 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolSculpt: Sculpting 3D Molecular Geometries from Chemical Syntax
Dec 09, 2025Generating precise 3D molecular geometries is crucial for drug discovery and material science. While prior efforts leverage 1D representations like SELFIES to ensure molecular validity, they fail to fully exploit the rich chemical knowledge entangled within 1D models, leading to a disconnect between 1D syntactic generation and 3D geometric realization. To bridge this gap, we propose MolSculpt, a novel framework that "sculpts" 3D molecular geometries from chemical syntax. MolSculpt is built upon a frozen 1D molecular foundation model and a 3D molecular diffusion model. We introduce a set of learnable queries to extract inherent chemical knowledge from the foundation model, and a trainable projector then injects this cross-modal information into the conditioning space of the diffusion model to guide the 3D geometry generation. In this way, our model deeply integrates 1D latent chemical knowledge into the 3D generation process through end-to-end optimization. Experiments demonstrate that MolSculpt achieves state-of-the-art (SOTA) performance in \textit{de novo} 3D molecule generation and conditional 3D molecule generation, showing superior 3D fidelity and stability on both the GEOM-DRUGS and QM9 datasets. Code is available at https://github.com/SakuraTroyChen/MolSculpt.
From Visuals to Vocabulary: Establishing Equivalence Between Image and Text Token Through Autoregressive Pre-training in MLLMs
Feb 13, 2025
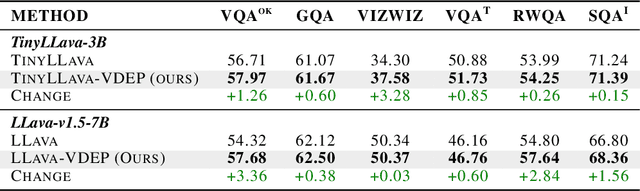
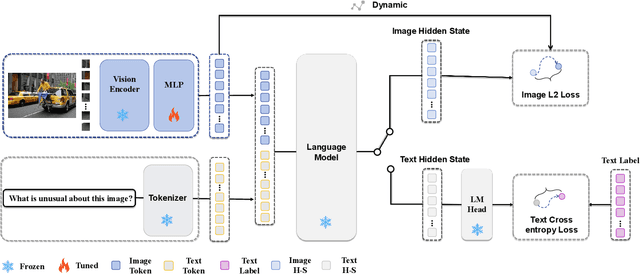
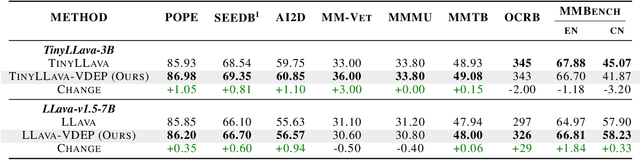
While MLLMs perform well on perceptual tasks, they lack precise multimodal alignment, limiting performance. To address this challenge, we propose Vision Dynamic Embedding-Guided Pretraining (VDEP), a hybrid autoregressive training paradigm for MLLMs. Utilizing dynamic embeddings from the MLP following the visual encoder, this approach supervises image hidden states and integrates image tokens into autoregressive training. Existing MLLMs primarily focused on recovering information from textual inputs, often neglecting the effective processing of image data. In contrast, the key improvement of this work is the reinterpretation of multimodal alignment as a process of recovering information from input data, with particular emphasis on reconstructing detailed visual features.The proposed method seamlessly integrates into standard models without architectural changes. Experiments on 13 benchmarks show VDEP outperforms baselines, surpassing existing methods.
Advancing General Multimodal Capability of Vision-language Models with Pyramid-descent Visual Position Encoding
Jan 19, 2025Vision-language Models (VLMs) have shown remarkable capabilities in advancing general artificial intelligence, yet the irrational encoding of visual positions persists in inhibiting the models' comprehensive perception performance across different levels of granularity. In this work, we propose Pyramid-descent Visual Position Encoding (PyPE), a novel approach designed to enhance the perception of visual tokens within VLMs. By assigning visual position indexes from the periphery to the center and expanding the central receptive field incrementally, PyPE addresses the limitations of traditional raster-scan methods and mitigates the long-term decay effects induced by Rotary Position Embedding (RoPE). Our method reduces the relative distance between interrelated visual elements and instruction tokens, promoting a more rational allocation of attention weights and allowing for a multi-granularity perception of visual elements and countering the over-reliance on anchor tokens. Extensive experimental evaluations demonstrate that PyPE consistently improves the general capabilities of VLMs across various sizes. Code is available at https://github.com/SakuraTroyChen/PyPE.
MLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training
Jul 31, 2024


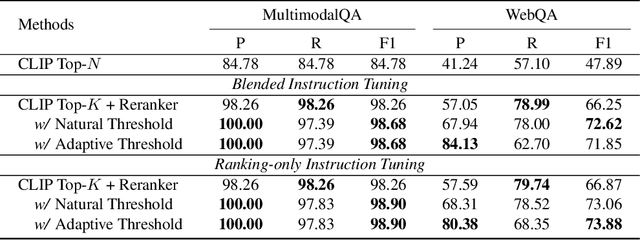
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in processing and generating content across multiple data modalities, including text, images, audio, and video. However, a significant drawback of MLLMs is their reliance on static training data, leading to outdated information and limited contextual awareness. This static nature hampers their ability to provide accurate, up-to-date responses, particularly in dynamic or rapidly evolving contexts. Integrating Multimodal Retrieval-augmented Generation (Multimodal RAG) offers a promising solution, but the system would inevitably encounter the multi-granularity noisy correspondence (MNC) problem, which involves two types of noise: coarse-grained (query-caption) and fine-grained (query-image). This noise hinders accurate retrieval and generation. In this work, we propose \textbf{RagLLaVA}, a novel framework with knowledge-enhanced reranking and noise-injected training, to address these limitations. We instruction-tune the MLLM with a simple yet effective instruction template to induce its ranking ability and serve it as a reranker to precisely filter the top-k retrieved images. For generation, we inject visual noise during training at the data and token levels to enhance the generator's robustness. Extensive experiments are conducted on the subsets of two datasets that require retrieving and reasoning over images to answer a given query. Our results demonstrate the superiority of RagLLaVA in retrieving accurately and generating robustly. Code and models are available at https://github.com/IDEA-FinAI/RagLLaVA.