 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptWise: Online Learning for Cost-Aware Prompt Assignment in Generative Models
May 24, 2025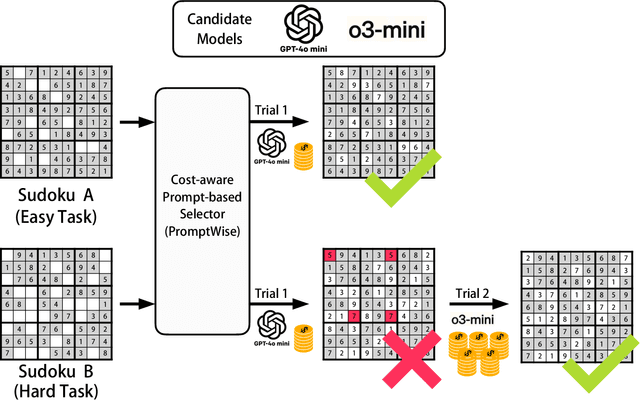



The rapid advancement of generative AI models has provided users with numerous options to address their prompts. When selecting a generative AI model for a given prompt, users should consider not only the performance of the chosen model but also its associated service cost. The principle guiding such consideration is to select the least expensive model among the available satisfactory options. However, existing model-selection approaches typically prioritize performance, overlooking pricing differences between models. In this paper, we introduce PromptWise, an online learning framework designed to assign a sequence of prompts to a group of large language models (LLMs) in a cost-effective manner. PromptWise strategically queries cheaper models first, progressing to more expensive options only if the lower-cost models fail to adequately address a given prompt. Through numerical experiments, we demonstrate PromptWise's effectiveness across various tasks, including puzzles of varying complexity and code generation/translation tasks. The results highlight that PromptWise consistently outperforms cost-unaware baseline methods, emphasizing that directly assigning prompts to the most expensive models can lead to higher costs and potentially lower average performance.
Reinforcing Question Answering Agents with Minimalist Policy Gradient Optimization
May 20, 2025Large Language Models (LLMs) have demonstrated remarkable versatility, due to the lack of factual knowledge, their application to Question Answering (QA) tasks remains hindered by hallucination. While Retrieval-Augmented Generation mitigates these issues by integrating external knowledge, existing approaches rely heavily on in-context learning, whose performance is constrained by the fundamental reasoning capabilities of LLMs. In this paper, we propose Mujica, a Multi-hop Joint Intelligence for Complex Question Answering, comprising a planner that decomposes questions into a directed acyclic graph of subquestions and a worker that resolves questions via retrieval and reasoning. Additionally, we introduce MyGO (Minimalist policy Gradient Optimization), a novel reinforcement learning method that replaces traditional policy gradient updates with Maximum Likelihood Estimation (MLE) by sampling trajectories from an asymptotically optimal policy. MyGO eliminates the need for gradient rescaling and reference models, ensuring stable and efficient training. Empirical results across multiple datasets demonstrate the effectiveness of Mujica-MyGO in enhancing multi-hop QA performance for various LLMs, offering a scalable and resource-efficient solution for complex QA tasks.
Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion
Nov 12, 2024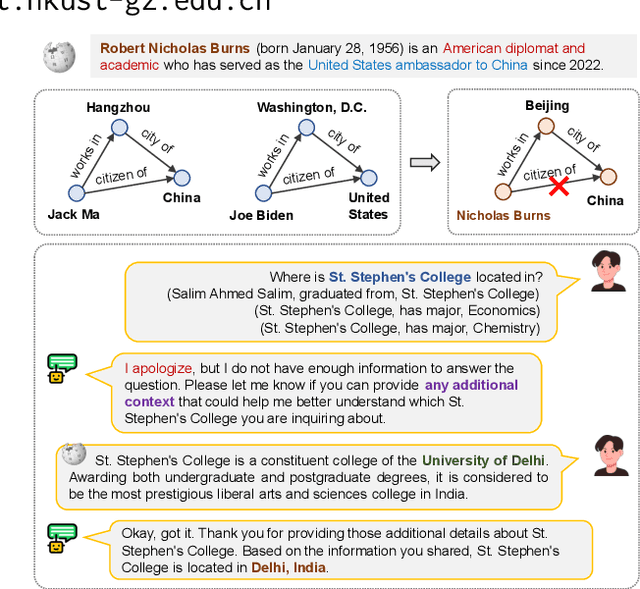
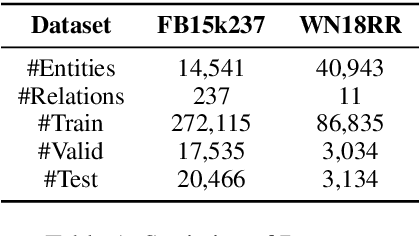

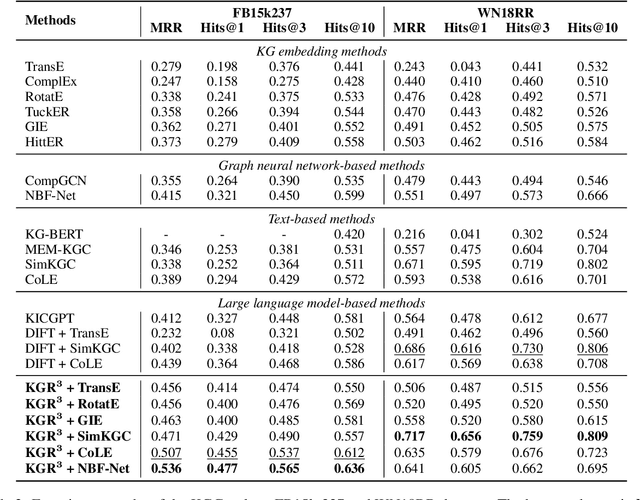
The Knowledge Graph Completion~(KGC) task aims to infer the missing entity from an incomplete triple. Existing embedding-based methods rely solely on triples in the KG, which is vulnerable to specious relation patterns and long-tail entities. On the other hand, text-based methods struggle with the semantic gap between KG triples and natural language. Apart from triples, entity contexts (e.g., labels, descriptions, aliases) also play a significant role in augmenting KGs. To address these limitations, we propose KGR3, a context-enriched framework for KGC. KGR3 is composed of three modules. Firstly, the Retrieval module gathers supporting triples from the KG, collects plausible candidate answers from a base embedding model, and retrieves context for each related entity. Then, the Reasoning module employs a large language model to generate potential answers for each query triple. Finally, the Re-ranking module combines candidate answers from the two modules mentioned above, and fine-tunes an LLM to provide the best answer. Extensive experiments on widely used datasets demonstrate that KGR3 consistently improves various KGC methods. Specifically, the best variant of KGR3 achieves absolute Hits@1 improvements of 12.3% and 5.6% on the FB15k237 and WN18RR datasets.
Context-aware Inductive Knowledge Graph Completion with Latent Type Constraints and Subgraph Reasoning
Oct 22, 2024



Inductive knowledge graph completion (KGC) aims to predict missing triples with unseen entities. Recent works focus on modeling reasoning paths between the head and tail entity as direct supporting evidence. However, these methods depend heavily on the existence and quality of reasoning paths, which limits their general applicability in different scenarios. In addition, we observe that latent type constraints and neighboring facts inherent in KGs are also vital in inferring missing triples. To effectively utilize all useful information in KGs, we introduce CATS, a novel context-aware inductive KGC solution. With sufficient guidance from proper prompts and supervised fine-tuning, CATS activates the strong semantic understanding and reasoning capabilities of large language models to assess the existence of query triples, which consist of two modules. First, the type-aware reasoning module evaluates whether the candidate entity matches the latent entity type as required by the query relation. Then, the subgraph reasoning module selects relevant reasoning paths and neighboring facts, and evaluates their correlation to the query triple. Experiment results on three widely used datasets demonstrate that CATS significantly outperforms state-of-the-art methods in 16 out of 18 transductive, inductive, and few-shot settings with an average absolute MRR improvement of 7.2%.
An Online Learning Approach to Prompt-based Selection of Generative Models
Oct 17, 2024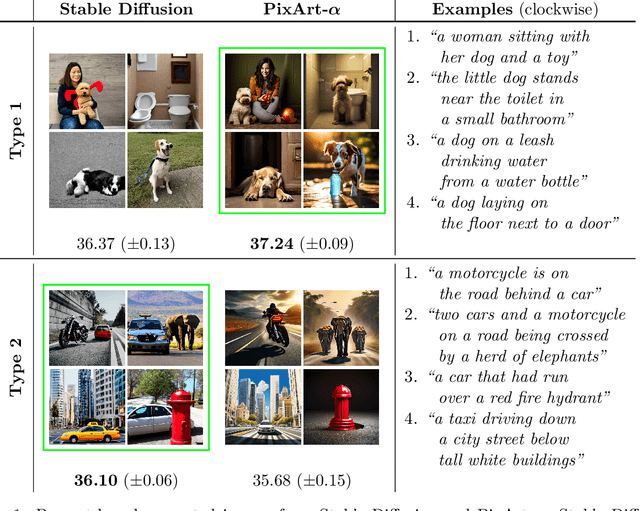



Selecting a sample generation scheme from multiple text-based generative models is typically addressed by choosing the model that maximizes an averaged evaluation score. However, this score-based selection overlooks the possibility that different models achieve the best generation performance for different types of text prompts. An online identification of the best generation model for various input prompts can reduce the costs associated with querying sub-optimal models. In this work, we explore the possibility of varying rankings of text-based generative models for different text prompts and propose an online learning framework to predict the best data generation model for a given input prompt. The proposed framework adapts the kernelized contextual bandit (CB) methodology to a CB setting with shared context variables across arms, utilizing the generated data to update a kernel-based function that predicts which model will achieve the highest score for unseen text prompts. Additionally, we apply random Fourier features (RFF) to the kernelized CB algorithm to accelerate the online learning process and establish a $\widetilde{\mathcal{O}}(\sqrt{T})$ regret bound for the proposed RFF-based CB algorithm over T iterations. Our numerical experiments on real and simulated text-to-image and image-to-text generative models show RFF-UCB performs successfully in identifying the best generation model across different sample types.
An Optimism-based Approach to Online Evaluation of Generative Models
Jun 11, 2024



Existing frameworks for evaluating and comparing generative models typically target an offline setting, where the evaluator has access to full batches of data produced by the models. However, in many practical scenarios, the goal is to identify the best model using the fewest generated samples to minimize the costs of querying data from the models. Such an online comparison is challenging with current offline assessment methods. In this work, we propose an online evaluation framework to find the generative model that maximizes a standard assessment score among a group of available models. Our method uses an optimism-based multi-armed bandit framework to identify the model producing data with the highest evaluation score, quantifying the quality and diversity of generated data. Specifically, we study the online assessment of generative models based on the Fr\'echet Inception Distance (FID) and Inception Score (IS) metrics and propose the FID-UCB and IS-UCB algorithms leveraging the upper confidence bound approach in online learning. We prove sub-linear regret bounds for these algorithms and present numerical results on standard image datasets, demonstrating their effectiveness in identifying the score-maximizing generative model.
The Integration of Semantic and Structural Knowledge in Knowledge Graph Entity Typing
Apr 12, 2024

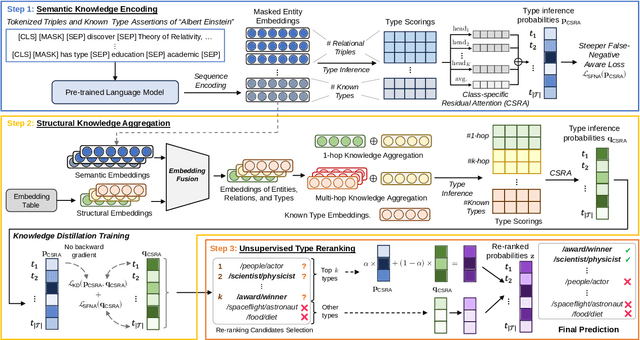

The Knowledge Graph Entity Typing (KGET) task aims to predict missing type annotations for entities in knowledge graphs. Recent works only utilize the \textit{\textbf{structural knowledge}} in the local neighborhood of entities, disregarding \textit{\textbf{semantic knowledge}} in the textual representations of entities, relations, and types that are also crucial for type inference. Additionally, we observe that the interaction between semantic and structural knowledge can be utilized to address the false-negative problem. In this paper, we propose a novel \textbf{\underline{S}}emantic and \textbf{\underline{S}}tructure-aware KG \textbf{\underline{E}}ntity \textbf{\underline{T}}yping~{(SSET)} framework, which is composed of three modules. First, the \textit{Semantic Knowledge Encoding} module encodes factual knowledge in the KG with a Masked Entity Typing task. Then, the \textit{Structural Knowledge Aggregation} module aggregates knowledge from the multi-hop neighborhood of entities to infer missing types. Finally, the \textit{Unsupervised Type Re-ranking} module utilizes the inference results from the two models above to generate type predictions that are robust to false-negative samples. Extensive experiments show that SSET significantly outperforms existing state-of-the-art methods.
An Information Theoretic Approach to Interaction-Grounded Learning
Jan 10, 2024Reinforcement learning (RL) problems where the learner attempts to infer an unobserved reward from some feedback variables have been studied in several recent papers. The setting of Interaction-Grounded Learning (IGL) is an example of such feedback-based reinforcement learning tasks where the learner optimizes the return by inferring latent binary rewards from the interaction with the environment. In the IGL setting, a relevant assumption used in the RL literature is that the feedback variable $Y$ is conditionally independent of the context-action $(X,A)$ given the latent reward $R$. In this work, we propose Variational Information-based IGL (VI-IGL) as an information-theoretic method to enforce the conditional independence assumption in the IGL-based RL problem. The VI-IGL framework learns a reward decoder using an information-based objective based on the conditional mutual information (MI) between the context-action $(X,A)$ and the feedback variable $Y$ observed from the environment. To estimate and optimize the information-based terms for the continuous random variables in the RL problem, VI-IGL leverages the variational representation of mutual information and results in a min-max optimization problem. Furthermore, we extend the VI-IGL framework to general $f$-Information measures in the information theory literature, leading to the generalized $f$-VI-IGL framework to address the RL problem under the IGL condition. Finally, we provide the empirical results of applying the VI-IGL method to several reinforcement learning settings, which indicate an improved performance in comparison to the previous IGL-based RL algorithm.
Provably Efficient CVaR RL in Low-rank MDPs
Nov 20, 2023We study risk-sensitive Reinforcement Learning (RL), where we aim to maximize the Conditional Value at Risk (CVaR) with a fixed risk tolerance $\tau$. Prior theoretical work studying risk-sensitive RL focuses on the tabular Markov Decision Processes (MDPs) setting. To extend CVaR RL to settings where state space is large, function approximation must be deployed. We study CVaR RL in low-rank MDPs with nonlinear function approximation. Low-rank MDPs assume the underlying transition kernel admits a low-rank decomposition, but unlike prior linear models, low-rank MDPs do not assume the feature or state-action representation is known. We propose a novel Upper Confidence Bound (UCB) bonus-driven algorithm to carefully balance the interplay between exploration, exploitation, and representation learning in CVaR RL. We prove that our algorithm achieves a sample complexity of $\tilde{O}\left(\frac{H^7 A^2 d^4}{\tau^2 \epsilon^2}\right)$ to yield an $\epsilon$-optimal CVaR, where $H$ is the length of each episode, $A$ is the capacity of action space, and $d$ is the dimension of representations. Computational-wise, we design a novel discretized Least-Squares Value Iteration (LSVI) algorithm for the CVaR objective as the planning oracle and show that we can find the near-optimal policy in a polynomial running time with a Maximum Likelihood Estimation oracle. To our knowledge, this is the first provably efficient CVaR RL algorithm in low-rank MDPs.
Beyond the Gates of Euclidean Space: Temporal-Discrimination-Fusions and Attention-based Graph Neural Network for Human Activity Recognition
Jun 10, 2022
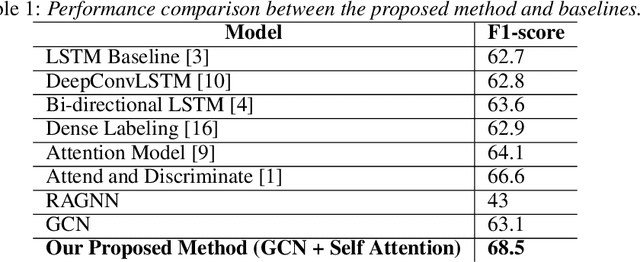
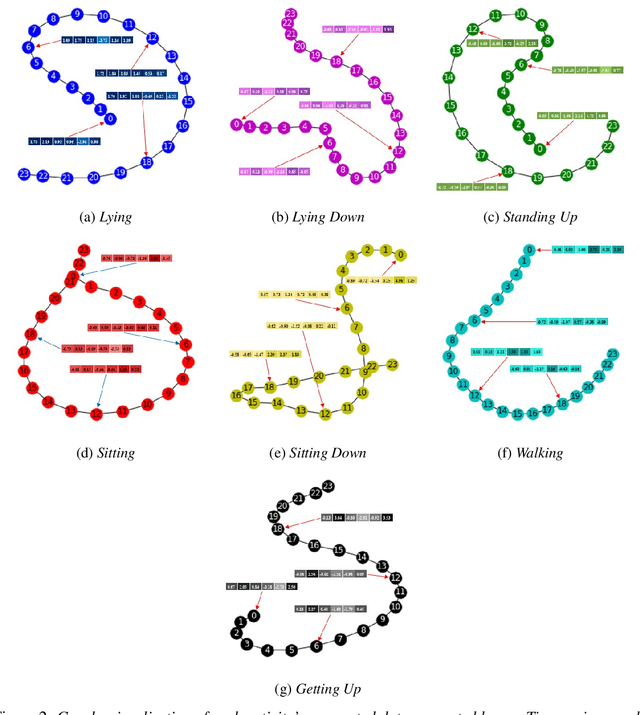

Human activity recognition (HAR) through wearable devices has received much interest due to its numerous applications in fitness tracking, wellness screening, and supported living. As a result, we have seen a great deal of work in this field. Traditional deep learning (DL) has set a state of the art performance for HAR domain. However, it ignores the data's structure and the association between consecutive time stamps. To address this constraint, we offer an approach based on Graph Neural Networks (GNNs) for structuring the input representation and exploiting the relations among the samples. However, even when using a simple graph convolution network to eliminate this shortage, there are still several limiting factors, such as inter-class activities issues, skewed class distribution, and a lack of consideration for sensor data priority, all of which harm the HAR model's performance. To improve the current HAR model's performance, we investigate novel possibilities within the framework of graph structure to achieve highly discriminated and rich activity features. We propose a model for (1) time-series-graph module that converts raw data from HAR dataset into graphs; (2) Graph Convolutional Neural Networks (GCNs) to discover local dependencies and correlations between neighboring nodes; and (3) self-attention GNN encoder to identify sensors interactions and data priorities. To the best of our knowledge, this is the first work for HAR, which introduces a GNN-based approach that incorporates both the GCN and the attention mechanism. By employing a uniform evaluation method, our framework significantly improves the performance on hospital patient's activities dataset comparatively considered other state of the art baseline methods.