 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Enhancing Vision-Text Alignment in MLLMs via Cross-Modal Mutual Information Maximization
May 19, 2025Current multimodal large language models (MLLMs) face a critical challenge in modality alignment, often exhibiting a bias towards textual information at the expense of other modalities like vision. This paper conducts a systematic information-theoretic analysis of the widely used cross-entropy loss in MLLMs, uncovering its implicit alignment objective. Our theoretical investigation reveals that this implicit objective has inherent limitations, leading to a degradation of cross-modal alignment as text sequence length increases, thereby hindering effective multimodal information fusion. To overcome these drawbacks, we propose Vision-Text Alignment (VISTA), a novel approach guided by our theoretical insights. VISTA introduces an explicit alignment objective designed to maximize cross-modal mutual information, preventing the degradation of visual alignment. Notably, VISTA enhances the visual understanding capabilities of existing MLLMs without requiring any additional trainable modules or extra training data, making it both efficient and practical. Our method significantly outperforms baseline models across more than a dozen benchmark datasets, including VQAv2, MMStar, and MME, paving the way for new directions in MLLM modal alignment research.
From Visuals to Vocabulary: Establishing Equivalence Between Image and Text Token Through Autoregressive Pre-training in MLLMs
Feb 13, 2025
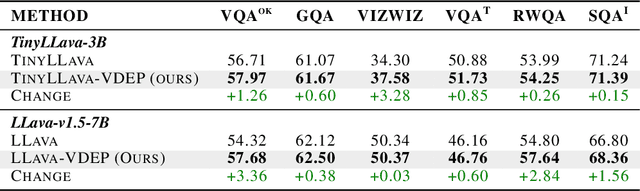
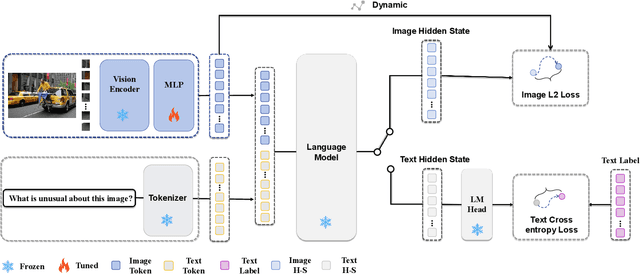
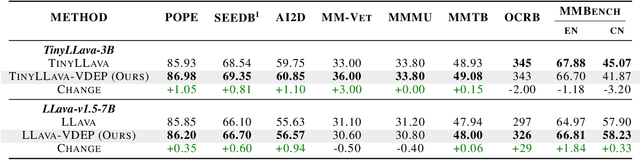
While MLLMs perform well on perceptual tasks, they lack precise multimodal alignment, limiting performance. To address this challenge, we propose Vision Dynamic Embedding-Guided Pretraining (VDEP), a hybrid autoregressive training paradigm for MLLMs. Utilizing dynamic embeddings from the MLP following the visual encoder, this approach supervises image hidden states and integrates image tokens into autoregressive training. Existing MLLMs primarily focused on recovering information from textual inputs, often neglecting the effective processing of image data. In contrast, the key improvement of this work is the reinterpretation of multimodal alignment as a process of recovering information from input data, with particular emphasis on reconstructing detailed visual features.The proposed method seamlessly integrates into standard models without architectural changes. Experiments on 13 benchmarks show VDEP outperforms baselines, surpassing existing methods.
MM-Retinal V2: Transfer an Elite Knowledge Spark into Fundus Vision-Language Pretraining
Jan 27, 2025



Vision-language pretraining (VLP) has been investigated to generalize across diverse downstream tasks for fundus image analysis. Although recent methods showcase promising achievements, they significantly rely on large-scale private image-text data but pay less attention to the pretraining manner, which limits their further advancements. In this work, we introduce MM-Retinal V2, a high-quality image-text paired dataset comprising CFP, FFA, and OCT image modalities. Then, we propose a novel fundus vision-language pretraining model, namely KeepFIT V2, which is pretrained by integrating knowledge from the elite data spark into categorical public datasets. Specifically, a preliminary textual pretraining is adopted to equip the text encoder with primarily ophthalmic textual knowledge. Moreover, a hybrid image-text knowledge injection module is designed for knowledge transfer, which is essentially based on a combination of global semantic concepts from contrastive learning and local appearance details from generative learning. Extensive experiments across zero-shot, few-shot, and linear probing settings highlight the generalization and transferability of KeepFIT V2, delivering performance competitive to state-of-the-art fundus VLP models trained on large-scale private image-text datasets. Our dataset and model are publicly available via https://github.com/lxirich/MM-Retinal.
Memory-efficient High-resolution OCT Volume Synthesis with Cascaded Amortized Latent Diffusion Models
May 26, 2024Optical coherence tomography (OCT) image analysis plays an important role in the field of ophthalmology. Current successful analysis models rely on available large datasets, which can be challenging to be obtained for certain tasks. The use of deep generative models to create realistic data emerges as a promising approach. However, due to limitations in hardware resources, it is still difficulty to synthesize high-resolution OCT volumes. In this paper, we introduce a cascaded amortized latent diffusion model (CA-LDM) that can synthesis high-resolution OCT volumes in a memory-efficient way. First, we propose non-holistic autoencoders to efficiently build a bidirectional mapping between high-resolution volume space and low-resolution latent space. In tandem with autoencoders, we propose cascaded diffusion processes to synthesize high-resolution OCT volumes with a global-to-local refinement process, amortizing the memory and computational demands. Experiments on a public high-resolution OCT dataset show that our synthetic data have realistic high-resolution and global features, surpassing the capabilities of existing methods. Moreover, performance gains on two down-stream fine-grained segmentation tasks demonstrate the benefit of the proposed method in training deep learning models for medical imaging tasks. The code is public available at: https://github.com/nicetomeetu21/CA-LDM.
Adjustable Robust Transformer for High Myopia Screening in Optical Coherence Tomography
Dec 12, 2023Myopia is a manifestation of visual impairment caused by an excessively elongated eyeball. Image data is critical material for studying high myopia and pathological myopia. Measurements of spherical equivalent and axial length are the gold standards for identifying high myopia, but the available image data for matching them is scarce. In addition, the criteria for defining high myopia vary from study to study, and therefore the inclusion of samples in automated screening efforts requires an appropriate assessment of interpretability. In this work, we propose a model called adjustable robust transformer (ARTran) for high myopia screening of optical coherence tomography (OCT) data. Based on vision transformer, we propose anisotropic patch embedding (APE) to capture more discriminative features of high myopia. To make the model effective under variable screening conditions, we propose an adjustable class embedding (ACE) to replace the fixed class token, which changes the output to adapt to different conditions. Considering the confusion of the data at high myopia and low myopia threshold, we introduce the label noise learning strategy and propose a shifted subspace transition matrix (SST) to enhance the robustness of the model. Besides, combining the two structures proposed above, the model can provide evidence for uncertainty evaluation. The experimental results demonstrate the effectiveness and reliability of the proposed method. Code is available at: https://github.com/maxiao0234/ARTran.