 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Visuals to Vocabulary: Establishing Equivalence Between Image and Text Token Through Autoregressive Pre-training in MLLMs
Paper and Code

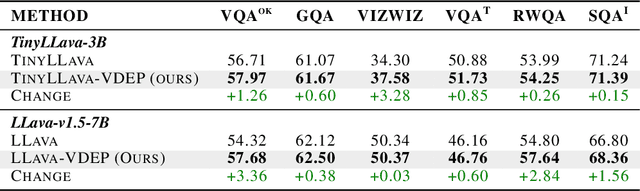
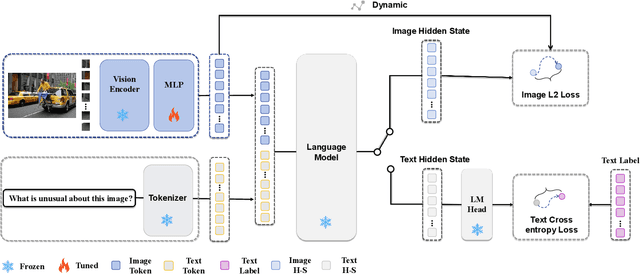
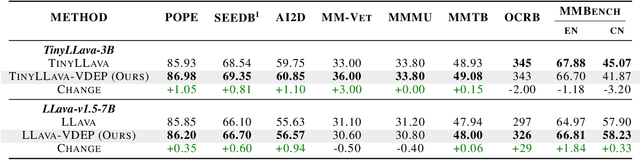
While MLLMs perform well on perceptual tasks, they lack precise multimodal alignment, limiting performance. To address this challenge, we propose Vision Dynamic Embedding-Guided Pretraining (VDEP), a hybrid autoregressive training paradigm for MLLMs. Utilizing dynamic embeddings from the MLP following the visual encoder, this approach supervises image hidden states and integrates image tokens into autoregressive training. Existing MLLMs primarily focused on recovering information from textual inputs, often neglecting the effective processing of image data. In contrast, the key improvement of this work is the reinterpretation of multimodal alignment as a process of recovering information from input data, with particular emphasis on reconstructing detailed visual features.The proposed method seamlessly integrates into standard models without architectural changes. Experiments on 13 benchmarks show VDEP outperforms baselines, surpassing existing methods.