 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT-HMR: Real-Time Multi-Person 3D Mesh Estimation via Scale-Adaptive Tokens
Nov 29, 2024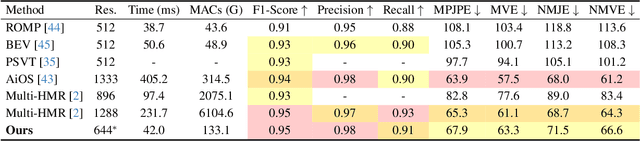
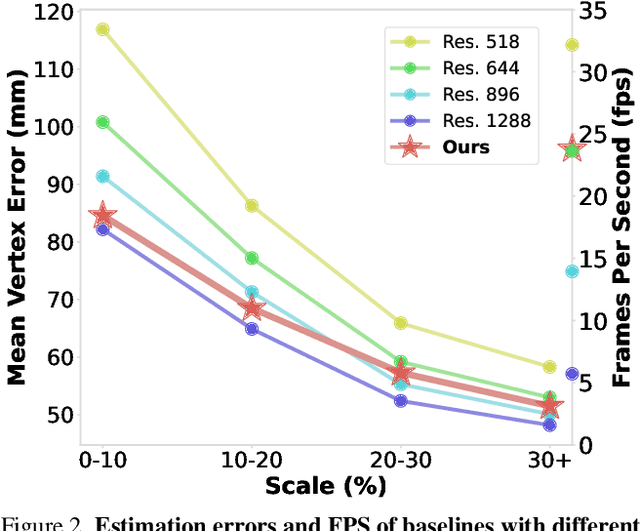
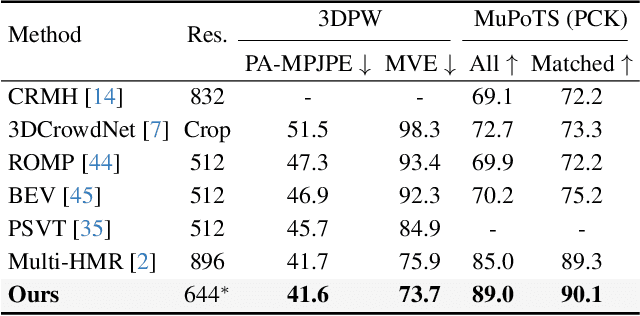
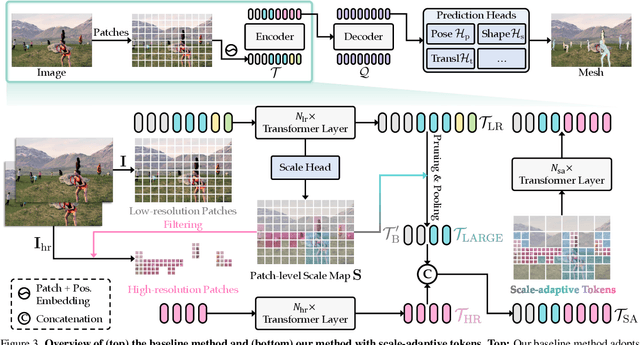
We propose a one-stage framework for real-time multi-person 3D human mesh estimation from a single RGB image. While current one-stage methods, which follow a DETR-style pipeline, achieve state-of-the-art (SOTA) performance with high-resolution inputs, we observe that this particularly benefits the estimation of individuals in smaller scales of the image (e.g., those far from the camera), but at the cost of significantly increased computation overhead. To address this, we introduce scale-adaptive tokens that are dynamically adjusted based on the relative scale of each individual in the image within the DETR framework. Specifically, individuals in smaller scales are processed at higher resolutions, larger ones at lower resolutions, and background regions are further distilled. These scale-adaptive tokens more efficiently encode the image features, facilitating subsequent decoding to regress the human mesh, while allowing the model to allocate computational resources more effectively and focus on more challenging cases. Experiments show that our method preserves the accuracy benefits of high-resolution processing while substantially reducing computational cost, achieving real-time inference with performance comparable to SOTA methods.
Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Nov 09, 2024



As large language models become increasingly prevalent in the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. However, existing finance benchmarks often suffer from limited language and task coverage, as well as challenges such as low-quality datasets and inadequate adaptability for LLM evaluation. To address these limitations, we propose "Golden Touchstone", the first comprehensive bilingual benchmark for financial LLMs, which incorporates representative datasets from both Chinese and English across eight core financial NLP tasks. Developed from extensive open source data collection and industry-specific demands, this benchmark includes a variety of financial tasks aimed at thoroughly assessing models' language understanding and generation capabilities. Through comparative analysis of major models on the benchmark, such as GPT-4o Llama3, FinGPT and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-sourced Touchstone-GPT, a financial LLM trained through continual pre-training and financial instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks.This research not only provides the financial large language models with a practical evaluation tool but also guides the development and optimization of future research. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at \url{https://github.com/IDEA-FinAI/Golden-Touchstone}, contributing to the ongoing evolution of FinLLMs and fostering further research in this critical area.
ChimpACT: A Longitudinal Dataset for Understanding Chimpanzee Behaviors
Oct 25, 2023



Understanding the behavior of non-human primates is crucial for improving animal welfare, modeling social behavior, and gaining insights into distinctively human and phylogenetically shared behaviors. However, the lack of datasets on non-human primate behavior hinders in-depth exploration of primate social interactions, posing challenges to research on our closest living relatives. To address these limitations, we present ChimpACT, a comprehensive dataset for quantifying the longitudinal behavior and social relations of chimpanzees within a social group. Spanning from 2015 to 2018, ChimpACT features videos of a group of over 20 chimpanzees residing at the Leipzig Zoo, Germany, with a particular focus on documenting the developmental trajectory of one young male, Azibo. ChimpACT is both comprehensive and challenging, consisting of 163 videos with a cumulative 160,500 frames, each richly annotated with detection, identification, pose estimation, and fine-grained spatiotemporal behavior labels. We benchmark representative methods of three tracks on ChimpACT: (i) tracking and identification, (ii) pose estimation, and (iii) spatiotemporal action detection of the chimpanzees. Our experiments reveal that ChimpACT offers ample opportunities for both devising new methods and adapting existing ones to solve fundamental computer vision tasks applied to chimpanzee groups, such as detection, pose estimation, and behavior analysis, ultimately deepening our comprehension of communication and sociality in non-human primates.
3D Human Mesh Estimation from Virtual Markers
Mar 27, 2023Inspired by the success of volumetric 3D pose estimation, some recent human mesh estimators propose to estimate 3D skeletons as intermediate representations, from which, the dense 3D meshes are regressed by exploiting the mesh topology. However, body shape information is lost in extracting skeletons, leading to mediocre performance. The advanced motion capture systems solve the problem by placing dense physical markers on the body surface, which allows to extract realistic meshes from their non-rigid motions. However, they cannot be applied to wild images without markers. In this work, we present an intermediate representation, named virtual markers, which learns 64 landmark keypoints on the body surface based on the large-scale mocap data in a generative style, mimicking the effects of physical markers. The virtual markers can be accurately detected from wild images and can reconstruct the intact meshes with realistic shapes by simple interpolation. Our approach outperforms the state-of-the-art methods on three datasets. In particular, it surpasses the existing methods by a notable margin on the SURREAL dataset, which has diverse body shapes. Code is available at https://github.com/ShirleyMaxx/VirtualMarker.
VirtualPose: Learning Generalizable 3D Human Pose Models from Virtual Data
Jul 20, 2022
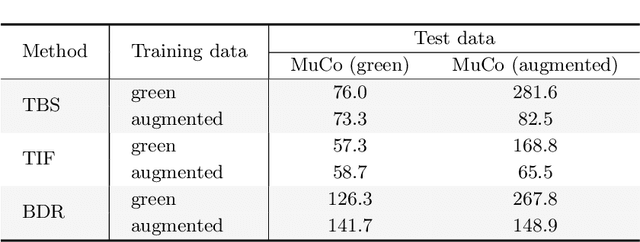
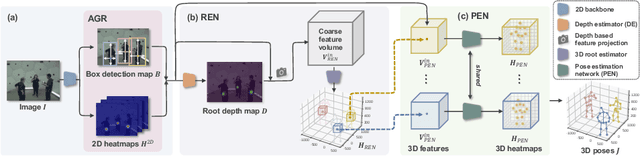

While monocular 3D pose estimation seems to have achieved very accurate results on the public datasets, their generalization ability is largely overlooked. In this work, we perform a systematic evaluation of the existing methods and find that they get notably larger errors when tested on different cameras, human poses and appearance. To address the problem, we introduce VirtualPose, a two-stage learning framework to exploit the hidden "free lunch" specific to this task, i.e. generating infinite number of poses and cameras for training models at no cost. To that end, the first stage transforms images to abstract geometry representations (AGR), and then the second maps them to 3D poses. It addresses the generalization issue from two aspects: (1) the first stage can be trained on diverse 2D datasets to reduce the risk of over-fitting to limited appearance; (2) the second stage can be trained on diverse AGR synthesized from a large number of virtual cameras and poses. It outperforms the SOTA methods without using any paired images and 3D poses from the benchmarks, which paves the way for practical applications. Code is available at https://github.com/wkom/VirtualPose.
Context Modeling in 3D Human Pose Estimation: A Unified Perspective
Mar 30, 2021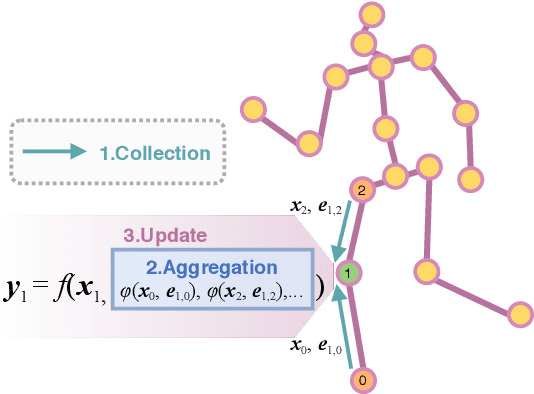
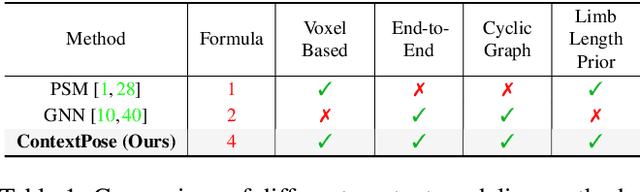
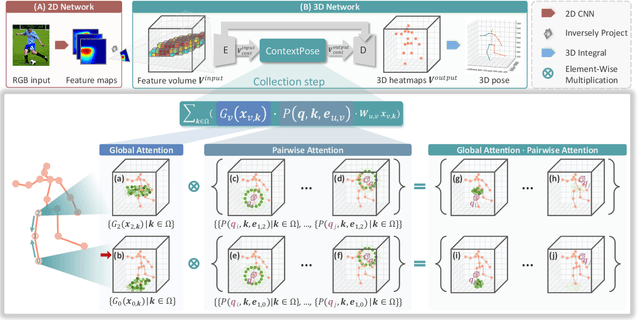
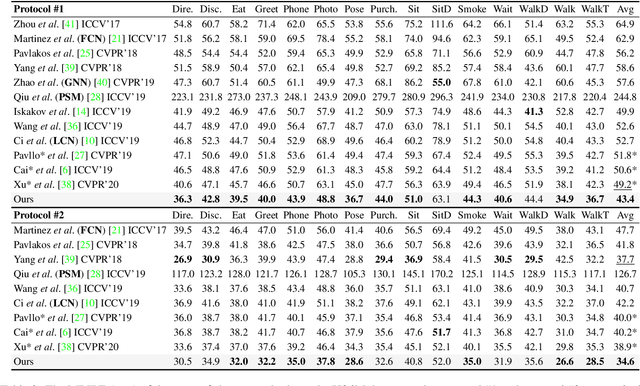
Estimating 3D human pose from a single image suffers from severe ambiguity since multiple 3D joint configurations may have the same 2D projection. The state-of-the-art methods often rely on context modeling methods such as pictorial structure model (PSM) or graph neural network (GNN) to reduce ambiguity. However, there is no study that rigorously compares them side by side. So we first present a general formula for context modeling in which both PSM and GNN are its special cases. By comparing the two methods, we found that the end-to-end training scheme in GNN and the limb length constraints in PSM are two complementary factors to improve results. To combine their advantages, we propose ContextPose based on attention mechanism that allows enforcing soft limb length constraints in a deep network. The approach effectively reduces the chance of getting absurd 3D pose estimates with incorrect limb lengths and achieves state-of-the-art results on two benchmark datasets. More importantly, the introduction of limb length constraints into deep networks enables the approach to achieve much better generalization performance.
Attentive Generative Adversarial Network for Raindrop Removal from a Single Image
May 06, 2018
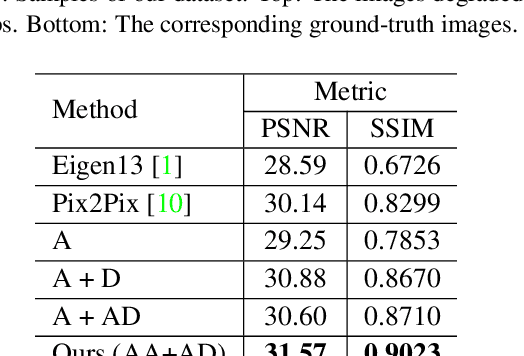
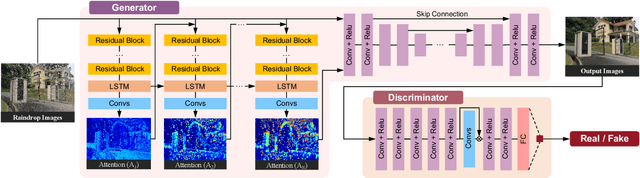

Raindrops adhered to a glass window or camera lens can severely hamper the visibility of a background scene and degrade an image considerably. In this paper, we address the problem by visually removing raindrops, and thus transforming a raindrop degraded image into a clean one. The problem is intractable, since first the regions occluded by raindrops are not given. Second, the information about the background scene of the occluded regions is completely lost for most part. To resolve the problem, we apply an attentive generative network using adversarial training. Our main idea is to inject visual attention into both the generative and discriminative networks. During the training, our visual attention learns about raindrop regions and their surroundings. Hence, by injecting this information, the generative network will pay more attention to the raindrop regions and the surrounding structures, and the discriminative network will be able to assess the local consistency of the restored regions. This injection of visual attention to both generative and discriminative networks is the main contribution of this paper. Our experiments show the effectiveness of our approach, which outperforms the state of the art methods quantitatively and qualitatively.