 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropagating Structural Guidance: Synthesizing Fluorescein Angiography from Fundus Images and Sparse OCT Scans
Jun 15, 2026Fundus fluorescein angiography (FFA) is critical for assessing retinal vascular abnormalities, but its acquisition is invasive and not always feasible. In contrast, color fundus photography (CFP) is non-invasive and widely accessible, which has motivated studies on CFP-to-FFA synthesis. However, prior works rely solely on CFP surface texture, fundamentally limiting the ability to reconstruct functional vascular information and subtle pathological changes. To address this, we propose a novel framework that synthesizes FFA from CFP with structural guidance provided by optical coherence tomography (OCT). We construct a multi-modal retinal imaging dataset with paired CFP, FFA, and OCT from 3,676 patient eyes--the first tri-modally aligned dataset in retinal imaging. To bridge the spatial gap between OCT and fundus modalities, we propose a Spatially Aligned Cross-Modal Fusion (SACMF) module that projects depth-resolved OCT features onto the fundus plane and injects them into the CFP encoder via adaptive layer normalization. Beyond feature fusion, we further introduce Token-wise Cross-Modality Alignment (TCMA), a token-level contrastive learning strategy that explicitly aligns CFP and FFA representations at corresponding spatial positions. Our method achieves superior synthesis performance compared to state-of-the-art methods. Moreover, extensive experiments demonstrate that the FFA images synthesized by our approach bring greater improvements in downstream disease diagnosis performance than existing methods, highlighting the clinical potential of our approach as a non-invasive decision-support tool in routine workflows. The code is available at https://github.com/while-plus/OCT-guide-FFA-Syn.
MedKCO: Medical Vision-Language Pretraining via Knowledge-Driven Cognitive Orchestration
Mar 10, 2026Medical vision-language pretraining (VLP) models have recently been investigated for their generalization to diverse downstream tasks. However, current medical VLP methods typically force the model to learn simple and complex concepts simultaneously. This anti-cognitive process leads to suboptimal feature representations, especially under distribution shift. To address this limitation, we propose a Knowledge-driven Cognitive Orchestration for Medical VLP (MedKCO) that involves both the ordering of the pretraining data and the learning objective of vision-language contrast. Specifically, we design a two level curriculum by incorporating diagnostic sensitivity and intra-class sample representativeness for the ordering of the pretraining data. Moreover, considering the inter-class similarity of medical images, we introduce a self-paced asymmetric contrastive loss to dynamically adjust the participation of the pretraining objective. We evaluate the proposed pretraining method on three medical imaging scenarios in multiple vision-language downstream tasks, and compare it with several curriculum learning methods. Extensive experiments show that our method significantly surpasses all baselines. https://github.com/Mr-Talon/MedKCO.
MM-Retinal V2: Transfer an Elite Knowledge Spark into Fundus Vision-Language Pretraining
Jan 27, 2025



Vision-language pretraining (VLP) has been investigated to generalize across diverse downstream tasks for fundus image analysis. Although recent methods showcase promising achievements, they significantly rely on large-scale private image-text data but pay less attention to the pretraining manner, which limits their further advancements. In this work, we introduce MM-Retinal V2, a high-quality image-text paired dataset comprising CFP, FFA, and OCT image modalities. Then, we propose a novel fundus vision-language pretraining model, namely KeepFIT V2, which is pretrained by integrating knowledge from the elite data spark into categorical public datasets. Specifically, a preliminary textual pretraining is adopted to equip the text encoder with primarily ophthalmic textual knowledge. Moreover, a hybrid image-text knowledge injection module is designed for knowledge transfer, which is essentially based on a combination of global semantic concepts from contrastive learning and local appearance details from generative learning. Extensive experiments across zero-shot, few-shot, and linear probing settings highlight the generalization and transferability of KeepFIT V2, delivering performance competitive to state-of-the-art fundus VLP models trained on large-scale private image-text datasets. Our dataset and model are publicly available via https://github.com/lxirich/MM-Retinal.
XRZoo: A Large-Scale and Versatile Dataset of Extended Reality (XR) Applications
Dec 10, 2024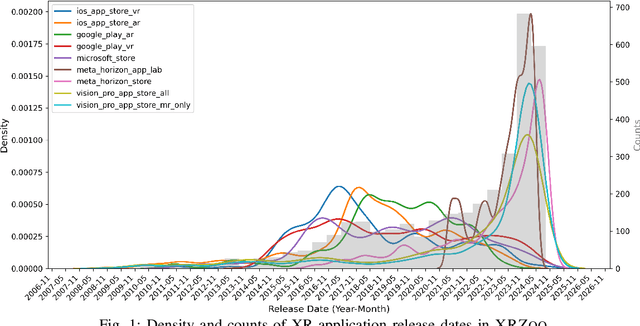
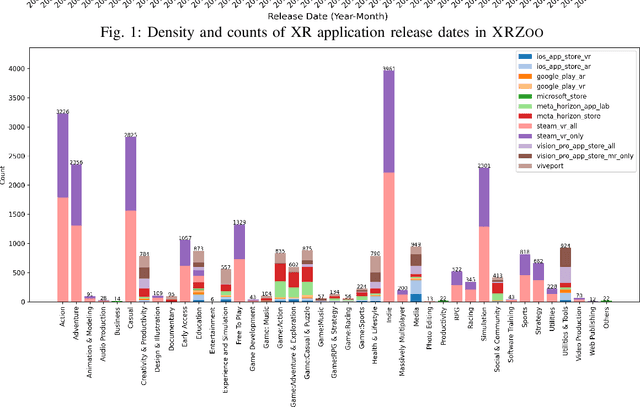
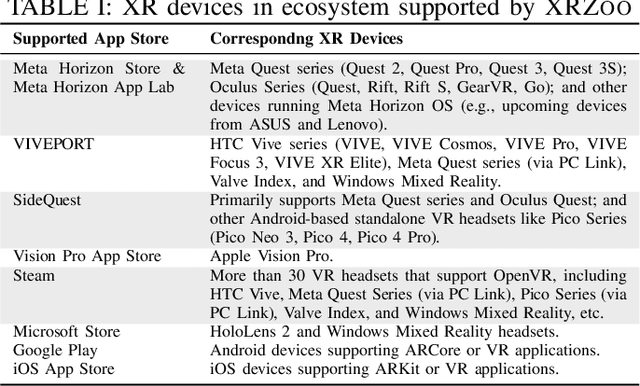
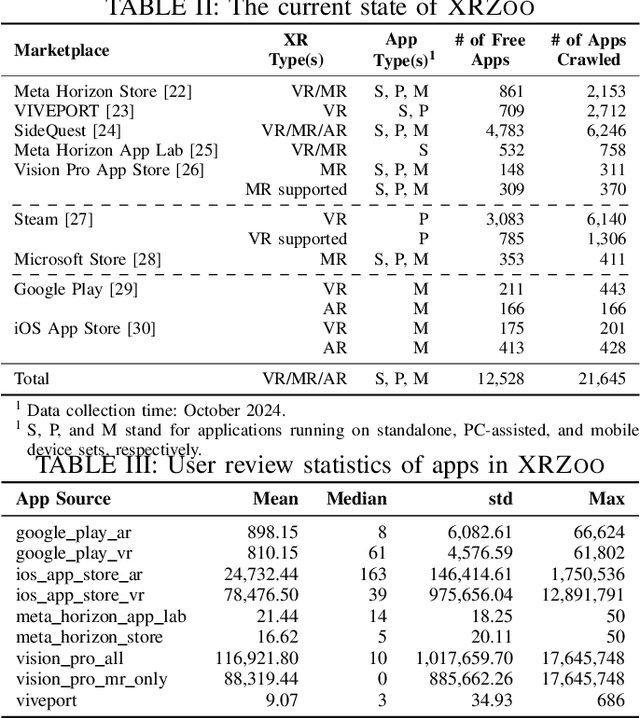
The rapid advancement of Extended Reality (XR, encompassing AR, MR, and VR) and spatial computing technologies forms a foundational layer for the emerging Metaverse, enabling innovative applications across healthcare, education, manufacturing, and entertainment. However, research in this area is often limited by the lack of large, representative, and highquality application datasets that can support empirical studies and the development of new approaches benefiting XR software processes. In this paper, we introduce XRZoo, a comprehensive and curated dataset of XR applications designed to bridge this gap. XRZoo contains 12,528 free XR applications, spanning nine app stores, across all XR techniques (i.e., AR, MR, and VR) and use cases, with detailed metadata on key aspects such as application descriptions, application categories, release dates, user review numbers, and hardware specifications, etc. By making XRZoo publicly available, we aim to foster reproducible XR software engineering and security research, enable cross-disciplinary investigations, and also support the development of advanced XR systems by providing examples to developers. Our dataset serves as a valuable resource for researchers and practitioners interested in improving the scalability, usability, and effectiveness of XR applications. XRZoo will be released and actively maintained.
MM-Retinal: Knowledge-Enhanced Foundational Pretraining with Fundus Image-Text Expertise
May 20, 2024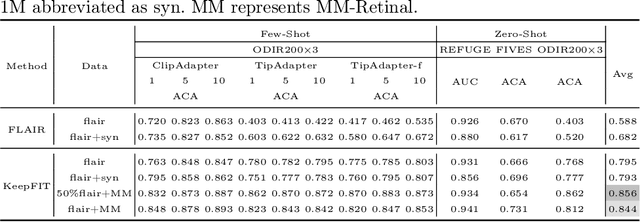

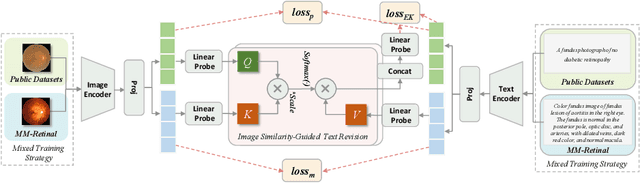
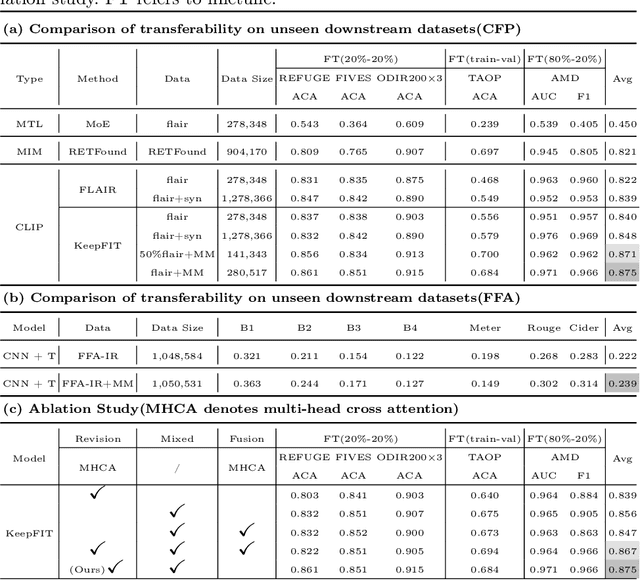
Current fundus image analysis models are predominantly built for specific tasks relying on individual datasets. The learning process is usually based on data-driven paradigm without prior knowledge, resulting in poor transferability and generalizability. To address this issue, we propose MM-Retinal, a multi-modal dataset that encompasses high-quality image-text pairs collected from professional fundus diagram books. Moreover, enabled by MM-Retinal, we present a novel Knowledge-enhanced foundational pretraining model which incorporates Fundus Image-Text expertise, called KeepFIT. It is designed with image similarity-guided text revision and mixed training strategy to infuse expert knowledge. Our proposed fundus foundation model achieves state-of-the-art performance across six unseen downstream tasks and holds excellent generalization ability in zero-shot and few-shot scenarios. MM-Retinal and KeepFIT are available at https://github.com/lxirich/MM-Retinal.