 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Function Decomposition for Iterative Design of Reinforcement Learning Agents
Jun 24, 2022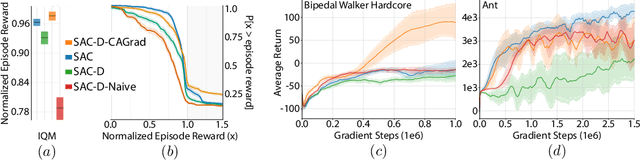

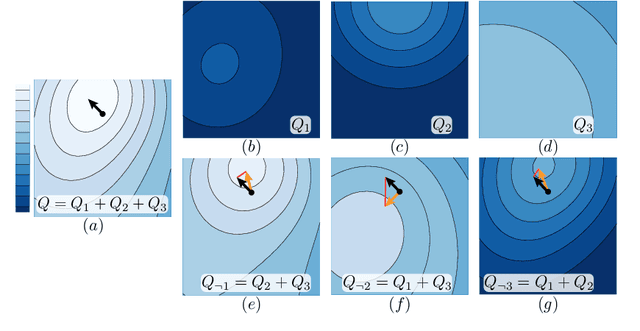

Designing reinforcement learning (RL) agents is typically a difficult process that requires numerous design iterations. Learning can fail for a multitude of reasons, and standard RL methods provide too few tools to provide insight into the exact cause. In this paper, we show how to integrate value decomposition into a broad class of actor-critic algorithms and use it to assist in the iterative agent-design process. Value decomposition separates a reward function into distinct components and learns value estimates for each. These value estimates provide insight into an agent's learning and decision-making process and enable new training methods to mitigate common problems. As a demonstration, we introduce SAC-D, a variant of soft actor-critic (SAC) adapted for value decomposition. SAC-D maintains similar performance to SAC, while learning a larger set of value predictions. We also introduce decomposition-based tools that exploit this information, including a new reward influence metric, which measures each reward component's effect on agent decision-making. Using these tools, we provide several demonstrations of decomposition's use in identifying and addressing problems in the design of both environments and agents. Value decomposition is broadly applicable and easy to incorporate into existing algorithms and workflows, making it a powerful tool in an RL practitioner's toolbox.
Gamma-Nets: Generalizing Value Estimation over Timescale
Nov 23, 2019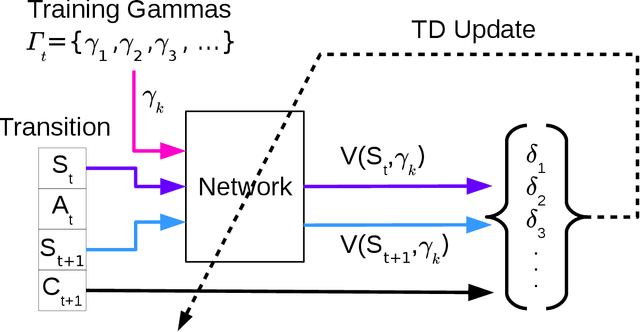
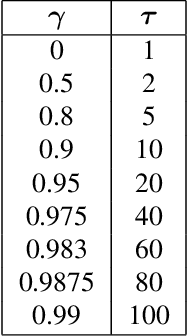
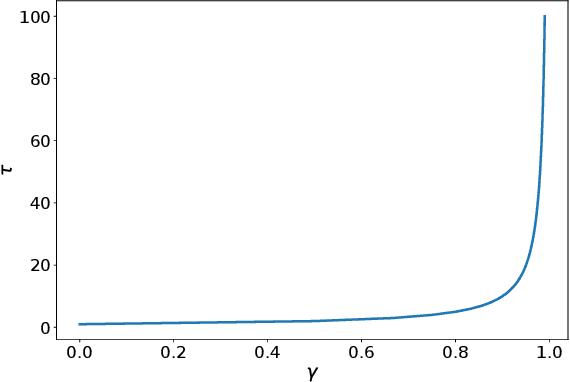

We present $\Gamma$-nets, a method for generalizing value function estimation over timescale. By using the timescale as one of the estimator's inputs we can estimate value for arbitrary timescales. As a result, the prediction target for any timescale is available and we are free to train on multiple timescales at each timestep. Here we empirically evaluate $\Gamma$-nets in the policy evaluation setting. We first demonstrate the approach on a square wave and then on a robot arm using linear function approximation. Next, we consider the deep reinforcement learning setting using several Atari video games. Our results show that $\Gamma$-nets can be effective for predicting arbitrary timescales, with only a small cost in accuracy as compared to learning estimators for fixed timescales. $\Gamma$-nets provide a method for compactly making predictions at many timescales without requiring a priori knowledge of the task, making it a valuable contribution to ongoing work on model-based planning, representation learning, and lifelong learning algorithms.
Implementing the Deep Q-Network
Nov 20, 2017
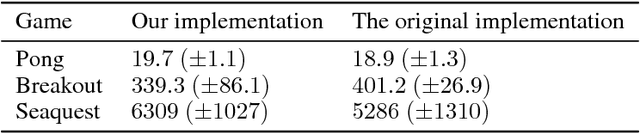
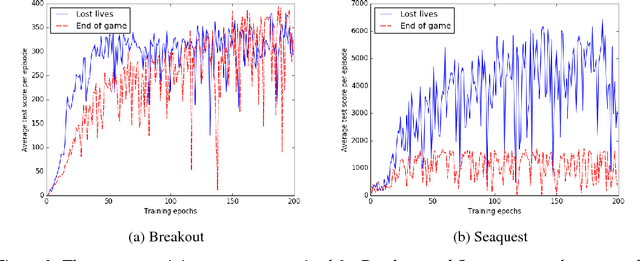
The Deep Q-Network proposed by Mnih et al. [2015] has become a benchmark and building point for much deep reinforcement learning research. However, replicating results for complex systems is often challenging since original scientific publications are not always able to describe in detail every important parameter setting and software engineering solution. In this paper, we present results from our work reproducing the results of the DQN paper. We highlight key areas in the implementation that were not covered in great detail in the original paper to make it easier for researchers to replicate these results, including termination conditions and gradient descent algorithms. Finally, we discuss methods for improving the computational performance and provide our own implementation that is designed to work with a range of domains, and not just the original Arcade Learning Environment [Bellemare et al., 2013].
Environment-Independent Task Specifications via GLTL
Apr 14, 2017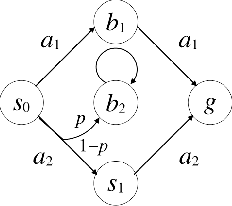
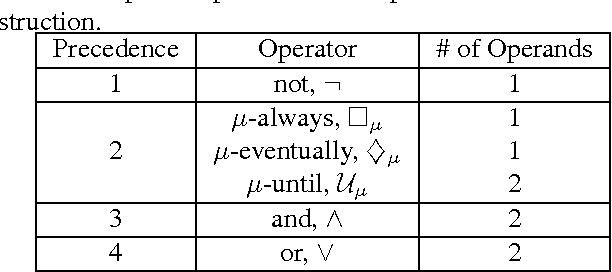
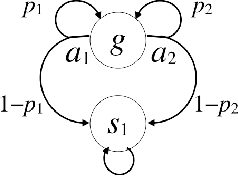
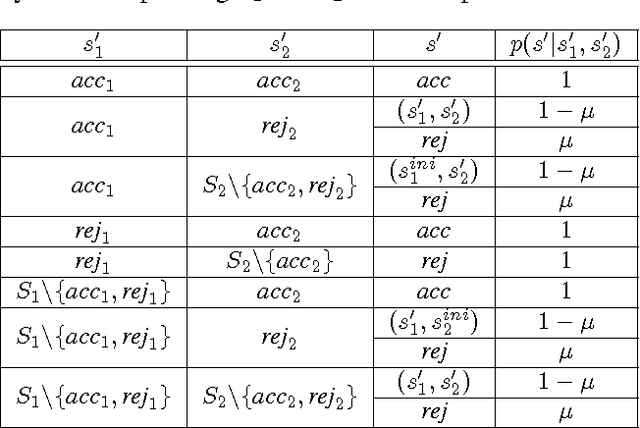
We propose a new task-specification language for Markov decision processes that is designed to be an improvement over reward functions by being environment independent. The language is a variant of Linear Temporal Logic (LTL) that is extended to probabilistic specifications in a way that permits approximations to be learned in finite time. We provide several small environments that demonstrate the advantages of our geometric LTL (GLTL) language and illustrate how it can be used to specify standard reinforcement-learning tasks straightforwardly.
Interactive Learning from Policy-Dependent Human Feedback
Jan 21, 2017

For agents and robots to become more useful, they must be able to quickly learn from non-technical users. This paper investigates the problem of interactively learning behaviors communicated by a human teacher using positive and negative feedback. Much previous work on this problem has made the assumption that people provide feedback for decisions that is dependent on the behavior they are teaching and is independent from the learner's current policy. We present empirical results that show this assumption to be false---whether human trainers give a positive or negative feedback for a decision is influenced by the learner's current policy. We argue that policy-dependent feedback, in addition to being commonplace, enables useful training strategies from which agents should benefit. Based on this insight, we introduce Convergent Actor-Critic by Humans (COACH), an algorithm for learning from policy-dependent feedback that converges to a local optimum. Finally, we demonstrate that COACH can successfully learn multiple behaviors on a physical robot, even with noisy image features.