 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBIL: Collective Behavior Imitation Learning for Fish from Real Videos
Mar 31, 2025

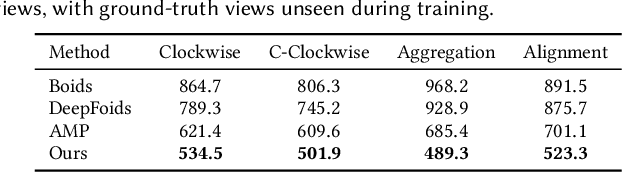
Reproducing realistic collective behaviors presents a captivating yet formidable challenge. Traditional rule-based methods rely on hand-crafted principles, limiting motion diversity and realism in generated collective behaviors. Recent imitation learning methods learn from data but often require ground truth motion trajectories and struggle with authenticity, especially in high-density groups with erratic movements. In this paper, we present a scalable approach, Collective Behavior Imitation Learning (CBIL), for learning fish schooling behavior directly from videos, without relying on captured motion trajectories. Our method first leverages Video Representation Learning, where a Masked Video AutoEncoder (MVAE) extracts implicit states from video inputs in a self-supervised manner. The MVAE effectively maps 2D observations to implicit states that are compact and expressive for following the imitation learning stage. Then, we propose a novel adversarial imitation learning method to effectively capture complex movements of the schools of fish, allowing for efficient imitation of the distribution for motion patterns measured in the latent space. It also incorporates bio-inspired rewards alongside priors to regularize and stabilize training. Once trained, CBIL can be used for various animation tasks with the learned collective motion priors. We further show its effectiveness across different species. Finally, we demonstrate the application of our system in detecting abnormal fish behavior from in-the-wild videos.
Zero-Shot Human-Object Interaction Synthesis with Multimodal Priors
Mar 25, 2025Human-object interaction (HOI) synthesis is important for various applications, ranging from virtual reality to robotics. However, acquiring 3D HOI data is challenging due to its complexity and high cost, limiting existing methods to the narrow diversity of object types and interaction patterns in training datasets. This paper proposes a novel zero-shot HOI synthesis framework without relying on end-to-end training on currently limited 3D HOI datasets. The core idea of our method lies in leveraging extensive HOI knowledge from pre-trained Multimodal Models. Given a text description, our system first obtains temporally consistent 2D HOI image sequences using image or video generation models, which are then uplifted to 3D HOI milestones of human and object poses. We employ pre-trained human pose estimation models to extract human poses and introduce a generalizable category-level 6-DoF estimation method to obtain the object poses from 2D HOI images. Our estimation method is adaptive to various object templates obtained from text-to-3D models or online retrieval. A physics-based tracking of the 3D HOI kinematic milestone is further applied to refine both body motions and object poses, yielding more physically plausible HOI generation results. The experimental results demonstrate that our method is capable of generating open-vocabulary HOIs with physical realism and semantic diversity.
SIMS: Simulating Human-Scene Interactions with Real World Script Planning
Nov 29, 2024Simulating long-term human-scene interaction is a challenging yet fascinating task. Previous works have not effectively addressed the generation of long-term human scene interactions with detailed narratives for physics-based animation. This paper introduces a novel framework for the planning and controlling of long-horizon physical plausible human-scene interaction. On the one hand, films and shows with stylish human locomotions or interactions with scenes are abundantly available on the internet, providing a rich source of data for script planning. On the other hand, Large Language Models (LLMs) can understand and generate logical storylines. This motivates us to marry the two by using an LLM-based pipeline to extract scripts from videos, and then employ LLMs to imitate and create new scripts, capturing complex, time-series human behaviors and interactions with environments. By leveraging this, we utilize a dual-aware policy that achieves both language comprehension and scene understanding to guide character motions within contextual and spatial constraints. To facilitate training and evaluation, we contribute a comprehensive planning dataset containing diverse motion sequences extracted from real-world videos and expand them with large language models. We also collect and re-annotate motion clips from existing kinematic datasets to enable our policy learn diverse skills. Extensive experiments demonstrate the effectiveness of our framework in versatile task execution and its generalization ability to various scenarios, showing remarkably enhanced performance compared with existing methods. Our code and data will be publicly available soon.
Social Motion Prediction with Cognitive Hierarchies
Nov 08, 2023Humans exhibit a remarkable capacity for anticipating the actions of others and planning their own actions accordingly. In this study, we strive to replicate this ability by addressing the social motion prediction problem. We introduce a new benchmark, a novel formulation, and a cognition-inspired framework. We present Wusi, a 3D multi-person motion dataset under the context of team sports, which features intense and strategic human interactions and diverse pose distributions. By reformulating the problem from a multi-agent reinforcement learning perspective, we incorporate behavioral cloning and generative adversarial imitation learning to boost learning efficiency and generalization. Furthermore, we take into account the cognitive aspects of the human social action planning process and develop a cognitive hierarchy framework to predict strategic human social interactions. We conduct comprehensive experiments to validate the effectiveness of our proposed dataset and approach. Code and data are available at https://walter0807.github.io/Social-CH/.
Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Oct 05, 2022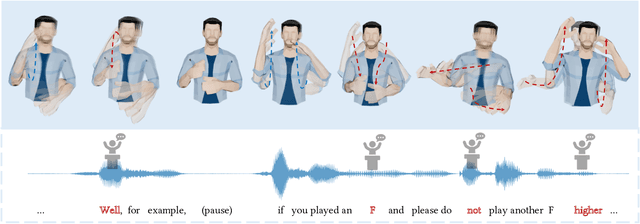
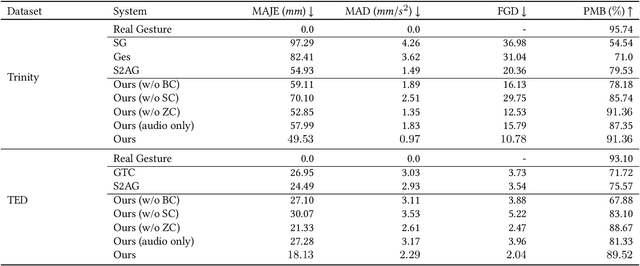
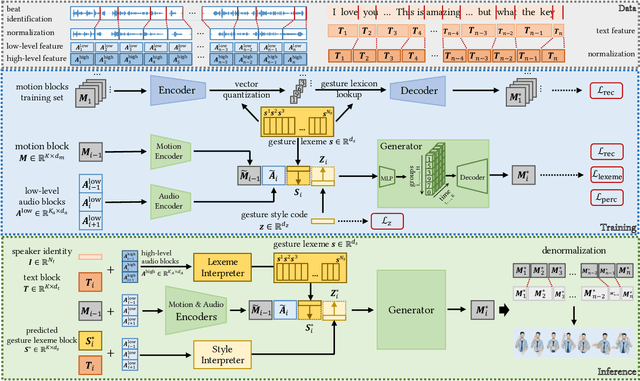

Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.