 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quantification of Hyperreflective Foci in SD-OCT With Diabetic Retinopathy
Jul 31, 2024



The presence of hyperreflective foci (HFs) is related to retinal disease progression, and the quantity has proven to be a prognostic factor of visual and anatomical outcome in various retinal diseases. However, lack of efficient quantitative tools for evaluating the HFs has deprived ophthalmologist of assessing the volume of HFs. For this reason, we propose an automated quantification algorithm to segment and quantify HFs in spectral domain optical coherence tomography (SD-OCT). The proposed algorithm consists of two parallel processes namely: region of interest (ROI) generation and HFs estimation. To generate the ROI, we use morphological reconstruction to obtain the reconstructed image and histogram constructed for data distributions and clustering. In parallel, we estimate the HFs by extracting the extremal regions from the connected regions obtained from a component tree. Finally, both the ROI and the HFs estimation process are merged to obtain the segmented HFs. The proposed algorithm was tested on 40 3D SD-OCT volumes from 40 patients diagnosed with non-proliferative diabetic retinopathy (NPDR), proliferative diabetic retinopathy (PDR), and diabetic macular edema (DME). The average dice similarity coefficient (DSC) and correlation coefficient (r) are 69.70%, 0.99 for NPDR, 70.31%, 0.99 for PDR, and 71.30%, 0.99 for DME, respectively. The proposed algorithm can provide ophthalmologist with good HFs quantitative information, such as volume, size, and location of the HFs.
* IEEE Journal of Biomedical and Health Informatics, Volume: 24, Issue: 4, pp. 1125 - 1136, 2020
Memory-efficient High-resolution OCT Volume Synthesis with Cascaded Amortized Latent Diffusion Models
May 26, 2024Optical coherence tomography (OCT) image analysis plays an important role in the field of ophthalmology. Current successful analysis models rely on available large datasets, which can be challenging to be obtained for certain tasks. The use of deep generative models to create realistic data emerges as a promising approach. However, due to limitations in hardware resources, it is still difficulty to synthesize high-resolution OCT volumes. In this paper, we introduce a cascaded amortized latent diffusion model (CA-LDM) that can synthesis high-resolution OCT volumes in a memory-efficient way. First, we propose non-holistic autoencoders to efficiently build a bidirectional mapping between high-resolution volume space and low-resolution latent space. In tandem with autoencoders, we propose cascaded diffusion processes to synthesize high-resolution OCT volumes with a global-to-local refinement process, amortizing the memory and computational demands. Experiments on a public high-resolution OCT dataset show that our synthetic data have realistic high-resolution and global features, surpassing the capabilities of existing methods. Moreover, performance gains on two down-stream fine-grained segmentation tasks demonstrate the benefit of the proposed method in training deep learning models for medical imaging tasks. The code is public available at: https://github.com/nicetomeetu21/CA-LDM.
Adjustable Robust Transformer for High Myopia Screening in Optical Coherence Tomography
Dec 12, 2023Myopia is a manifestation of visual impairment caused by an excessively elongated eyeball. Image data is critical material for studying high myopia and pathological myopia. Measurements of spherical equivalent and axial length are the gold standards for identifying high myopia, but the available image data for matching them is scarce. In addition, the criteria for defining high myopia vary from study to study, and therefore the inclusion of samples in automated screening efforts requires an appropriate assessment of interpretability. In this work, we propose a model called adjustable robust transformer (ARTran) for high myopia screening of optical coherence tomography (OCT) data. Based on vision transformer, we propose anisotropic patch embedding (APE) to capture more discriminative features of high myopia. To make the model effective under variable screening conditions, we propose an adjustable class embedding (ACE) to replace the fixed class token, which changes the output to adapt to different conditions. Considering the confusion of the data at high myopia and low myopia threshold, we introduce the label noise learning strategy and propose a shifted subspace transition matrix (SST) to enhance the robustness of the model. Besides, combining the two structures proposed above, the model can provide evidence for uncertainty evaluation. The experimental results demonstrate the effectiveness and reliability of the proposed method. Code is available at: https://github.com/maxiao0234/ARTran.
Learn Single-horizon Disease Evolution for Predictive Generation of Post-therapeutic Neovascular Age-related Macular Degeneration
Aug 12, 2023



Most of the existing disease prediction methods in the field of medical image processing fall into two classes, namely image-to-category predictions and image-to-parameter predictions. Few works have focused on image-to-image predictions. Different from multi-horizon predictions in other fields, ophthalmologists prefer to show more confidence in single-horizon predictions due to the low tolerance of predictive risk. We propose a single-horizon disease evolution network (SHENet) to predictively generate post-therapeutic SD-OCT images by inputting pre-therapeutic SD-OCT images with neovascular age-related macular degeneration (nAMD). In SHENet, a feature encoder converts the input SD-OCT images to deep features, then a graph evolution module predicts the process of disease evolution in high-dimensional latent space and outputs the predicted deep features, and lastly, feature decoder recovers the predicted deep features to SD-OCT images. We further propose an evolution reinforcement module to ensure the effectiveness of disease evolution learning and obtain realistic SD-OCT images by adversarial training. SHENet is validated on 383 SD-OCT cubes of 22 nAMD patients based on three well-designed schemes based on the quantitative and qualitative evaluations. Compared with other generative methods, the generative SD-OCT images of SHENet have the highest image quality. Besides, SHENet achieves the best structure protection and content prediction. Qualitative evaluations also demonstrate that SHENet has a better visual effect than other methods. SHENet can generate post-therapeutic SD-OCT images with both high prediction performance and good image quality, which has great potential to help ophthalmologists forecast the therapeutic effect of nAMD.
IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation
Dec 14, 2020


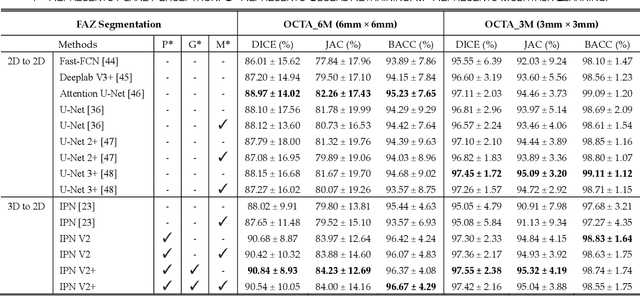
Optical coherence tomography angiography (OCTA) is a novel imaging modality that allows a micron-level resolution to present the three-dimensional structure of the retinal vascular. In our previous work, a 3D-to-2D image projection network (IPN) was proposed for retinal vessel (RV) and foveal avascular zone (FAZ) segmentations in OCTA images. One of its advantages is that the segmentation results are directly from the original volumes without using any projection images and retinal layer segmentation. In this work, we propose image projection network V2 (IPN-V2), extending IPN by adding a plane perceptron to enhance the perceptron ability in the horizontal direction. We also propose IPN-V2+, as a supplement of the IPN-V2, by introducing a global retraining process to overcome the "checkerboard effect". Besides, we propose a new multi-modality dataset, dubbed OCTA-500. It contains 500 subjects with two field of view (FOV) types, including OCT and OCTA volumes, six types of projections, four types of text labels and two types of pixel-level labels. The dataset contains more than 360K images with a size of about 80GB. To the best of our knowledge, it is currently the largest OCTA dataset with the abundant information. Finally, we perform a thorough evaluation of the performance of IPN-V2 on the OCTA-500 dataset. The experimental results demonstrate that our proposed IPN-V2 performs better than IPN and other deep learning methods in RV segmentation and FAZ segmentation.
OoDAnalyzer: Interactive Analysis of Out-of-Distribution Samples
Feb 08, 2020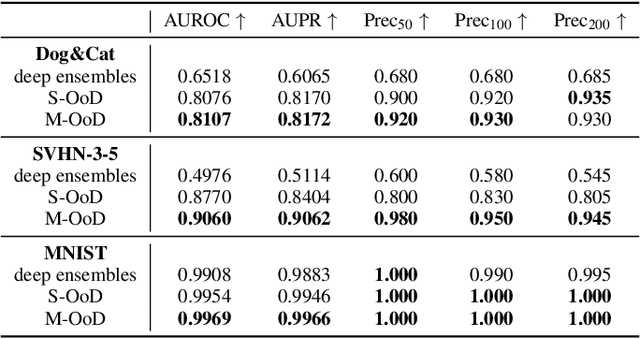

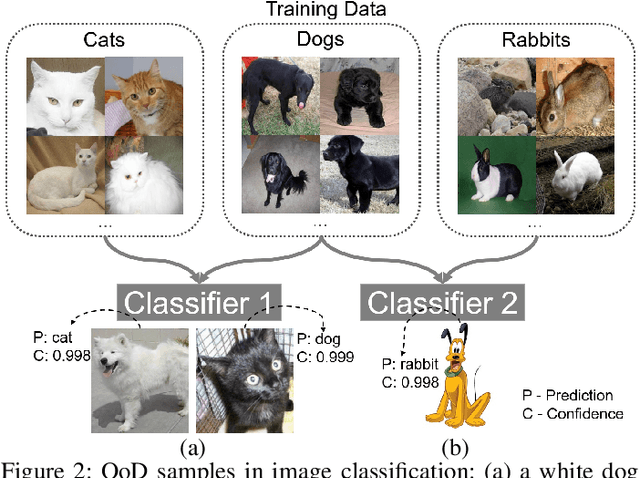
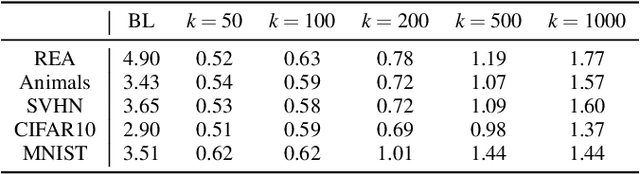
One major cause of performance degradation in predictive models is that the test samples are not well covered by the training data. Such not well-represented samples are called OoD samples. In this paper, we propose OoDAnalyzer, a visual analysis approach for interactively identifying OoD samples and explaining them in context. Our approach integrates an ensemble OoD detection method and a grid-based visualization. The detection method is improved from deep ensembles by combining more features with algorithms in the same family. To better analyze and understand the OoD samples in context, we have developed a novel kNN-based grid layout algorithm motivated by Hall's theorem. The algorithm approximates the optimal layout and has $O(kN^2)$ time complexity, faster than the grid layout algorithm with overall best performance but $O(N^3)$ time complexity. Quantitative evaluation and case studies were performed on several datasets to demonstrate the effectiveness and usefulness of OoDAnalyzer.