 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResonant Minds: Closed-Loop Social Avatars with Theory of Mind
Jun 04, 2026Creating lifelike digital humans with genuine social intelligence requires unifying cognitive reasoning and multimodal generation within a coherent framework. Current approaches treat these as separate tasks: Large Language Models excel at dialogue but lack embodied expression, while diffusion-based talking head models achieve visual fidelity but ignore social cognition. To bridge this gap, we propose a closed-loop dual-agent framework integrating perception, social reasoning, and expression into a continuous interaction cycle. The perception module analyzes partners' multimodal behaviors from video, while the social reasoning module infers hidden mental states through Theory of Mind and selects responses via an ensemble mechanism. The expression module then generates emotion-controllable dual-agent videos synthesizing both speaker speech and expression alongside listener reactive behaviors, capturing bidirectional dynamics absent in prior work. We construct a hierarchical Persona-Scenario dataset with psychologically grounded personas and private social goals to support evaluation under information asymmetry. Experiments on this dataset demonstrate competitive or superior performance on both dialogue quality and video generation metrics. Notably, our method surpasses even the full-information Script mode on key dialogue quality dimensions, suggesting that explicit mental state inference under uncertainty can elicit more thoughtful dialogue than unrestricted information access.
REST3D: Reconstructing Physically Stable 3D Scenes from a Single Image
May 28, 2026Reconstructing physically stable 3D scenes from a single RGB image enables casual images to be converted into simulation-ready digital assets for applications such as immersive interaction and content creation. However, existing single-image reconstruction methods fall short in capturing the physical structure of a scene. As a result, they often produce geometrically plausible but physically inconsistent results, including object floating and penetration, which lead to unstable behavior in physics simulations. Image-conditioned scene generation methods improve physical plausibility but often rely on strong scene priors, yielding plausible yet inaccurate object arrangements that fail to match the input image. We propose REST3D, a single-image reconstruction framework that can reconstruct physically stable 3D scenes by integrating physical scene understanding with physics-constrained refinement. We first introduce an agentic physical scene understanding technique that constructs a scene-tree representation capturing object physical states and inter-object relationships from a gravity-support perspective, providing a structural prior for reconstruction. Leveraging this structure, we initialize the scene using image-to-3D models, followed by scene-tree-guided alignment and physics-constrained optimization to resolve physical violations while preserving visual consistency with the input image. Experiments show that our method significantly reduces physical errors and improves simulation stability on both synthetic and real-world datasets while maintaining strong reconstruction quality. We further demonstrate the reconstructed scenes in VR-based human-object interaction, showing their potential for immersive applications.
How Label Imbalance Shapes Geometry: A General Spectral Analysis of Multi-Label Neural Collapse
May 03, 2026This work investigates the phenomenon of Neural Collapse (NC) in multi-label classification, extending its conceptual framework from multi-class learning to general correlated and imbalanced multi-label settings. Although recent studies have identified a ''tag-wise averaging'' structure for multi-label features, this view relies on implicit assumptions of label balance and combinatorial symmetry. Consequently, it fails to account for the geometrical distortions caused by intrinsic label correlations and data imbalance, which are common in practice. We resolve the multiplicity-one imbalance conjecture raised by Li et al. (2024), showing that higher-multiplicity prototypes obey a class-frequency-weighted synthesis rule rather than uniform averaging. To address this, we propose a rigorous spectral-control framework to analyze the terminal phase of multi-label learning under general imbalanced conditions. We introduce the label covariance spectrum $κ_m$, a scalar controlling the distribution-dependent lower-bound geometry, derived from the second-order moment matrix of the label distribution. Contrary to the averaging perspective, our analysis reveals that the centered label covariance spectrum controls the stability of terminal geometry by quantifying the weakest centered inter-class contrast directions. We prove that the classical Tag-wise Averaging emerges only as a special case under perfect orthogonality. Numerical experiments on synthetic distributions validate our theoretical bounds. This work resolves the scaled-average aspect of the imbalance conjecture and establishes a unifying theoretical framework that extends Neural Collapse to complex, imbalanced multi-label settings.
Visually-grounded Humanoid Agents
Apr 09, 2026Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
RichControl: Structure- and Appearance-Rich Training-Free Spatial Control for Text-to-Image Generation
Jul 03, 2025Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., depth or pose maps) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. By revisiting existing methods, we identify a core limitation: the synchronous injection of condition features fails to account for the trade-off between domain alignment and structural preservation during denoising. Inspired by this observation, we propose a flexible feature injection framework that decouples the injection timestep from the denoising process. At its core is a structure-rich injection module, which enables the model to better adapt to the evolving interplay between alignment and structure preservation throughout the diffusion steps, resulting in more faithful structural generation. In addition, we introduce appearance-rich prompting and a restart refinement strategy to further enhance appearance control and visual quality. Together, these designs enable training-free generation that is both structure-rich and appearance-rich. Extensive experiments show that our approach achieves state-of-the-art performance across diverse zero-shot conditioning scenarios.
Generalizable Neural Electromagnetic Inverse Scattering
Jun 26, 2025



Solving Electromagnetic Inverse Scattering Problems (EISP) is fundamental in applications such as medical imaging, where the goal is to reconstruct the relative permittivity from scattered electromagnetic field. This inverse process is inherently ill-posed and highly nonlinear, making it particularly challenging. A recent machine learning-based approach, Img-Interiors, shows promising results by leveraging continuous implicit functions. However, it requires case-specific optimization, lacks generalization to unseen data, and fails under sparse transmitter setups (e.g., with only one transmitter). To address these limitations, we revisit EISP from a physics-informed perspective, reformulating it as a two stage inverse transmission-scattering process. This formulation reveals the induced current as a generalizable intermediate representation, effectively decoupling the nonlinear scattering process from the ill-posed inverse problem. Built on this insight, we propose the first generalizable physics-driven framework for EISP, comprising a current estimator and a permittivity solver, working in an end-to-end manner. The current estimator explicitly learns the induced current as a physical bridge between the incident and scattered field, while the permittivity solver computes the relative permittivity directly from the estimated induced current. This design enables data-driven training and generalizable feed-forward prediction of relative permittivity on unseen data while maintaining strong robustness to transmitter sparsity. Extensive experiments show that our method outperforms state-of-the-art approaches in reconstruction accuracy, generalization, and robustness. This work offers a fundamentally new perspective on electromagnetic inverse scattering and represents a major step toward cost-effective practical solutions for electromagnetic imaging.
Free-form Generation Enhances Challenging Clothed Human Modeling
Nov 29, 2024



Achieving realistic animated human avatars requires accurate modeling of pose-dependent clothing deformations. Existing learning-based methods heavily rely on the Linear Blend Skinning (LBS) of minimally-clothed human models like SMPL to model deformation. However, these methods struggle to handle loose clothing, such as long dresses, where the canonicalization process becomes ill-defined when the clothing is far from the body, leading to disjointed and fragmented results. To overcome this limitation, we propose a novel hybrid framework to model challenging clothed humans. Our core idea is to use dedicated strategies to model different regions, depending on whether they are close to or distant from the body. Specifically, we segment the human body into three categories: unclothed, deformed, and generated. We simply replicate unclothed regions that require no deformation. For deformed regions close to the body, we leverage LBS to handle the deformation. As for the generated regions, which correspond to loose clothing areas, we introduce a novel free-form, part-aware generator to model them, as they are less affected by movements. This free-form generation paradigm brings enhanced flexibility and expressiveness to our hybrid framework, enabling it to capture the intricate geometric details of challenging loose clothing, such as skirts and dresses. Experimental results on the benchmark dataset featuring loose clothing demonstrate that our method achieves state-of-the-art performance with superior visual fidelity and realism, particularly in the most challenging cases.
SAT-HMR: Real-Time Multi-Person 3D Mesh Estimation via Scale-Adaptive Tokens
Nov 29, 2024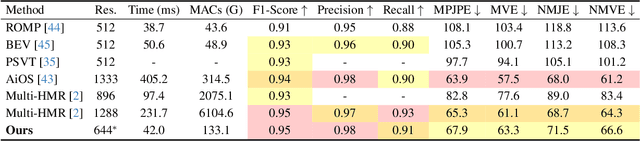
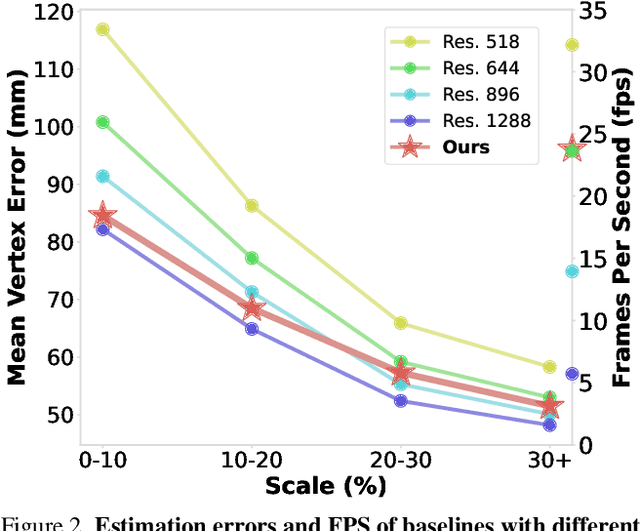
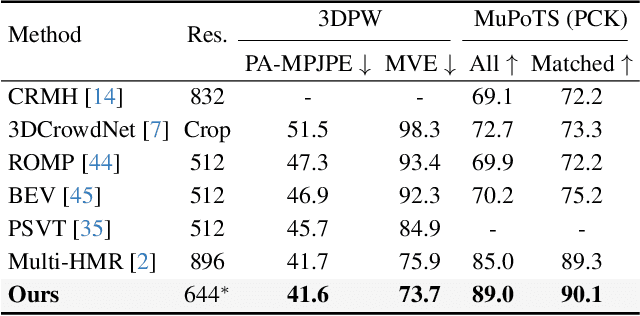
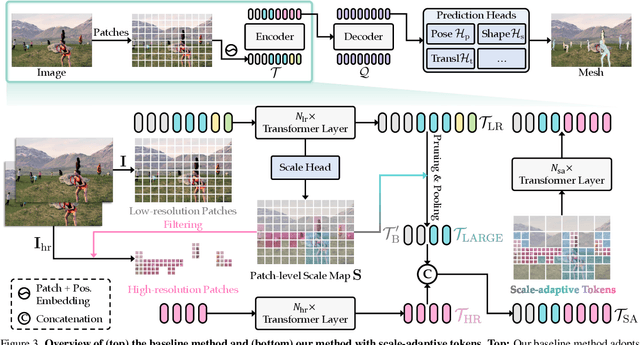
We propose a one-stage framework for real-time multi-person 3D human mesh estimation from a single RGB image. While current one-stage methods, which follow a DETR-style pipeline, achieve state-of-the-art (SOTA) performance with high-resolution inputs, we observe that this particularly benefits the estimation of individuals in smaller scales of the image (e.g., those far from the camera), but at the cost of significantly increased computation overhead. To address this, we introduce scale-adaptive tokens that are dynamically adjusted based on the relative scale of each individual in the image within the DETR framework. Specifically, individuals in smaller scales are processed at higher resolutions, larger ones at lower resolutions, and background regions are further distilled. These scale-adaptive tokens more efficiently encode the image features, facilitating subsequent decoding to regress the human mesh, while allowing the model to allocate computational resources more effectively and focus on more challenging cases. Experiments show that our method preserves the accuracy benefits of high-resolution processing while substantially reducing computational cost, achieving real-time inference with performance comparable to SOTA methods.
AlphaChimp: Tracking and Behavior Recognition of Chimpanzees
Oct 22, 2024



Understanding non-human primate behavior is crucial for improving animal welfare, modeling social behavior, and gaining insights into both distinctly human and shared behaviors. Despite recent advances in computer vision, automated analysis of primate behavior remains challenging due to the complexity of their social interactions and the lack of specialized algorithms. Existing methods often struggle with the nuanced behaviors and frequent occlusions characteristic of primate social dynamics. This study aims to develop an effective method for automated detection, tracking, and recognition of chimpanzee behaviors in video footage. Here we show that our proposed method, AlphaChimp, an end-to-end approach that simultaneously detects chimpanzee positions and estimates behavior categories from videos, significantly outperforms existing methods in behavior recognition. AlphaChimp achieves approximately 10% higher tracking accuracy and a 20% improvement in behavior recognition compared to state-of-the-art methods, particularly excelling in the recognition of social behaviors. This superior performance stems from AlphaChimp's innovative architecture, which integrates temporal feature fusion with a Transformer-based self-attention mechanism, enabling more effective capture and interpretation of complex social interactions among chimpanzees. Our approach bridges the gap between computer vision and primatology, enhancing technical capabilities and deepening our understanding of primate communication and sociality. We release our code and models and hope this will facilitate future research in animal social dynamics. This work contributes to ethology, cognitive science, and artificial intelligence, offering new perspectives on social intelligence.
Scaling Up Dynamic Human-Scene Interaction Modeling
Mar 13, 2024Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS, we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.