 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Reinforcement Learning for Long-Horizon Tool-Using Agents: A Comprehensive Recipe
Mar 23, 2026Reinforcement Learning (RL) is essential for evolving Large Language Models (LLMs) into autonomous agents capable of long-horizon planning, yet a practical recipe for scaling RL in complex, multi-turn environments remains elusive. This paper presents a systematic empirical study using TravelPlanner, a challenging testbed requiring tool orchestration to satisfy multifaceted constraints. We decompose the agentic RL design space along 5 axes: reward shaping, model scaling, data composition, algorithm selection, and environmental stability. Our controlled experiments yield 7 key takeaways, e.g., (1) reward and algorithm choices are scale-dependent as smaller models benefit from staged rewards and enhanced exploration, whereas larger models converge efficiently with simpler dense rewards, (2) ~ 1K training samples with a balanced difficulty mixture mark a sweet spot for both in-domain and out-of-domain performance, and (3) environmental stability is critical to prevent policy degradation. Based on our distilled recipe, our RL-trained models achieve state-of-the-art performance on TravelPlanner, significantly outperforming leading LLMs.
VSearcher: Long-Horizon Multimodal Search Agent via Reinforcement Learning
Mar 03, 2026Large models are increasingly becoming autonomous agents that interact with real-world environments and use external tools to augment their static capabilities. However, most recent progress has focused on text-only large language models, which are limited to a single modality and therefore have narrower application scenarios. On the other hand, multimodal large models, while offering stronger perceptual capabilities, remain limited to static knowledge and lack the ability to access and leverage up-to-date web information. In this paper, we propose VSearcher, turning static multimodal model into multimodal search agent capable of long-horizon, multi-turn tool use in real-world web environments, including text search, image search, and web browsing, via reinforcement learning. Specifically, we introduce Iterative Injection Data Synthesis pipeline to generate large-scale, complex multimodal QA questions, which are further filtered with comprehensive metrics to ensure high quality and sufficient difficulty. We then adopt an SFT-then-RL training pipeline to turn base multimodal models to agent capable of multi-turn tool calling in real-world web environments. Besides, we propose a multimodal search benchmark MM-SearchExam dedicated to evaluating search capabilities of multimodal search agents, which proves highly challenging for recent proprietary models. Extensive evaluations across multiple multimodal search benchmarks reveal effectiveness of our method. VSearcher achieves superior performance compared to recent multimodal search agents and even surpasses several proprietary models on multimodal web search tasks.
Janus-Q: End-to-End Event-Driven Trading via Hierarchical-Gated Reward Modeling
Feb 23, 2026Financial market movements are often driven by discrete financial events conveyed through news, whose impacts are heterogeneous, abrupt, and difficult to capture under purely numerical prediction objectives. These limitations have motivated growing interest in using textual information as the primary source of trading signals in learning-based systems. Two key challenges hinder existing approaches: (1) the absence of large-scale, event-centric datasets that jointly model news semantics and statistically grounded market reactions, and (2) the misalignment between language model reasoning and financially valid trading behavior under dynamic market conditions. To address these challenges, we propose Janus-Q, an end-to-end event-driven trading framework that elevates financial news events from auxiliary signals to primary decision units. Janus-Q unifies event-centric data construction and model optimization under a two-stage paradigm. Stage I focuses on event-centric data construction, building a large-scale financial news event dataset comprising 62,400 articles annotated with 10 fine-grained event types, associated stocks, sentiment labels, and event-driven cumulative abnormal return (CAR). Stage II performs decision-oriented fine-tuning, combining supervised learning with reinforcement learning guided by a Hierarchical Gated Reward Model (HGRM), which explicitly captures trade-offs among multiple trading objectives. Extensive experiments demonstrate that Janus-Q achieves more consistent, interpretable, and profitable trading decisions than market indices and LLM baselines, improving the Sharpe Ratio by up to 102.0% while increasing direction accuracy by over 17.5% compared to the strongest competing strategies.
ReAttn: Improving Attention-based Re-ranking via Attention Re-weighting
Feb 23, 2026The strong capabilities of recent Large Language Models (LLMs) have made them highly effective for zero-shot re-ranking task. Attention-based re-ranking methods, which derive relevance scores directly from attention weights, offer an efficient and interpretable alternative to generation-based re-ranking methods. However, they still face two major limitations. First, attention signals are highly concentrated a small subset of tokens within a few documents, making others indistinguishable. Second, attention often overemphasizes phrases lexically similar to the query, yielding biased rankings that irrelevant documents with mere lexical resemblance are regarded as relevant. In this paper, we propose \textbf{ReAttn}, a post-hoc re-weighting strategy for attention-based re-ranking methods. It first compute the cross-document IDF weighting to down-weight attention on query-overlapping tokens that frequently appear across the candidate documents, reducing lexical bias and emphasizing distinctive terms. It then employs entropy-based regularization to mitigate over-concentrated attention, encouraging a more balanced distribution across informative tokens. Both adjustments operate directly on existing attention weights without additional training or supervision. Extensive experiments demonstrate the effectiveness of our method.
Learning Discriminative and Generalizable Anomaly Detector for Dynamic Graph with Limited Supervision
Feb 23, 2026Dynamic graph anomaly detection (DGAD) is critical for many real-world applications but remains challenging due to the scarcity of labeled anomalies. Existing methods are either unsupervised or semi-supervised: unsupervised methods avoid the need for labeled anomalies but often produce ambiguous boundary, whereas semi-supervised methods can overfit to the limited labeled anomalies and generalize poorly to unseen anomalies. To address this gap, we consider a largely underexplored problem in DGAD: learning a discriminative boundary from normal/unlabeled data, while leveraging limited labeled anomalies \textbf{when available} without sacrificing generalization to unseen anomalies. To this end, we propose an effective, generalizable, and model-agnostic framework with three main components: (i) residual representation encoding that capture deviations between current interactions and their historical context, providing anomaly-relevant signals; (ii) a restriction loss that constrain the normal representations within an interval bounded by two co-centered hyperspheres, ensuring consistent scales while keeping anomalies separable; (iii) a bi-boundary optimization strategy that learns a discriminative and robust boundary using the normal log-likelihood distribution modeled by a normalizing flow. Extensive experiments demonstrate the superiority of our framework across diverse evaluation settings.
QuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025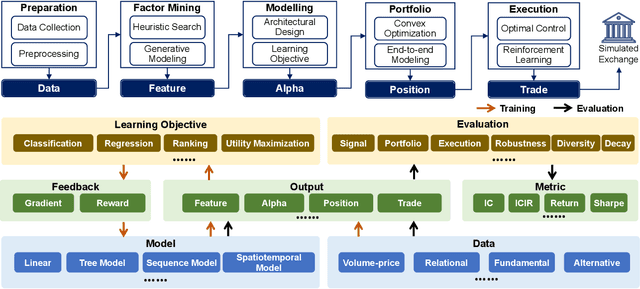



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
Guided Learning: Lubricating End-to-End Modeling for Multi-stage Decision-making
Nov 15, 2024


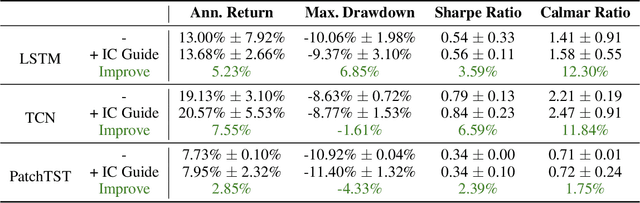
Multi-stage decision-making is crucial in various real-world artificial intelligence applications, including recommendation systems, autonomous driving, and quantitative investment systems. In quantitative investment, for example, the process typically involves several sequential stages such as factor mining, alpha prediction, portfolio optimization, and sometimes order execution. While state-of-the-art end-to-end modeling aims to unify these stages into a single global framework, it faces significant challenges: (1) training such a unified neural network consisting of multiple stages between initial inputs and final outputs often leads to suboptimal solutions, or even collapse, and (2) many decision-making scenarios are not easily reducible to standard prediction problems. To overcome these challenges, we propose Guided Learning, a novel methodological framework designed to enhance end-to-end learning in multi-stage decision-making. We introduce the concept of a ``guide'', a function that induces the training of intermediate neural network layers towards some phased goals, directing gradients away from suboptimal collapse. For decision scenarios lacking explicit supervisory labels, we incorporate a utility function that quantifies the ``reward'' of the throughout decision. Additionally, we explore the connections between Guided Learning and classic machine learning paradigms such as supervised, unsupervised, semi-supervised, multi-task, and reinforcement learning. Experiments on quantitative investment strategy building demonstrate that guided learning significantly outperforms both traditional stage-wise approaches and existing end-to-end methods.
Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion
Nov 12, 2024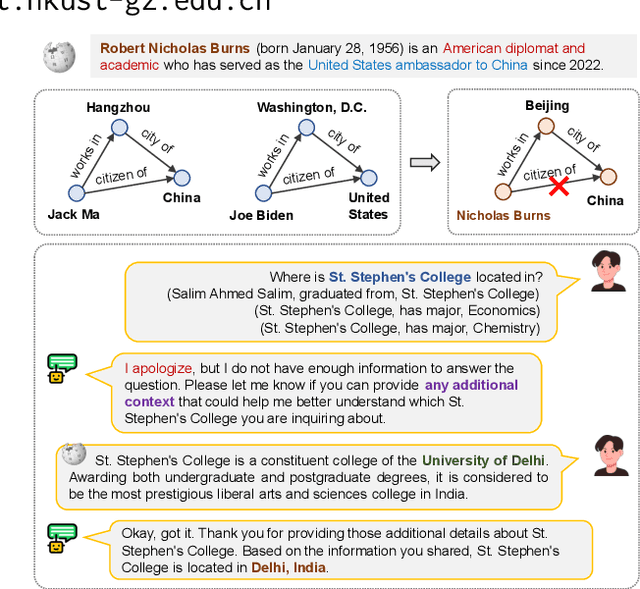
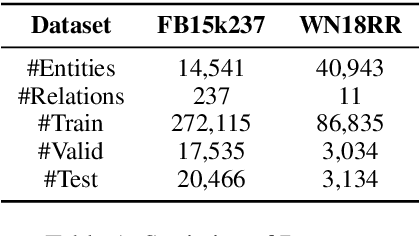

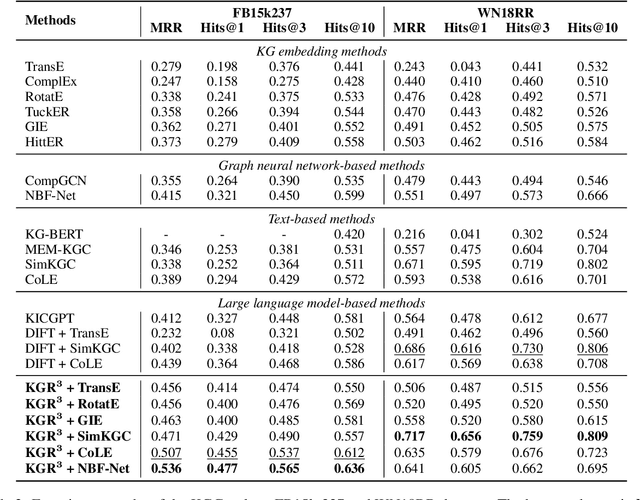
The Knowledge Graph Completion~(KGC) task aims to infer the missing entity from an incomplete triple. Existing embedding-based methods rely solely on triples in the KG, which is vulnerable to specious relation patterns and long-tail entities. On the other hand, text-based methods struggle with the semantic gap between KG triples and natural language. Apart from triples, entity contexts (e.g., labels, descriptions, aliases) also play a significant role in augmenting KGs. To address these limitations, we propose KGR3, a context-enriched framework for KGC. KGR3 is composed of three modules. Firstly, the Retrieval module gathers supporting triples from the KG, collects plausible candidate answers from a base embedding model, and retrieves context for each related entity. Then, the Reasoning module employs a large language model to generate potential answers for each query triple. Finally, the Re-ranking module combines candidate answers from the two modules mentioned above, and fine-tunes an LLM to provide the best answer. Extensive experiments on widely used datasets demonstrate that KGR3 consistently improves various KGC methods. Specifically, the best variant of KGR3 achieves absolute Hits@1 improvements of 12.3% and 5.6% on the FB15k237 and WN18RR datasets.
Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Nov 09, 2024



As large language models become increasingly prevalent in the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. However, existing finance benchmarks often suffer from limited language and task coverage, as well as challenges such as low-quality datasets and inadequate adaptability for LLM evaluation. To address these limitations, we propose "Golden Touchstone", the first comprehensive bilingual benchmark for financial LLMs, which incorporates representative datasets from both Chinese and English across eight core financial NLP tasks. Developed from extensive open source data collection and industry-specific demands, this benchmark includes a variety of financial tasks aimed at thoroughly assessing models' language understanding and generation capabilities. Through comparative analysis of major models on the benchmark, such as GPT-4o Llama3, FinGPT and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-sourced Touchstone-GPT, a financial LLM trained through continual pre-training and financial instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks.This research not only provides the financial large language models with a practical evaluation tool but also guides the development and optimization of future research. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at \url{https://github.com/IDEA-FinAI/Golden-Touchstone}, contributing to the ongoing evolution of FinLLMs and fostering further research in this critical area.
ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
Sep 05, 2024



Automatic chart understanding is crucial for content comprehension and document parsing. Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in chart understanding through domain-specific alignment and fine-tuning. However, the application of alignment training within the chart domain is still underexplored. To address this, we propose ChartMoE, which employs the mixture of expert (MoE) architecture to replace the traditional linear projector to bridge the modality gap. Specifically, we train multiple linear connectors through distinct alignment tasks, which are utilized as the foundational initialization parameters for different experts. Additionally, we introduce ChartMoE-Align, a dataset with over 900K chart-table-JSON-code quadruples to conduct three alignment tasks (chart-table/JSON/code). Combined with the vanilla connector, we initialize different experts in four distinct ways and adopt high-quality knowledge learning to further refine the MoE connector and LLM parameters. Extensive experiments demonstrate the effectiveness of the MoE connector and our initialization strategy, e.g., ChartMoE improves the accuracy of the previous state-of-the-art from 80.48% to 84.64% on the ChartQA benchmark.