 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualPose: Learning Generalizable 3D Human Pose Models from Virtual Data
Paper and Code

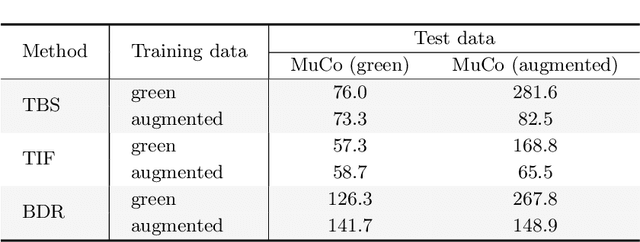
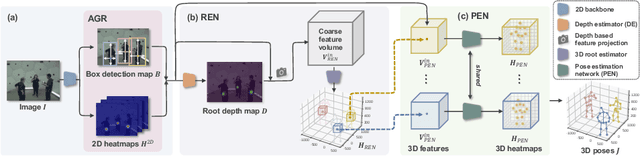

While monocular 3D pose estimation seems to have achieved very accurate results on the public datasets, their generalization ability is largely overlooked. In this work, we perform a systematic evaluation of the existing methods and find that they get notably larger errors when tested on different cameras, human poses and appearance. To address the problem, we introduce VirtualPose, a two-stage learning framework to exploit the hidden "free lunch" specific to this task, i.e. generating infinite number of poses and cameras for training models at no cost. To that end, the first stage transforms images to abstract geometry representations (AGR), and then the second maps them to 3D poses. It addresses the generalization issue from two aspects: (1) the first stage can be trained on diverse 2D datasets to reduce the risk of over-fitting to limited appearance; (2) the second stage can be trained on diverse AGR synthesized from a large number of virtual cameras and poses. It outperforms the SOTA methods without using any paired images and 3D poses from the benchmarks, which paves the way for practical applications. Code is available at https://github.com/wkom/VirtualPose.