 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Pretraining on Encrypted Synthetic Data for Privacy-Preserving LLMs
Jan 12, 2026Preserving privacy in sensitive data while pretraining large language models on small, domain-specific corpora presents a significant challenge. In this work, we take an exploratory step toward privacy-preserving continual pretraining by proposing an entity-based framework that synthesizes encrypted training data to protect personally identifiable information (PII). Our approach constructs a weighted entity graph to guide data synthesis and applies deterministic encryption to PII entities, enabling LLMs to encode new knowledge through continual pretraining while granting authorized access to sensitive data through decryption keys. Our results on limited-scale datasets demonstrate that our pretrained models outperform base models and ensure PII security, while exhibiting a modest performance gap compared to models trained on unencrypted synthetic data. We further show that increasing the number of entities and leveraging graph-based synthesis improves model performance, and that encrypted models retain instruction-following capabilities with long retrieved contexts. We discuss the security implications and limitations of deterministic encryption, positioning this work as an initial investigation into the design space of encrypted data pretraining for privacy-preserving LLMs. Our code is available at https://github.com/DataArcTech/SoE.
GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation
Sep 26, 2025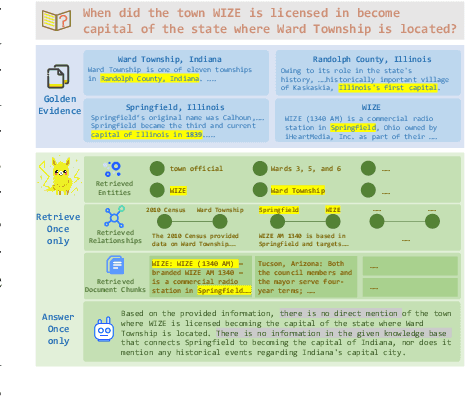
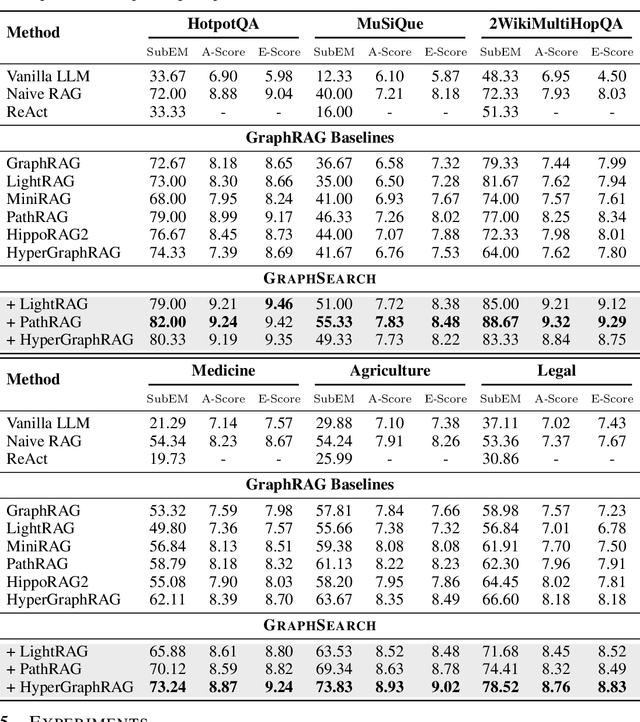

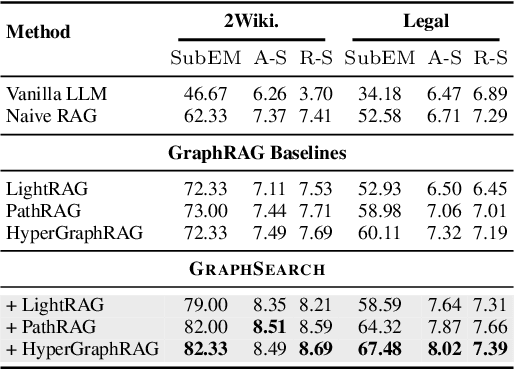
Graph Retrieval-Augmented Generation (GraphRAG) enhances factual reasoning in LLMs by structurally modeling knowledge through graph-based representations. However, existing GraphRAG approaches face two core limitations: shallow retrieval that fails to surface all critical evidence, and inefficient utilization of pre-constructed structural graph data, which hinders effective reasoning from complex queries. To address these challenges, we propose \textsc{GraphSearch}, a novel agentic deep searching workflow with dual-channel retrieval for GraphRAG. \textsc{GraphSearch} organizes the retrieval process into a modular framework comprising six modules, enabling multi-turn interactions and iterative reasoning. Furthermore, \textsc{GraphSearch} adopts a dual-channel retrieval strategy that issues semantic queries over chunk-based text data and relational queries over structural graph data, enabling comprehensive utilization of both modalities and their complementary strengths. Experimental results across six multi-hop RAG benchmarks demonstrate that \textsc{GraphSearch} consistently improves answer accuracy and generation quality over the traditional strategy, confirming \textsc{GraphSearch} as a promising direction for advancing graph retrieval-augmented generation.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025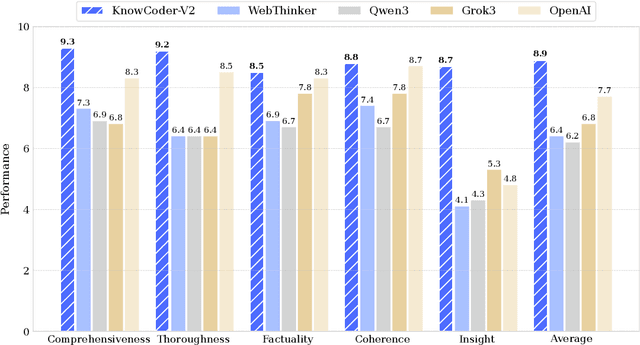
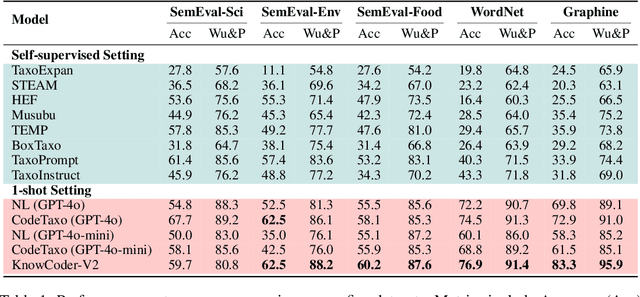
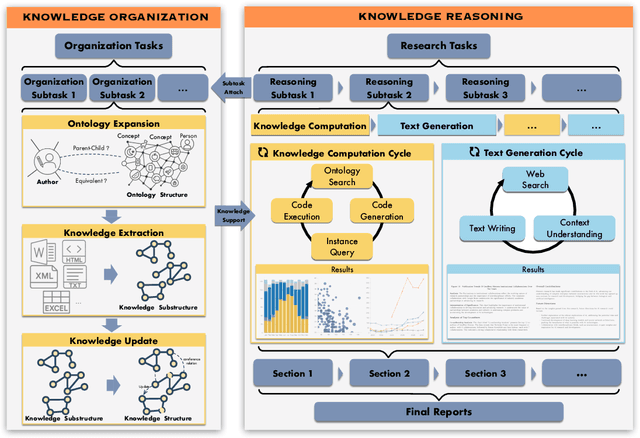
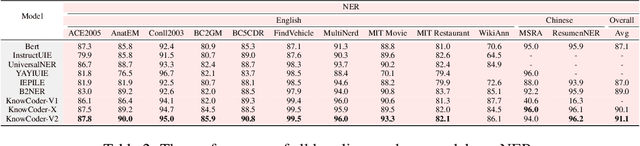
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
Select2Reason: Efficient Instruction-Tuning Data Selection for Long-CoT Reasoning
May 22, 2025A practical approach to activate long chain-of-thoughts reasoning ability in pre-trained large language models is to perform supervised fine-tuning on instruction datasets synthesized by strong Large Reasoning Models such as DeepSeek-R1, offering a cost-effective alternative to reinforcement learning. However, large-scale instruction sets with more than 100k samples incur significant training overhead, while effective strategies for automatic long-CoT instruction selection still remain unexplored. In this work, we propose Select2Reason, a novel and efficient instruction-tuning data selection framework for long-CoT reasoning. From the perspective of emergence of rethinking behaviors like self-correction and backtracking, we investigate common metrics that may determine the quality of long-CoT reasoning instructions. Select2Reason leverages a quantifier to estimate difficulty of question and jointly incorporates a reasoning trace length-based heuristic through a weighted scheme for ranking to prioritize high-utility examples. Empirical results on OpenR1-Math-220k demonstrate that fine-tuning LLM on only 10% of the data selected by Select2Reason achieves performance competitive with or superior to full-data tuning and open-source baseline OpenR1-Qwen-7B across three competition-level and six comprehensive mathematical benchmarks. Further experiments highlight the scalability in varying data size, efficiency during inference, and its adaptability to other instruction pools with minimal cost.
Fractal Graph Contrastive Learning
May 16, 2025While Graph Contrastive Learning (GCL) has attracted considerable attention in the field of graph self-supervised learning, its performance heavily relies on data augmentations that are expected to generate semantically consistent positive pairs. Existing strategies typically resort to random perturbations or local structure preservation, yet lack explicit control over global structural consistency between augmented views. To address this limitation, we propose Fractal Graph Contrastive Learning (FractalGCL), a theory-driven framework that leverages fractal self-similarity to enforce global topological coherence. FractalGCL introduces two key innovations: a renormalisation-based augmentation that generates structurally aligned positive views via box coverings; and a fractal-dimension-aware contrastive loss that aligns graph embeddings according to their fractal dimensions. While combining the two innovations markedly boosts graph-representation quality, it also adds non-trivial computational overhead. To mitigate the computational overhead of fractal dimension estimation, we derive a one-shot estimator by proving that the dimension discrepancy between original and renormalised graphs converges weakly to a centred Gaussian distribution. This theoretical insight enables a reduction in dimension computation cost by an order of magnitude, cutting overall training time by approximately 61%. The experiments show that FractalGCL not only delivers state-of-the-art results on standard benchmarks but also outperforms traditional baselines on traffic networks by an average margin of about remarkably 7%. Codes are available at (https://anonymous.4open.science/r/FractalGCL-0511).
Synthesize-on-Graph: Knowledgeable Synthetic Data Generation for Continue Pre-training of Large Language Models
May 02, 2025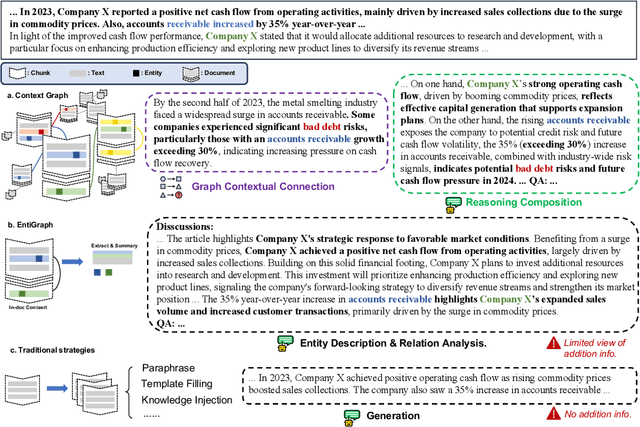
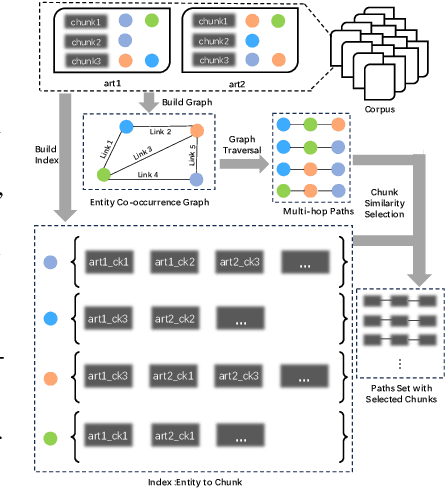

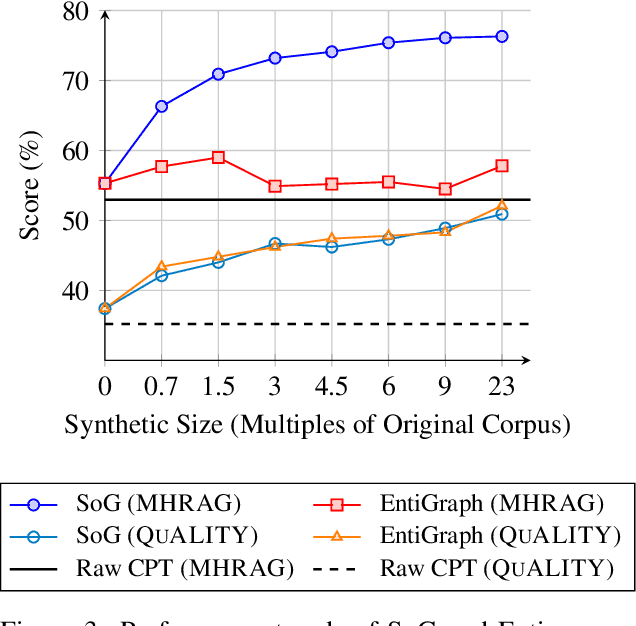
Large Language Models (LLMs) have achieved remarkable success but remain data-inefficient, especially when learning from small, specialized corpora with limited and proprietary data. Existing synthetic data generation methods for continue pre-training focus on intra-document content and overlook cross-document knowledge associations, limiting content diversity and depth. We propose Synthetic-on-Graph (SoG), a synthetic data generation framework that incorporates cross-document knowledge associations for efficient corpus expansion. SoG constructs a context graph by extracting entities and concepts from the original corpus, representing cross-document associations, and employing a graph walk strategy for knowledge-associated sampling. This enhances synthetic data diversity and coherence, enabling models to learn complex knowledge structures and handle rare knowledge. To further improve synthetic data quality, we integrate Chain-of-Thought (CoT) and Contrastive Clarifying (CC) synthetic, enhancing reasoning processes and discriminative power. Experiments show that SoG outperforms the state-of-the-art (SOTA) method in a multi-hop document Q&A dataset while performing comparably to the SOTA method on the reading comprehension task datasets, which also underscores the better generalization capability of SoG. Our work advances synthetic data generation and provides practical solutions for efficient knowledge acquisition in LLMs, especially in domains with limited data availability.
LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data
Feb 18, 2025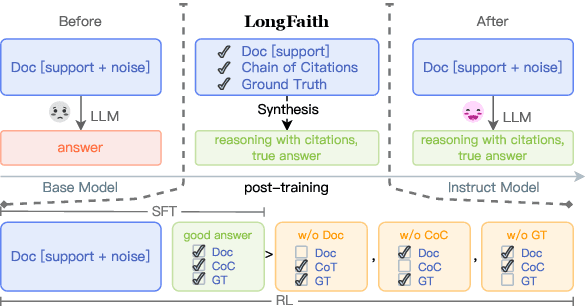
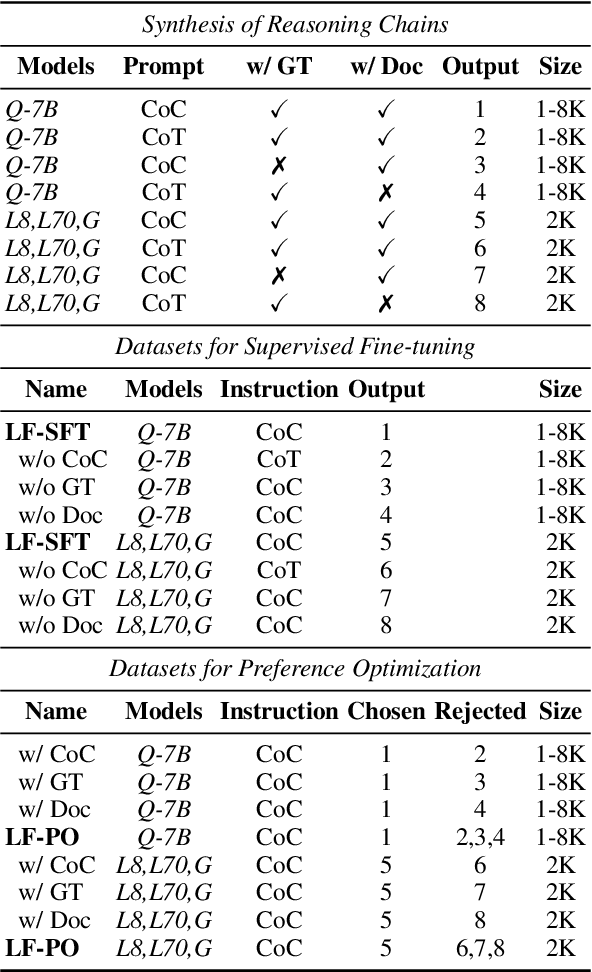
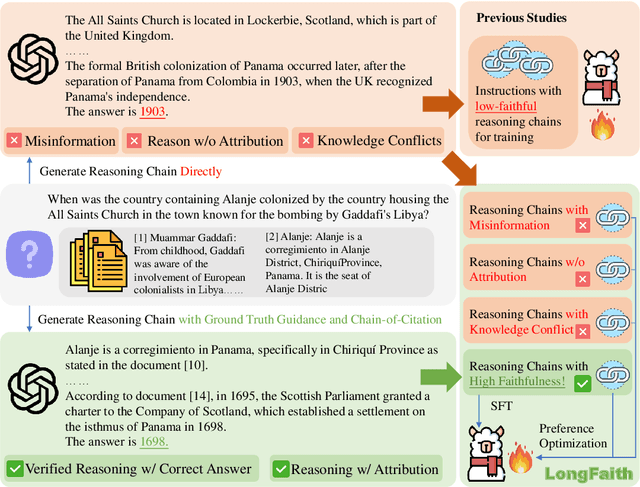
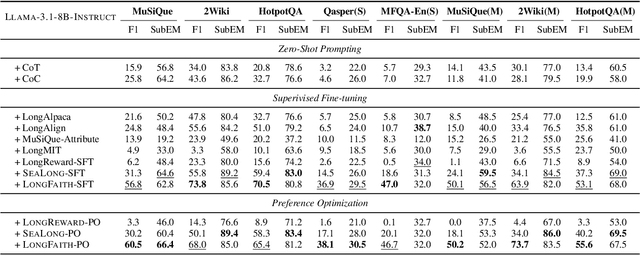
Despite the growing development of long-context large language models (LLMs), data-centric approaches relying on synthetic data have been hindered by issues related to faithfulness, which limit their effectiveness in enhancing model performance on tasks such as long-context reasoning and question answering (QA). These challenges are often exacerbated by misinformation caused by lack of verification, reasoning without attribution, and potential knowledge conflicts. We propose LongFaith, a novel pipeline for synthesizing faithful long-context reasoning instruction datasets. By integrating ground truth and citation-based reasoning prompts, we eliminate distractions and improve the accuracy of reasoning chains, thus mitigating the need for costly verification processes. We open-source two synthesized datasets, LongFaith-SFT and LongFaith-PO, which systematically address multiple dimensions of faithfulness, including verified reasoning, attribution, and contextual grounding. Extensive experiments on multi-hop reasoning datasets and LongBench demonstrate that models fine-tuned on these datasets significantly improve performance. Our ablation studies highlight the scalability and adaptability of the LongFaith pipeline, showcasing its broad applicability in developing long-context LLMs.
A Survey on LLM-as-a-Judge
Nov 23, 2024Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey of LLM-as-a-Judge, addressing the core question: How can reliable LLM-as-a-Judge systems be built? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.
Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion
Nov 12, 2024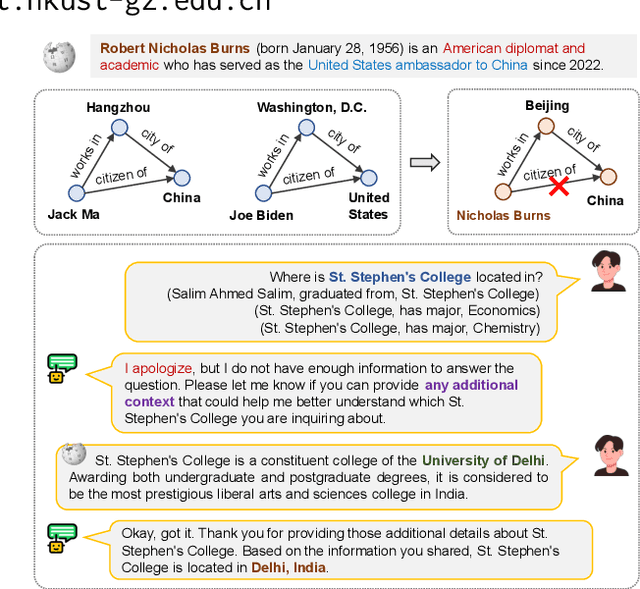
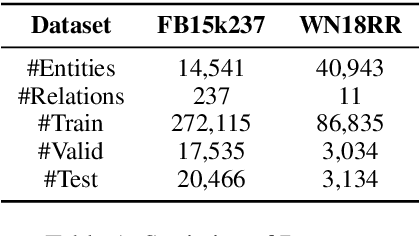

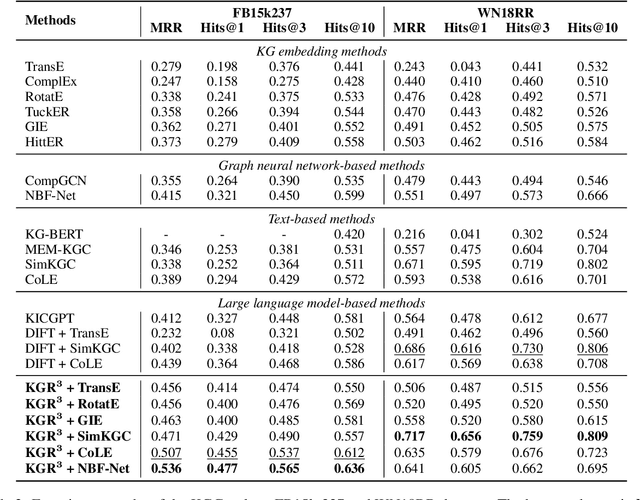
The Knowledge Graph Completion~(KGC) task aims to infer the missing entity from an incomplete triple. Existing embedding-based methods rely solely on triples in the KG, which is vulnerable to specious relation patterns and long-tail entities. On the other hand, text-based methods struggle with the semantic gap between KG triples and natural language. Apart from triples, entity contexts (e.g., labels, descriptions, aliases) also play a significant role in augmenting KGs. To address these limitations, we propose KGR3, a context-enriched framework for KGC. KGR3 is composed of three modules. Firstly, the Retrieval module gathers supporting triples from the KG, collects plausible candidate answers from a base embedding model, and retrieves context for each related entity. Then, the Reasoning module employs a large language model to generate potential answers for each query triple. Finally, the Re-ranking module combines candidate answers from the two modules mentioned above, and fine-tunes an LLM to provide the best answer. Extensive experiments on widely used datasets demonstrate that KGR3 consistently improves various KGC methods. Specifically, the best variant of KGR3 achieves absolute Hits@1 improvements of 12.3% and 5.6% on the FB15k237 and WN18RR datasets.
Context-aware Inductive Knowledge Graph Completion with Latent Type Constraints and Subgraph Reasoning
Oct 22, 2024



Inductive knowledge graph completion (KGC) aims to predict missing triples with unseen entities. Recent works focus on modeling reasoning paths between the head and tail entity as direct supporting evidence. However, these methods depend heavily on the existence and quality of reasoning paths, which limits their general applicability in different scenarios. In addition, we observe that latent type constraints and neighboring facts inherent in KGs are also vital in inferring missing triples. To effectively utilize all useful information in KGs, we introduce CATS, a novel context-aware inductive KGC solution. With sufficient guidance from proper prompts and supervised fine-tuning, CATS activates the strong semantic understanding and reasoning capabilities of large language models to assess the existence of query triples, which consist of two modules. First, the type-aware reasoning module evaluates whether the candidate entity matches the latent entity type as required by the query relation. Then, the subgraph reasoning module selects relevant reasoning paths and neighboring facts, and evaluates their correlation to the query triple. Experiment results on three widely used datasets demonstrate that CATS significantly outperforms state-of-the-art methods in 16 out of 18 transductive, inductive, and few-shot settings with an average absolute MRR improvement of 7.2%.