 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Function Decomposition for Iterative Design of Reinforcement Learning Agents
Jun 24, 2022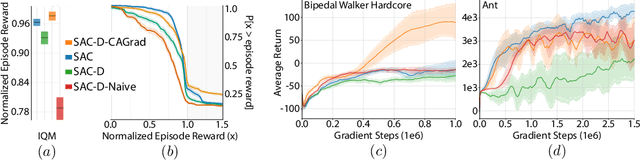

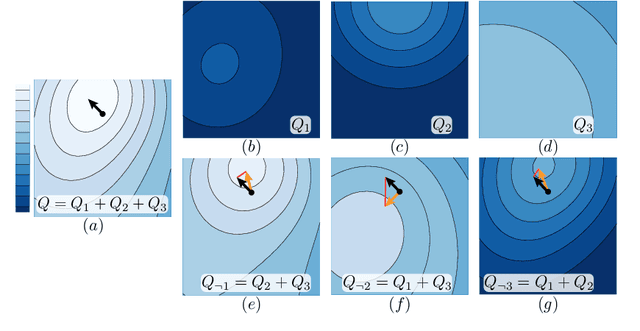

Designing reinforcement learning (RL) agents is typically a difficult process that requires numerous design iterations. Learning can fail for a multitude of reasons, and standard RL methods provide too few tools to provide insight into the exact cause. In this paper, we show how to integrate value decomposition into a broad class of actor-critic algorithms and use it to assist in the iterative agent-design process. Value decomposition separates a reward function into distinct components and learns value estimates for each. These value estimates provide insight into an agent's learning and decision-making process and enable new training methods to mitigate common problems. As a demonstration, we introduce SAC-D, a variant of soft actor-critic (SAC) adapted for value decomposition. SAC-D maintains similar performance to SAC, while learning a larger set of value predictions. We also introduce decomposition-based tools that exploit this information, including a new reward influence metric, which measures each reward component's effect on agent decision-making. Using these tools, we provide several demonstrations of decomposition's use in identifying and addressing problems in the design of both environments and agents. Value decomposition is broadly applicable and easy to incorporate into existing algorithms and workflows, making it a powerful tool in an RL practitioner's toolbox.
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 16, 2020

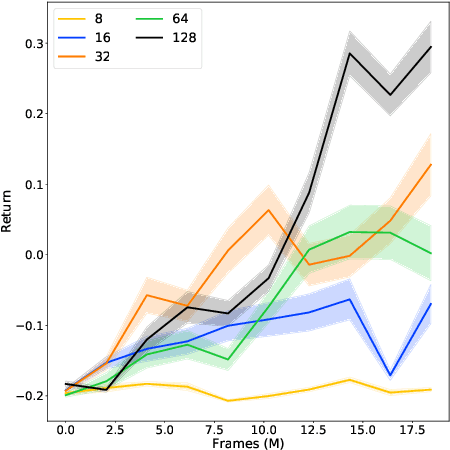
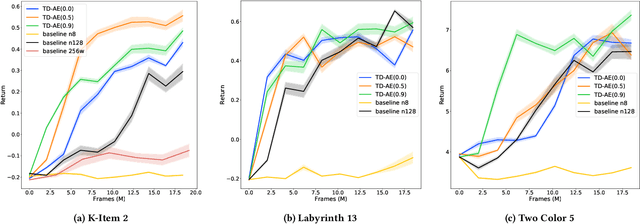
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
Gamma-Nets: Generalizing Value Estimation over Timescale
Nov 23, 2019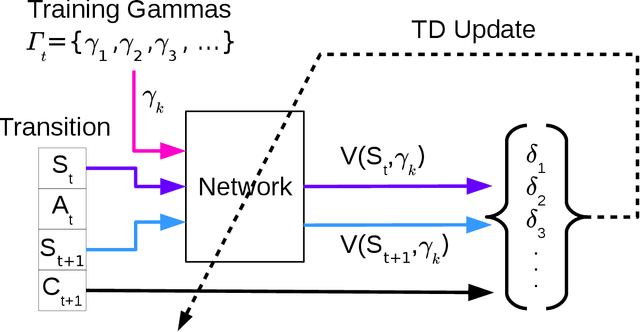
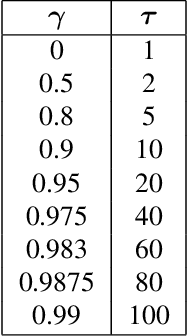
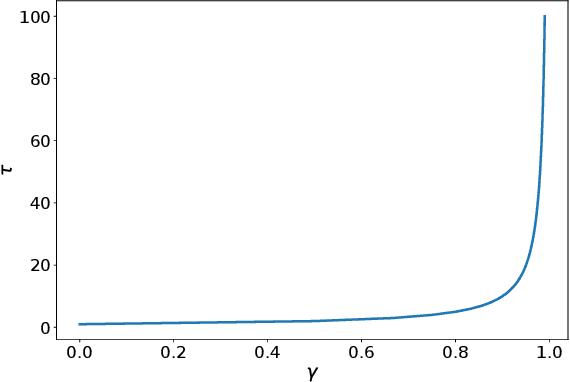

We present $\Gamma$-nets, a method for generalizing value function estimation over timescale. By using the timescale as one of the estimator's inputs we can estimate value for arbitrary timescales. As a result, the prediction target for any timescale is available and we are free to train on multiple timescales at each timestep. Here we empirically evaluate $\Gamma$-nets in the policy evaluation setting. We first demonstrate the approach on a square wave and then on a robot arm using linear function approximation. Next, we consider the deep reinforcement learning setting using several Atari video games. Our results show that $\Gamma$-nets can be effective for predicting arbitrary timescales, with only a small cost in accuracy as compared to learning estimators for fixed timescales. $\Gamma$-nets provide a method for compactly making predictions at many timescales without requiring a priori knowledge of the task, making it a valuable contribution to ongoing work on model-based planning, representation learning, and lifelong learning algorithms.
Accelerating Learning in Constructive Predictive Frameworks with the Successor Representation
Mar 23, 2018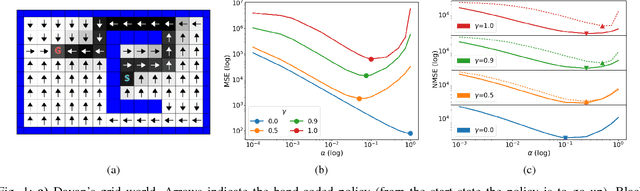


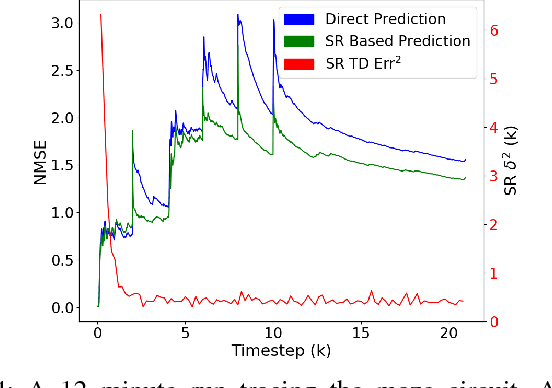
Here we propose using the successor representation (SR) to accelerate learning in a constructive knowledge system based on general value functions (GVFs). In real-world settings like robotics for unstructured and dynamic environments, it is infeasible to model all meaningful aspects of a system and its environment by hand due to both complexity and size. Instead, robots must be capable of learning and adapting to changes in their environment and task, incrementally constructing models from their own experience. GVFs, taken from the field of reinforcement learning (RL), are a way of modeling the world as predictive questions. One approach to such models proposes a massive network of interconnected and interdependent GVFs, which are incrementally added over time. It is reasonable to expect that new, incrementally added predictions can be learned more swiftly if the learning process leverages knowledge gained from past experience. The SR provides such a means of separating the dynamics of the world from the prediction targets and thus capturing regularities that can be reused across multiple GVFs. As a primary contribution of this work, we show that using SR-based predictions can improve sample efficiency and learning speed in a continual learning setting where new predictions are incrementally added and learned over time. We analyze our approach in a grid-world and then demonstrate its potential on data from a physical robot arm.
Directly Estimating the Variance of the λ-Return Using Temporal-Difference Methods
Feb 14, 2018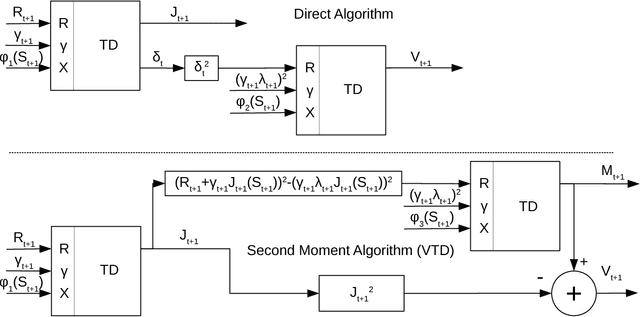
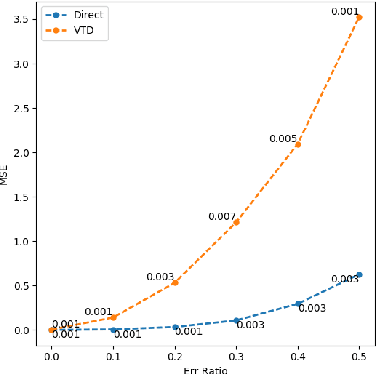
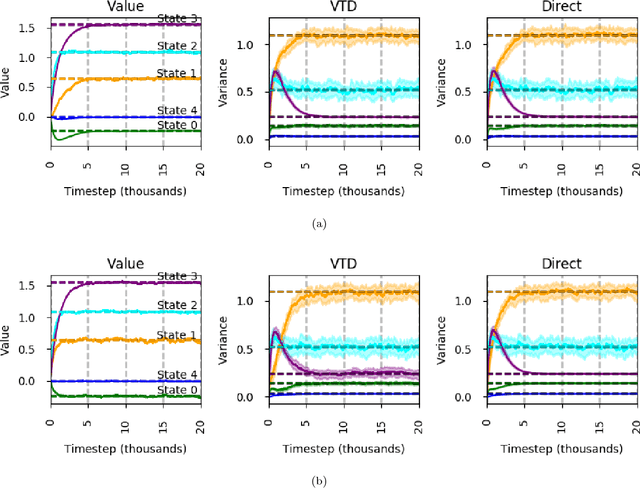
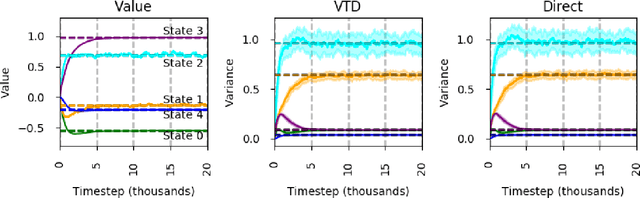
This paper investigates estimating the variance of a temporal-difference learning agent's update target. Most reinforcement learning methods use an estimate of the value function, which captures how good it is for the agent to be in a particular state and is mathematically expressed as the expected sum of discounted future rewards (called the return). These values can be straightforwardly estimated by averaging batches of returns using Monte Carlo methods. However, if we wish to update the agent's value estimates during learning--before terminal outcomes are observed--we must use a different estimation target called the {\lambda}-return, which truncates the return with the agent's own estimate of the value function. Temporal difference learning methods estimate the expected {\lambda}-return for each state, allowing these methods to update online and incrementally, and in most cases achieve better generalization error and faster learning than Monte Carlo methods. Naturally one could attempt to estimate higher-order moments of the {\lambda}-return. This paper is about estimating the variance of the {\lambda}-return. Prior work has shown that given estimates of the variance of the {\lambda}-return, learning systems can be constructed to (1) mitigate risk in action selection, and (2) automatically adapt the parameters of the learning process itself to improve performance. Unfortunately, existing methods for estimating the variance of the {\lambda}-return are complex and not well understood empirically. We contribute a method for estimating the variance of the {\lambda}-return directly using policy evaluation methods from reinforcement learning. Our approach is significantly simpler than prior methods that independently estimate the second moment of the {\lambda}-return. Empirically our new approach behaves at least as well as existing approaches, but is generally more robust.
Communicative Capital for Prosthetic Agents
Nov 10, 2017
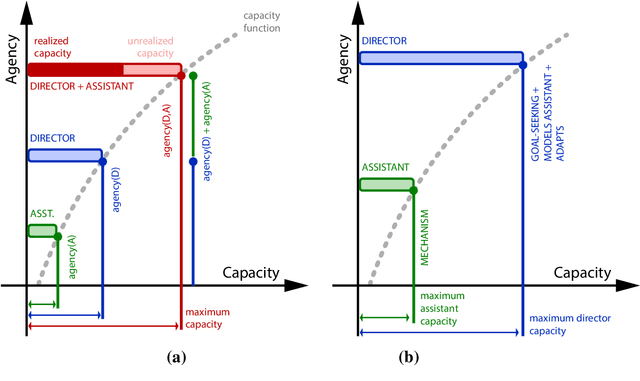

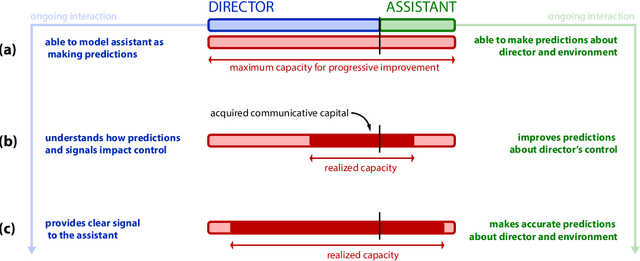
This work presents an overarching perspective on the role that machine intelligence can play in enhancing human abilities, especially those that have been diminished due to injury or illness. As a primary contribution, we develop the hypothesis that assistive devices, and specifically artificial arms and hands, can and should be viewed as agents in order for us to most effectively improve their collaboration with their human users. We believe that increased agency will enable more powerful interactions between human users and next generation prosthetic devices, especially when the sensorimotor space of the prosthetic technology greatly exceeds the conventional control and communication channels available to a prosthetic user. To more concretely examine an agency-based view on prosthetic devices, we propose a new schema for interpreting the capacity of a human-machine collaboration as a function of both the human's and machine's degrees of agency. We then introduce the idea of communicative capital as a way of thinking about the communication resources developed by a human and a machine during their ongoing interaction. Using this schema of agency and capacity, we examine the benefits and disadvantages of increasing the agency of a prosthetic limb. To do so, we present an analysis of examples from the literature where building communicative capital has enabled a progression of fruitful, task-directed interactions between prostheses and their human users. We then describe further work that is needed to concretely evaluate the hypothesis that prostheses are best thought of as agents. The agent-based viewpoint developed in this article significantly extends current thinking on how best to support the natural, functional use of increasingly complex prosthetic enhancements, and opens the door for more powerful interactions between humans and their assistive technologies.
Introspective Agents: Confidence Measures for General Value Functions
Jun 17, 2016
Agents of general intelligence deployed in real-world scenarios must adapt to ever-changing environmental conditions. While such adaptive agents may leverage engineered knowledge, they will require the capacity to construct and evaluate knowledge themselves from their own experience in a bottom-up, constructivist fashion. This position paper builds on the idea of encoding knowledge as temporally extended predictions through the use of general value functions. Prior work has focused on learning predictions about externally derived signals about a task or environment (e.g. battery level, joint position). Here we advocate that the agent should also predict internally generated signals regarding its own learning process - for example, an agent's confidence in its learned predictions. Finally, we suggest how such information would be beneficial in creating an introspective agent that is able to learn to make good decisions in a complex, changing world.