 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training
Paper and Code



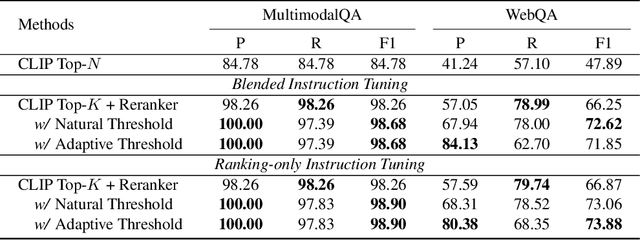
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in processing and generating content across multiple data modalities, including text, images, audio, and video. However, a significant drawback of MLLMs is their reliance on static training data, leading to outdated information and limited contextual awareness. This static nature hampers their ability to provide accurate, up-to-date responses, particularly in dynamic or rapidly evolving contexts. Integrating Multimodal Retrieval-augmented Generation (Multimodal RAG) offers a promising solution, but the system would inevitably encounter the multi-granularity noisy correspondence (MNC) problem, which involves two types of noise: coarse-grained (query-caption) and fine-grained (query-image). This noise hinders accurate retrieval and generation. In this work, we propose \textbf{RagLLaVA}, a novel framework with knowledge-enhanced reranking and noise-injected training, to address these limitations. We instruction-tune the MLLM with a simple yet effective instruction template to induce its ranking ability and serve it as a reranker to precisely filter the top-k retrieved images. For generation, we inject visual noise during training at the data and token levels to enhance the generator's robustness. Extensive experiments are conducted on the subsets of two datasets that require retrieving and reasoning over images to answer a given query. Our results demonstrate the superiority of RagLLaVA in retrieving accurately and generating robustly. Code and models are available at https://github.com/IDEA-FinAI/RagLLaVA.