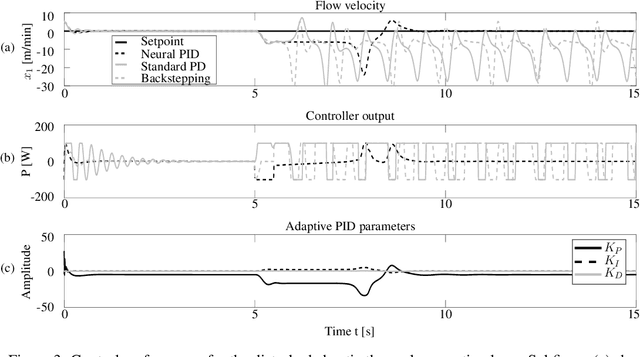
Automation, the ability to run processes without human supervision, is one of the most important drivers of increased scalability and productivity. Modern automation largely relies on forms of closed loop control, wherein a controller interacts with a controlled process via actions, based on observations. Despite an increase in the use of machine learning for process control, most deployed controllers still are linear Proportional-Integral-Derivative (PID) controllers. PID controllers perform well on linear and near-linear systems but are not robust enough for more complex processes. As a main contribution of this paper, we examine the utility of extending standard PID controllers with General Dynamic Neural Networks (GDNN); we show that GDNN (neural) PID controllers perform well on a range of control systems and highlight what is needed to make them a stable, scalable, and interpretable option for control. To do so, we provide a comprehensive study using four different benchmark processes. All control environments are evaluated with and without noise as well as with and without disturbances. The neural PID controller performs better than standard PID control in 15 of 16 tasks and better than model-based control in 13 of 16 tasks. As a second contribution of this work, we address the Achilles heel that prevents neural networks from being used in real-world control processes so far: lack of interpretability. We use bounded-input bounded-output stability analysis to evaluate the parameters suggested by the neural network, thus making them understandable for human engineers. This combination of rigorous evaluation paired with better explainability is an important step towards the acceptance of neural-network-based control approaches for real-world systems. It is furthermore an important step towards explainable and safe applied artificial intelligence.