 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quantification of Hyperreflective Foci in SD-OCT With Diabetic Retinopathy
Jul 31, 2024



The presence of hyperreflective foci (HFs) is related to retinal disease progression, and the quantity has proven to be a prognostic factor of visual and anatomical outcome in various retinal diseases. However, lack of efficient quantitative tools for evaluating the HFs has deprived ophthalmologist of assessing the volume of HFs. For this reason, we propose an automated quantification algorithm to segment and quantify HFs in spectral domain optical coherence tomography (SD-OCT). The proposed algorithm consists of two parallel processes namely: region of interest (ROI) generation and HFs estimation. To generate the ROI, we use morphological reconstruction to obtain the reconstructed image and histogram constructed for data distributions and clustering. In parallel, we estimate the HFs by extracting the extremal regions from the connected regions obtained from a component tree. Finally, both the ROI and the HFs estimation process are merged to obtain the segmented HFs. The proposed algorithm was tested on 40 3D SD-OCT volumes from 40 patients diagnosed with non-proliferative diabetic retinopathy (NPDR), proliferative diabetic retinopathy (PDR), and diabetic macular edema (DME). The average dice similarity coefficient (DSC) and correlation coefficient (r) are 69.70%, 0.99 for NPDR, 70.31%, 0.99 for PDR, and 71.30%, 0.99 for DME, respectively. The proposed algorithm can provide ophthalmologist with good HFs quantitative information, such as volume, size, and location of the HFs.
* IEEE Journal of Biomedical and Health Informatics, Volume: 24, Issue: 4, pp. 1125 - 1136, 2020
Test-Time Generative Augmentation for Medical Image Segmentation
Jun 25, 2024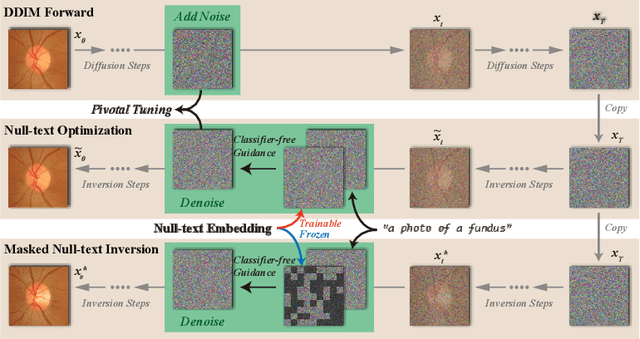

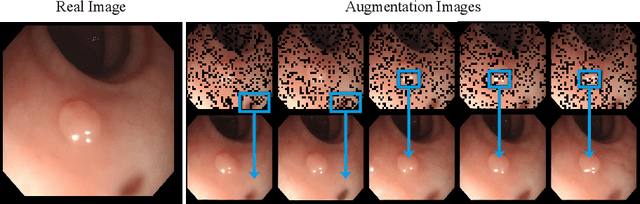
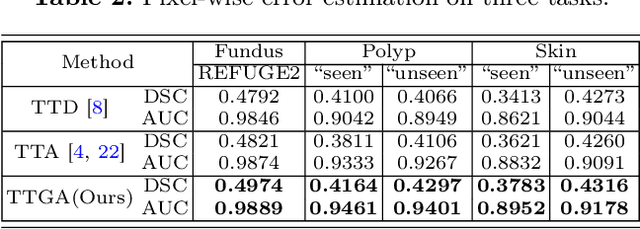
In this paper, we propose a novel approach to enhance medical image segmentation during test time. Instead of employing hand-crafted transforms or functions on the input test image to create multiple views for test-time augmentation, we advocate for the utilization of an advanced domain-fine-tuned generative model (GM), e.g., stable diffusion (SD), for test-time augmentation. Given that the GM has been trained to comprehend and encapsulate comprehensive domain data knowledge, it is superior than segmentation models in terms of representing the data characteristics and distribution. Hence, by integrating the GM into test-time augmentation, we can effectively generate multiple views of a given test sample, aligning with the content and appearance characteristics of the sample and the related local data distribution. This approach renders the augmentation process more adaptable and resilient compared to conventional handcrafted transforms. Comprehensive experiments conducted across three medical image segmentation tasks (nine datasets) demonstrate the efficacy and versatility of the proposed TTGA in enhancing segmentation outcomes. Moreover, TTGA significantly improves pixel-wise error estimation, thereby facilitating the deployment of a more reliable segmentation system. Code will be released at: https://github.com/maxiao0234/TTGA.
Adjustable Robust Transformer for High Myopia Screening in Optical Coherence Tomography
Dec 12, 2023Myopia is a manifestation of visual impairment caused by an excessively elongated eyeball. Image data is critical material for studying high myopia and pathological myopia. Measurements of spherical equivalent and axial length are the gold standards for identifying high myopia, but the available image data for matching them is scarce. In addition, the criteria for defining high myopia vary from study to study, and therefore the inclusion of samples in automated screening efforts requires an appropriate assessment of interpretability. In this work, we propose a model called adjustable robust transformer (ARTran) for high myopia screening of optical coherence tomography (OCT) data. Based on vision transformer, we propose anisotropic patch embedding (APE) to capture more discriminative features of high myopia. To make the model effective under variable screening conditions, we propose an adjustable class embedding (ACE) to replace the fixed class token, which changes the output to adapt to different conditions. Considering the confusion of the data at high myopia and low myopia threshold, we introduce the label noise learning strategy and propose a shifted subspace transition matrix (SST) to enhance the robustness of the model. Besides, combining the two structures proposed above, the model can provide evidence for uncertainty evaluation. The experimental results demonstrate the effectiveness and reliability of the proposed method. Code is available at: https://github.com/maxiao0234/ARTran.
IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation
Dec 14, 2020


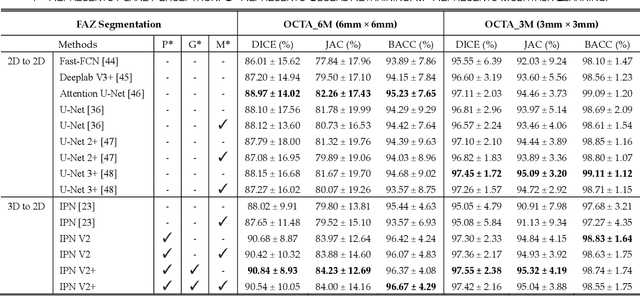
Optical coherence tomography angiography (OCTA) is a novel imaging modality that allows a micron-level resolution to present the three-dimensional structure of the retinal vascular. In our previous work, a 3D-to-2D image projection network (IPN) was proposed for retinal vessel (RV) and foveal avascular zone (FAZ) segmentations in OCTA images. One of its advantages is that the segmentation results are directly from the original volumes without using any projection images and retinal layer segmentation. In this work, we propose image projection network V2 (IPN-V2), extending IPN by adding a plane perceptron to enhance the perceptron ability in the horizontal direction. We also propose IPN-V2+, as a supplement of the IPN-V2, by introducing a global retraining process to overcome the "checkerboard effect". Besides, we propose a new multi-modality dataset, dubbed OCTA-500. It contains 500 subjects with two field of view (FOV) types, including OCT and OCTA volumes, six types of projections, four types of text labels and two types of pixel-level labels. The dataset contains more than 360K images with a size of about 80GB. To the best of our knowledge, it is currently the largest OCTA dataset with the abundant information. Finally, we perform a thorough evaluation of the performance of IPN-V2 on the OCTA-500 dataset. The experimental results demonstrate that our proposed IPN-V2 performs better than IPN and other deep learning methods in RV segmentation and FAZ segmentation.