 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Laplacian Keyboard: Beyond the Linear Span
Feb 07, 2026Across scientific disciplines, Laplacian eigenvectors serve as a fundamental basis for simplifying complex systems, from signal processing to quantum mechanics. In reinforcement learning (RL), these eigenvectors provide a natural basis for approximating reward functions; however, their use is typically limited to their linear span, which restricts expressivity in complex environments. We introduce the Laplacian Keyboard (LK), a hierarchical framework that goes beyond the linear span. LK constructs a task-agnostic library of options from these eigenvectors, forming a behavior basis guaranteed to contain the optimal policy for any reward within the linear span. A meta-policy learns to stitch these options dynamically, enabling efficient learning of policies outside the original linear constraints. We establish theoretical bounds on zero-shot approximation error and demonstrate empirically that LK surpasses zero-shot solutions while achieving improved sample efficiency compared to standard RL methods.
Laplacian Representations for Decision-Time Planning
Feb 04, 2026Planning with a learned model remains a key challenge in model-based reinforcement learning (RL). In decision-time planning, state representations are critical as they must support local cost computation while preserving long-horizon structure. In this paper, we show that the Laplacian representation provides an effective latent space for planning by capturing state-space distances at multiple time scales. This representation preserves meaningful distances and naturally decomposes long-horizon problems into subgoals, also mitigating the compounding errors that arise over long prediction horizons. Building on these properties, we introduce ALPS, a hierarchical planning algorithm, and demonstrate that it outperforms commonly used baselines on a selection of offline goal-conditioned RL tasks from OGBench, a benchmark previously dominated by model-free methods.
DROGO: Default Representation Objective via Graph Optimization in Reinforcement Learning
Jan 30, 2026In computational reinforcement learning, the default representation (DR) and its principal eigenvector have been shown to be effective for a wide variety of applications, including reward shaping, count-based exploration, option discovery, and transfer. However, in prior investigations, the eigenvectors of the DR were computed by first approximating the DR matrix, and then performing an eigendecomposition. This procedure is computationally expensive and does not scale to high-dimensional spaces. In this paper, we derive an objective for directly approximating the principal eigenvector of the DR with a neural network. We empirically demonstrate the effectiveness of the objective in a number of environments, and apply the learned eigenvectors for reward shaping.
Universal computation is intrinsic to language model decoding
Jan 12, 2026Language models now provide an interface to express and often solve general problems in natural language, yet their ultimate computational capabilities remain a major topic of scientific debate. Unlike a formal computer, a language model is trained to autoregressively predict successive elements in human-generated text. We prove that chaining a language model's autoregressive output is sufficient to perform universal computation. That is, a language model can simulate the execution of any algorithm on any input. The challenge of eliciting desired computational behaviour can thus be reframed in terms of programmability: the ease of finding a suitable prompt. Strikingly, we demonstrate that even randomly initialized language models are capable of universal computation before training. This implies that training does not give rise to computational expressiveness -- rather, it improves programmability, enabling a natural language interface for accessing these intrinsic capabilities.
The World Is Bigger! A Computationally-Embedded Perspective on the Big World Hypothesis
Dec 29, 2025Continual learning is often motivated by the idea, known as the big world hypothesis, that "the world is bigger" than the agent. Recent problem formulations capture this idea by explicitly constraining an agent relative to the environment. These constraints lead to solutions in which the agent continually adapts to best use its limited capacity, rather than converging to a fixed solution. However, explicit constraints can be ad hoc, difficult to incorporate, and may limit the effectiveness of scaling up the agent's capacity. In this paper, we characterize a problem setting in which an agent, regardless of its capacity, is constrained by being embedded in the environment. In particular, we introduce a computationally-embedded perspective that represents an embedded agent as an automaton simulated within a universal (formal) computer. Such an automaton is always constrained; we prove that it is equivalent to an agent that interacts with a partially observable Markov decision process over a countably infinite state-space. We propose an objective for this setting, which we call interactivity, that measures an agent's ability to continually adapt its behaviour by learning new predictions. We then develop a model-based reinforcement learning algorithm for interactivity-seeking, and use it to construct a synthetic problem to evaluate continual learning capability. Our results show that deep nonlinear networks struggle to sustain interactivity, whereas deep linear networks sustain higher interactivity as capacity increases.
The Cell Must Go On: Agar.io for Continual Reinforcement Learning
May 23, 2025


Continual reinforcement learning (RL) concerns agents that are expected to learn continually, rather than converge to a policy that is then fixed for evaluation. Such an approach is well suited to environments the agent perceives as changing, which renders any static policy ineffective over time. The few simulators explicitly designed for empirical research in continual RL are often limited in scope or complexity, and it is now common for researchers to modify episodic RL environments by artificially incorporating abrupt task changes during interaction. In this paper, we introduce AgarCL, a research platform for continual RL that allows for a progression of increasingly sophisticated behaviour. AgarCL is based on the game Agar.io, a non-episodic, high-dimensional problem featuring stochastic, ever-evolving dynamics, continuous actions, and partial observability. Additionally, we provide benchmark results reporting the performance of DQN, PPO, and SAC in both the primary, challenging continual RL problem, and across a suite of smaller tasks within AgarCL, each of which isolates aspects of the full environment and allow us to characterize the challenges posed by different aspects of the game.
Reward-Aware Proto-Representations in Reinforcement Learning
May 22, 2025In recent years, the successor representation (SR) has attracted increasing attention in reinforcement learning (RL), and it has been used to address some of its key challenges, such as exploration, credit assignment, and generalization. The SR can be seen as representing the underlying credit assignment structure of the environment by implicitly encoding its induced transition dynamics. However, the SR is reward-agnostic. In this paper, we discuss a similar representation that also takes into account the reward dynamics of the problem. We study the default representation (DR), a recently proposed representation with limited theoretical (and empirical) analysis. Here, we lay some of the theoretical foundation underlying the DR in the tabular case by (1) deriving dynamic programming and (2) temporal-difference methods to learn the DR, (3) characterizing the basis for the vector space of the DR, and (4) formally extending the DR to the function approximation case through default features. Empirically, we analyze the benefits of the DR in many of the settings in which the SR has been applied, including (1) reward shaping, (2) option discovery, (3) exploration, and (4) transfer learning. Our results show that, compared to the SR, the DR gives rise to qualitatively different, reward-aware behaviour and quantitatively better performance in several settings.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
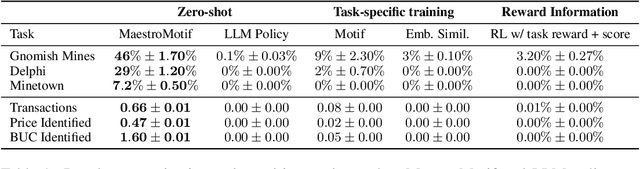

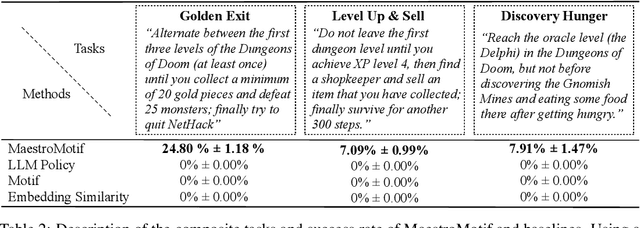
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
Plastic Learning with Deep Fourier Features
Oct 27, 2024Deep neural networks can struggle to learn continually in the face of non-stationarity. This phenomenon is known as loss of plasticity. In this paper, we identify underlying principles that lead to plastic algorithms. In particular, we provide theoretical results showing that linear function approximation, as well as a special case of deep linear networks, do not suffer from loss of plasticity. We then propose deep Fourier features, which are the concatenation of a sine and cosine in every layer, and we show that this combination provides a dynamic balance between the trainability obtained through linearity and the effectiveness obtained through the nonlinearity of neural networks. Deep networks composed entirely of deep Fourier features are highly trainable and sustain their trainability over the course of learning. Our empirical results show that continual learning performance can be drastically improved by replacing ReLU activations with deep Fourier features. These results hold for different continual learning scenarios (e.g., label noise, class incremental learning, pixel permutations) on all major supervised learning datasets used for continual learning research, such as CIFAR10, CIFAR100, and tiny-ImageNet.
Demystifying the Recency Heuristic in Temporal-Difference Learning
Jun 18, 2024



The recency heuristic in reinforcement learning is the assumption that stimuli that occurred closer in time to an acquired reward should be more heavily reinforced. The recency heuristic is one of the key assumptions made by TD($\lambda$), which reinforces recent experiences according to an exponentially decaying weighting. In fact, all other widely used return estimators for TD learning, such as $n$-step returns, satisfy a weaker (i.e., non-monotonic) recency heuristic. Why is the recency heuristic effective for temporal credit assignment? What happens when credit is assigned in a way that violates this heuristic? In this paper, we analyze the specific mathematical implications of adopting the recency heuristic in TD learning. We prove that any return estimator satisfying this heuristic: 1) is guaranteed to converge to the correct value function, 2) has a relatively fast contraction rate, and 3) has a long window of effective credit assignment, yet bounded worst-case variance. We also give a counterexample where on-policy, tabular TD methods violating the recency heuristic diverge. Our results offer some of the first theoretical evidence that credit assignment based on the recency heuristic facilitates learning.