 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation
Paper and Code



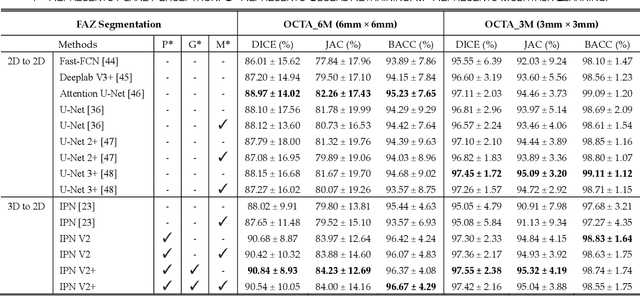
Optical coherence tomography angiography (OCTA) is a novel imaging modality that allows a micron-level resolution to present the three-dimensional structure of the retinal vascular. In our previous work, a 3D-to-2D image projection network (IPN) was proposed for retinal vessel (RV) and foveal avascular zone (FAZ) segmentations in OCTA images. One of its advantages is that the segmentation results are directly from the original volumes without using any projection images and retinal layer segmentation. In this work, we propose image projection network V2 (IPN-V2), extending IPN by adding a plane perceptron to enhance the perceptron ability in the horizontal direction. We also propose IPN-V2+, as a supplement of the IPN-V2, by introducing a global retraining process to overcome the "checkerboard effect". Besides, we propose a new multi-modality dataset, dubbed OCTA-500. It contains 500 subjects with two field of view (FOV) types, including OCT and OCTA volumes, six types of projections, four types of text labels and two types of pixel-level labels. The dataset contains more than 360K images with a size of about 80GB. To the best of our knowledge, it is currently the largest OCTA dataset with the abundant information. Finally, we perform a thorough evaluation of the performance of IPN-V2 on the OCTA-500 dataset. The experimental results demonstrate that our proposed IPN-V2 performs better than IPN and other deep learning methods in RV segmentation and FAZ segmentation.