 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMD: A Simple Baseline for More General Human Motion Generation via Training-free Retrieval-Augmented Motion Diffuse
Dec 05, 2024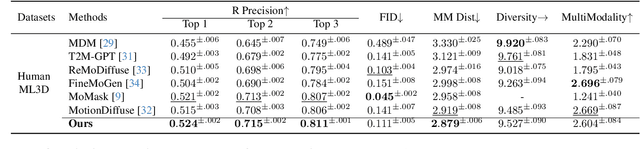
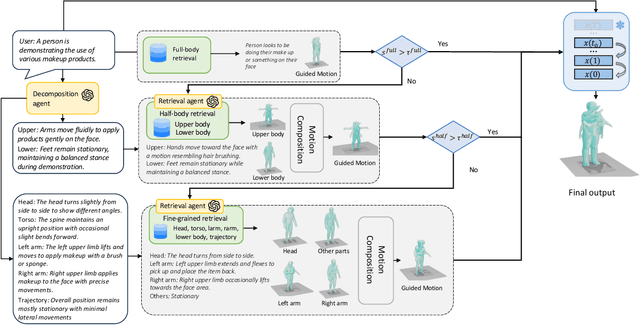

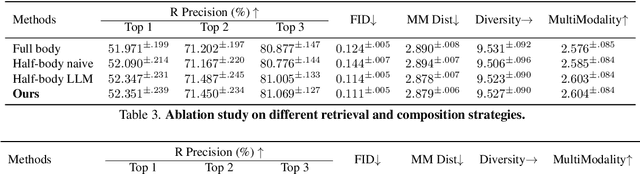
While motion generation has made substantial progress, its practical application remains constrained by dataset diversity and scale, limiting its ability to handle out-of-distribution scenarios. To address this, we propose a simple and effective baseline, RMD, which enhances the generalization of motion generation through retrieval-augmented techniques. Unlike previous retrieval-based methods, RMD requires no additional training and offers three key advantages: (1) the external retrieval database can be flexibly replaced; (2) body parts from the motion database can be reused, with an LLM facilitating splitting and recombination; and (3) a pre-trained motion diffusion model serves as a prior to improve the quality of motions obtained through retrieval and direct combination. Without any training, RMD achieves state-of-the-art performance, with notable advantages on out-of-distribution data.
It Takes Two: Real-time Co-Speech Two-person's Interaction Generation via Reactive Auto-regressive Diffusion Model
Dec 03, 2024



Conversational scenarios are very common in real-world settings, yet existing co-speech motion synthesis approaches often fall short in these contexts, where one person's audio and gestures will influence the other's responses. Additionally, most existing methods rely on offline sequence-to-sequence frameworks, which are unsuitable for online applications. In this work, we introduce an audio-driven, auto-regressive system designed to synthesize dynamic movements for two characters during a conversation. At the core of our approach is a diffusion-based full-body motion synthesis model, which is conditioned on the past states of both characters, speech audio, and a task-oriented motion trajectory input, allowing for flexible spatial control. To enhance the model's ability to learn diverse interactions, we have enriched existing two-person conversational motion datasets with more dynamic and interactive motions. We evaluate our system through multiple experiments to show it outperforms across a variety of tasks, including single and two-person co-speech motion generation, as well as interactive motion generation. To the best of our knowledge, this is the first system capable of generating interactive full-body motions for two characters from speech in an online manner.
SIMS: Simulating Human-Scene Interactions with Real World Script Planning
Nov 29, 2024Simulating long-term human-scene interaction is a challenging yet fascinating task. Previous works have not effectively addressed the generation of long-term human scene interactions with detailed narratives for physics-based animation. This paper introduces a novel framework for the planning and controlling of long-horizon physical plausible human-scene interaction. On the one hand, films and shows with stylish human locomotions or interactions with scenes are abundantly available on the internet, providing a rich source of data for script planning. On the other hand, Large Language Models (LLMs) can understand and generate logical storylines. This motivates us to marry the two by using an LLM-based pipeline to extract scripts from videos, and then employ LLMs to imitate and create new scripts, capturing complex, time-series human behaviors and interactions with environments. By leveraging this, we utilize a dual-aware policy that achieves both language comprehension and scene understanding to guide character motions within contextual and spatial constraints. To facilitate training and evaluation, we contribute a comprehensive planning dataset containing diverse motion sequences extracted from real-world videos and expand them with large language models. We also collect and re-annotate motion clips from existing kinematic datasets to enable our policy learn diverse skills. Extensive experiments demonstrate the effectiveness of our framework in versatile task execution and its generalization ability to various scenarios, showing remarkably enhanced performance compared with existing methods. Our code and data will be publicly available soon.
SENC: Handling Self-collision in Neural Cloth Simulation
Jul 17, 2024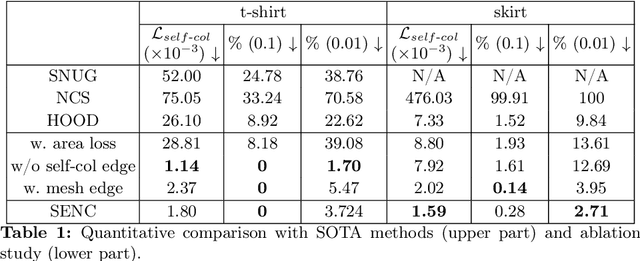
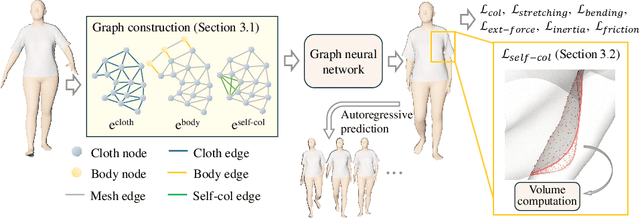
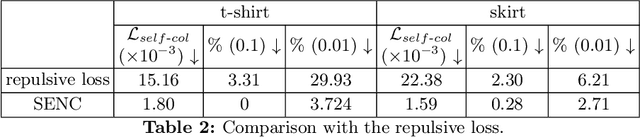
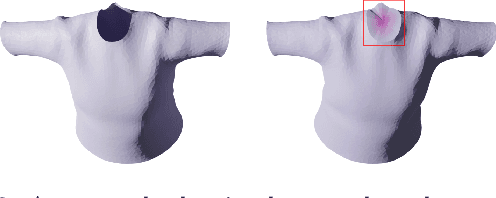
We present SENC, a novel self-supervised neural cloth simulator that addresses the challenge of cloth self-collision. This problem has remained unresolved due to the gap in simulation setup between recent collision detection and response approaches and self-supervised neural simulators. The former requires collision-free initial setups, while the latter necessitates random cloth instantiation during training. To tackle this issue, we propose a novel loss based on Global Intersection Analysis (GIA). This loss extracts the volume surrounded by the cloth region that forms the penetration. By constructing an energy based on this volume, our self-supervised neural simulator can effectively address cloth self-collisions. Moreover, we develop a self-collision-aware graph neural network capable of learning to handle self-collisions, even for parts that are topologically distant from one another. Additionally, we introduce an effective external force scheme that enables the simulation to learn the cloth's behavior in response to random external forces. We validate the efficacy of SENC through extensive quantitative and qualitative experiments, demonstrating that it effectively reduces cloth self-collision while maintaining high-quality animation results.
EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation
Dec 04, 2023

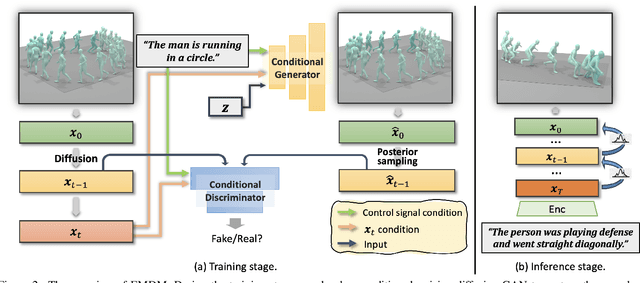
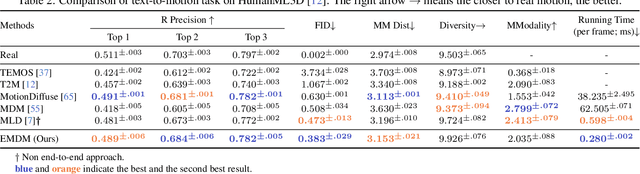
We introduce Efficient Motion Diffusion Model (EMDM) for fast and high-quality human motion generation. Although previous motion diffusion models have shown impressive results, they struggle to achieve fast generation while maintaining high-quality human motions. Motion latent diffusion has been proposed for efficient motion generation. However, effectively learning a latent space can be non-trivial in such a two-stage manner. Meanwhile, accelerating motion sampling by increasing the step size, e.g., DDIM, typically leads to a decline in motion quality due to the inapproximation of complex data distributions when naively increasing the step size. In this paper, we propose EMDM that allows for much fewer sample steps for fast motion generation by modeling the complex denoising distribution during multiple sampling steps. Specifically, we develop a Conditional Denoising Diffusion GAN to capture multimodal data distributions conditioned on both control signals, i.e., textual description and denoising time step. By modeling the complex data distribution, a larger sampling step size and fewer steps are achieved during motion synthesis, significantly accelerating the generation process. To effectively capture the human dynamics and reduce undesired artifacts, we employ motion geometric loss during network training, which improves the motion quality and training efficiency. As a result, EMDM achieves a remarkable speed-up at the generation stage while maintaining high-quality motion generation in terms of fidelity and diversity.
VINECS: Video-based Neural Character Skinning
Jul 03, 2023Rigging and skinning clothed human avatars is a challenging task and traditionally requires a lot of manual work and expertise. Recent methods addressing it either generalize across different characters or focus on capturing the dynamics of a single character observed under different pose configurations. However, the former methods typically predict solely static skinning weights, which perform poorly for highly articulated poses, and the latter ones either require dense 3D character scans in different poses or cannot generate an explicit mesh with vertex correspondence over time. To address these challenges, we propose a fully automated approach for creating a fully rigged character with pose-dependent skinning weights, which can be solely learned from multi-view video. Therefore, we first acquire a rigged template, which is then statically skinned. Next, a coordinate-based MLP learns a skinning weights field parameterized over the position in a canonical pose space and the respective pose. Moreover, we introduce our pose- and view-dependent appearance field allowing us to differentiably render and supervise the posed mesh using multi-view imagery. We show that our approach outperforms state-of-the-art while not relying on dense 4D scans.
Skeleton-free Pose Transfer for Stylized 3D Characters
Jul 28, 2022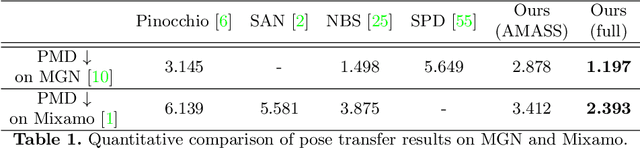
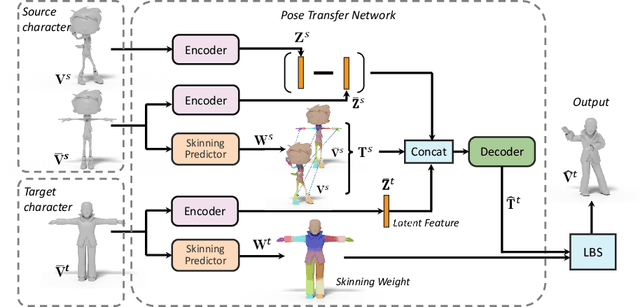
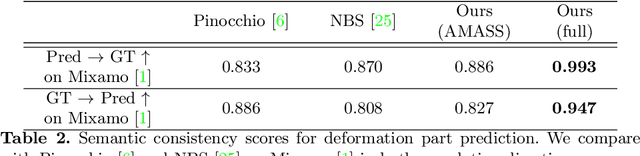

We present the first method that automatically transfers poses between stylized 3D characters without skeletal rigging. In contrast to previous attempts to learn pose transformations on fixed or topology-equivalent skeleton templates, our method focuses on a novel scenario to handle skeleton-free characters with diverse shapes, topologies, and mesh connectivities. The key idea of our method is to represent the characters in a unified articulation model so that the pose can be transferred through the correspondent parts. To achieve this, we propose a novel pose transfer network that predicts the character skinning weights and deformation transformations jointly to articulate the target character to match the desired pose. Our method is trained in a semi-supervised manner absorbing all existing character data with paired/unpaired poses and stylized shapes. It generalizes well to unseen stylized characters and inanimate objects. We conduct extensive experiments and demonstrate the effectiveness of our method on this novel task.
TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style
Mar 15, 2020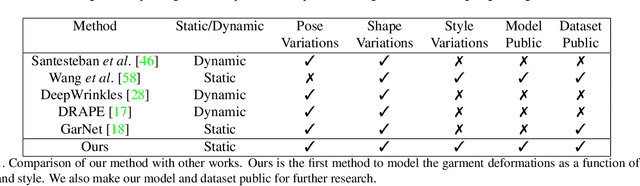
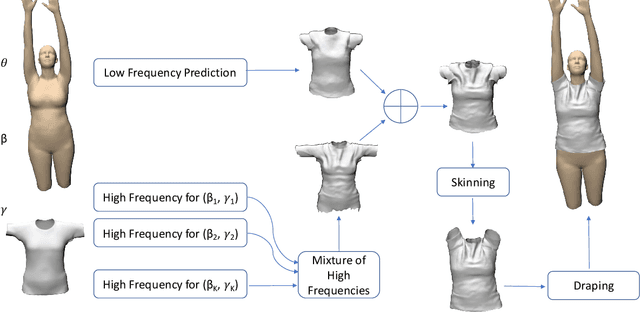


In this paper, we present TailorNet, a neural model which predicts clothing deformation in 3D as a function of three factors: pose, shape and style (garment geometry), while retaining wrinkle detail. This goes beyond prior models, which are either specific to one style and shape, or generalize to different shapes producing smooth results, despite being style specific. Our hypothesis is that (even non-linear) combinations of examples smooth out high frequency components such as fine-wrinkles, which makes learning the three factors jointly hard. At the heart of our technique is a decomposition of deformation into a high frequency and a low frequency component. While the low-frequency component is predicted from pose, shape and style parameters with an MLP, the high-frequency component is predicted with a mixture of shape-style specific pose models. The weights of the mixture are computed with a narrow bandwidth kernel to guarantee that only predictions with similar high-frequency patterns are combined. The style variation is obtained by computing, in a canonical pose, a subspace of deformation, which satisfies physical constraints such as inter-penetration, and draping on the body. TailorNet delivers 3D garments which retain the wrinkles from the physics based simulations (PBS) it is learned from, while running more than 1000 times faster. In contrast to PBS, TailorNet is easy to use and fully differentiable, which is crucial for computer vision algorithms. Several experiments demonstrate TailorNet produces more realistic results than prior work, and even generates temporally coherent deformations on sequences of the AMASS dataset, despite being trained on static poses from a different dataset. To stimulate further research in this direction, we will make a dataset consisting of 55800 frames, as well as our model publicly available at https://virtualhumans.mpi-inf.mpg.de/tailornet.