 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROGO: Default Representation Objective via Graph Optimization in Reinforcement Learning
Jan 30, 2026In computational reinforcement learning, the default representation (DR) and its principal eigenvector have been shown to be effective for a wide variety of applications, including reward shaping, count-based exploration, option discovery, and transfer. However, in prior investigations, the eigenvectors of the DR were computed by first approximating the DR matrix, and then performing an eigendecomposition. This procedure is computationally expensive and does not scale to high-dimensional spaces. In this paper, we derive an objective for directly approximating the principal eigenvector of the DR with a neural network. We empirically demonstrate the effectiveness of the objective in a number of environments, and apply the learned eigenvectors for reward shaping.
Reward-Aware Proto-Representations in Reinforcement Learning
May 22, 2025In recent years, the successor representation (SR) has attracted increasing attention in reinforcement learning (RL), and it has been used to address some of its key challenges, such as exploration, credit assignment, and generalization. The SR can be seen as representing the underlying credit assignment structure of the environment by implicitly encoding its induced transition dynamics. However, the SR is reward-agnostic. In this paper, we discuss a similar representation that also takes into account the reward dynamics of the problem. We study the default representation (DR), a recently proposed representation with limited theoretical (and empirical) analysis. Here, we lay some of the theoretical foundation underlying the DR in the tabular case by (1) deriving dynamic programming and (2) temporal-difference methods to learn the DR, (3) characterizing the basis for the vector space of the DR, and (4) formally extending the DR to the function approximation case through default features. Empirically, we analyze the benefits of the DR in many of the settings in which the SR has been applied, including (1) reward shaping, (2) option discovery, (3) exploration, and (4) transfer learning. Our results show that, compared to the SR, the DR gives rise to qualitatively different, reward-aware behaviour and quantitatively better performance in several settings.
Exploiting Semantic Epsilon Greedy Exploration Strategy in Multi-Agent Reinforcement Learning
Jan 27, 2022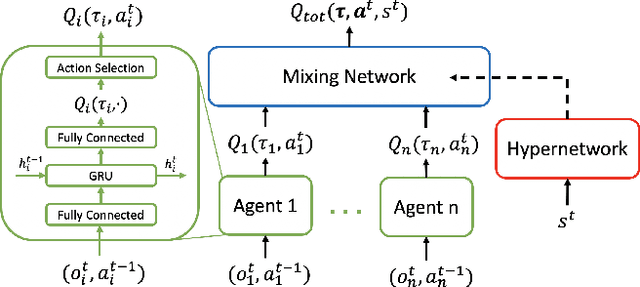

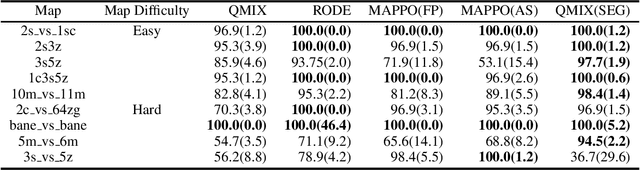
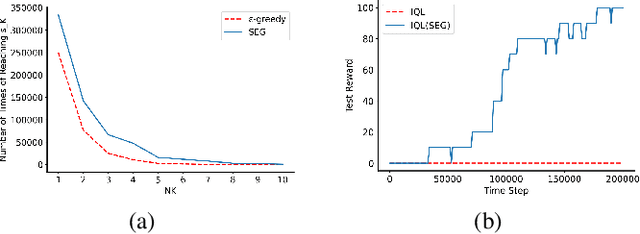
Multi-agent reinforcement learning (MARL) can model many real world applications. However, many MARL approaches rely on epsilon greedy for exploration, which may discourage visiting advantageous states in hard scenarios. In this paper, we propose a new approach QMIX(SEG) for tackling MARL. It makes use of the value function factorization method QMIX to train per-agent policies and a novel Semantic Epsilon Greedy (SEG) exploration strategy. SEG is a simple extension to the conventional epsilon greedy exploration strategy, yet it is experimentally shown to greatly improve the performance of MARL. We first cluster actions into groups of actions with similar effects and then use the groups in a bi-level epsilon greedy exploration hierarchy for action selection. We argue that SEG facilitates semantic exploration by exploring in the space of groups of actions, which have richer semantic meanings than atomic actions. Experiments show that QMIX(SEG) largely outperforms QMIX and leads to strong performance competitive with current state-of-the-art MARL approaches on the StarCraft Multi-Agent Challenge (SMAC) benchmark.