 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-MLVTON: Garment Occlusion-Aware Multi-Layer Virtual Try-On with Diffusion Models
Jan 20, 2026Existing Image-based virtual try-on (VTON) methods primarily focus on single-layer or multi-garment VTON, neglecting multi-layer VTON (ML-VTON), which involves dressing multiple layers of garments onto the human body with realistic deformation and layering to generate visually plausible outcomes. The main challenge lies in accurately modeling occlusion relationships between inner and outer garments to reduce interference from redundant inner garment features. To address this, we propose GO-MLVTON, the first multi-layer VTON method, introducing the Garment Occlusion Learning module to learn occlusion relationships and the StableDiffusion-based Garment Morphing & Fitting module to deform and fit garments onto the human body, producing high-quality multi-layer try-on results. Additionally, we present the MLG dataset for this task and propose a new metric named Layered Appearance Coherence Difference (LACD) for evaluation. Extensive experiments demonstrate the state-of-the-art performance of GO-MLVTON. Project page: https://upyuyang.github.io/go-mlvton/.
A Class of Dual-Frame Passively-Tilting Fully-Actuated Hexacopter
Nov 19, 2025



This paper proposed a novel fully-actuated hexacopter. It features a dual-frame passive tilting structure and achieves independent control of translational motion and attitude with minimal actuators. Compared to previous fully-actuated UAVs, it liminates internal force cancellation, resulting in higher flight efficiency and endurance under equivalent payload conditions. Based on the dynamic model of fully-actuated hexacopter, a full-actuation controller is designed to achieve efficient and stable control. Finally, simulation is conducted, validating the superior fully-actuated motion capability of fully-actuated hexacopter and the effectiveness of the proposed control strategy.
Learn Single-horizon Disease Evolution for Predictive Generation of Post-therapeutic Neovascular Age-related Macular Degeneration
Aug 12, 2023



Most of the existing disease prediction methods in the field of medical image processing fall into two classes, namely image-to-category predictions and image-to-parameter predictions. Few works have focused on image-to-image predictions. Different from multi-horizon predictions in other fields, ophthalmologists prefer to show more confidence in single-horizon predictions due to the low tolerance of predictive risk. We propose a single-horizon disease evolution network (SHENet) to predictively generate post-therapeutic SD-OCT images by inputting pre-therapeutic SD-OCT images with neovascular age-related macular degeneration (nAMD). In SHENet, a feature encoder converts the input SD-OCT images to deep features, then a graph evolution module predicts the process of disease evolution in high-dimensional latent space and outputs the predicted deep features, and lastly, feature decoder recovers the predicted deep features to SD-OCT images. We further propose an evolution reinforcement module to ensure the effectiveness of disease evolution learning and obtain realistic SD-OCT images by adversarial training. SHENet is validated on 383 SD-OCT cubes of 22 nAMD patients based on three well-designed schemes based on the quantitative and qualitative evaluations. Compared with other generative methods, the generative SD-OCT images of SHENet have the highest image quality. Besides, SHENet achieves the best structure protection and content prediction. Qualitative evaluations also demonstrate that SHENet has a better visual effect than other methods. SHENet can generate post-therapeutic SD-OCT images with both high prediction performance and good image quality, which has great potential to help ophthalmologists forecast the therapeutic effect of nAMD.
Label Adversarial Learning for Skeleton-level to Pixel-level Adjustable Vessel Segmentation
May 07, 2022


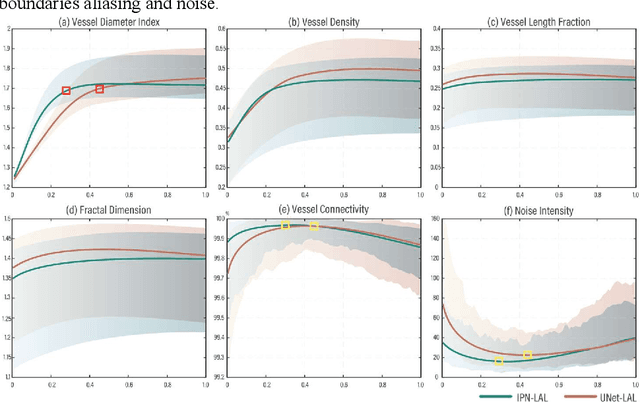
You can have your cake and eat it too. Microvessel segmentation in optical coherence tomography angiography (OCTA) images remains challenging. Skeleton-level segmentation shows clear topology but without diameter information, while pixel-level segmentation shows a clear caliber but low topology. To close this gap, we propose a novel label adversarial learning (LAL) for skeleton-level to pixel-level adjustable vessel segmentation. LAL mainly consists of two designs: a label adversarial loss and an embeddable adjustment layer. The label adversarial loss establishes an adversarial relationship between the two label supervisions, while the adjustment layer adjusts the network parameters to match the different adversarial weights. Such a design can efficiently capture the variation between the two supervisions, making the segmentation continuous and tunable. This continuous process allows us to recommend high-quality vessel segmentation with clear caliber and topology. Experimental results show that our results outperform manual annotations of current public datasets and conventional filtering effects. Furthermore, such a continuous process can also be used to generate an uncertainty map representing weak vessel boundaries and noise.
Image Magnification Network for Vessel Segmentation in OCTA Images
Oct 26, 2021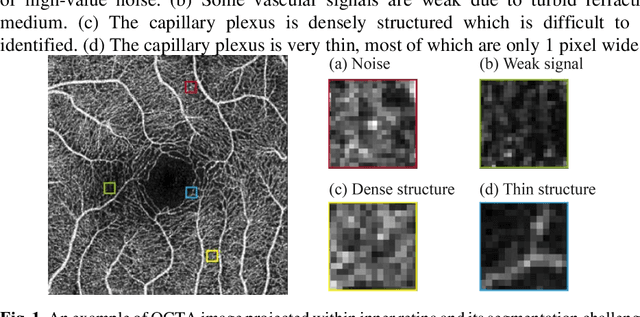



Optical coherence tomography angiography (OCTA) is a novel non-invasive imaging modality that allows micron-level resolution to visualize the retinal microvasculature. The retinal vessel segmentation in OCTA images is still an open problem, and especially the thin and dense structure of the capillary plexus is an important challenge of this problem. In this work, we propose a novel image magnification network (IMN) for vessel segmentation in OCTA images. Contrary to the U-Net structure with a down-sampling encoder and up-sampling decoder, the proposed IMN adopts the design of up-sampling encoding and then down-sampling decoding. This design is to capture more image details and reduce the omission of thin-and-small structures. The experimental results on three open OCTA datasets show that the proposed IMN with an average dice score of 90.2% achieves the best performance in vessel segmentation of OCTA images. Besides, we also demonstrate the superior performance of IMN in cross-field image vessel segmentation and vessel skeleton extraction.
IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation
Dec 14, 2020


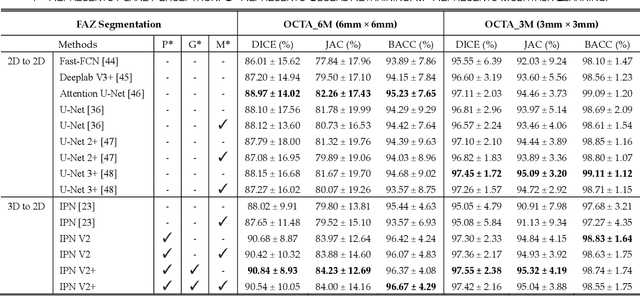
Optical coherence tomography angiography (OCTA) is a novel imaging modality that allows a micron-level resolution to present the three-dimensional structure of the retinal vascular. In our previous work, a 3D-to-2D image projection network (IPN) was proposed for retinal vessel (RV) and foveal avascular zone (FAZ) segmentations in OCTA images. One of its advantages is that the segmentation results are directly from the original volumes without using any projection images and retinal layer segmentation. In this work, we propose image projection network V2 (IPN-V2), extending IPN by adding a plane perceptron to enhance the perceptron ability in the horizontal direction. We also propose IPN-V2+, as a supplement of the IPN-V2, by introducing a global retraining process to overcome the "checkerboard effect". Besides, we propose a new multi-modality dataset, dubbed OCTA-500. It contains 500 subjects with two field of view (FOV) types, including OCT and OCTA volumes, six types of projections, four types of text labels and two types of pixel-level labels. The dataset contains more than 360K images with a size of about 80GB. To the best of our knowledge, it is currently the largest OCTA dataset with the abundant information. Finally, we perform a thorough evaluation of the performance of IPN-V2 on the OCTA-500 dataset. The experimental results demonstrate that our proposed IPN-V2 performs better than IPN and other deep learning methods in RV segmentation and FAZ segmentation.