 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation
Dec 04, 2023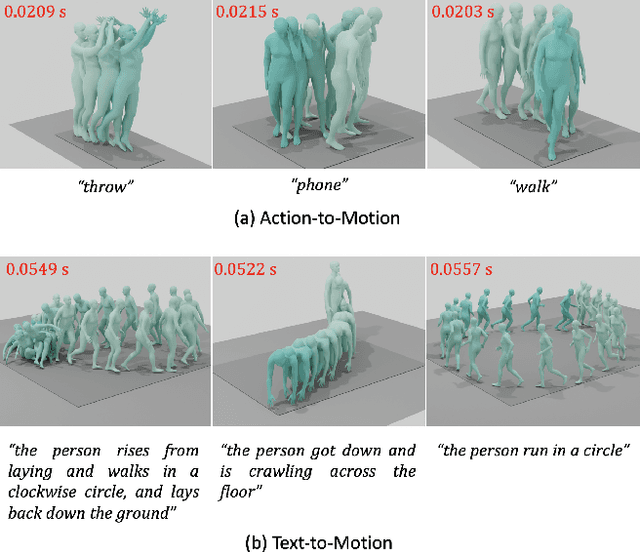

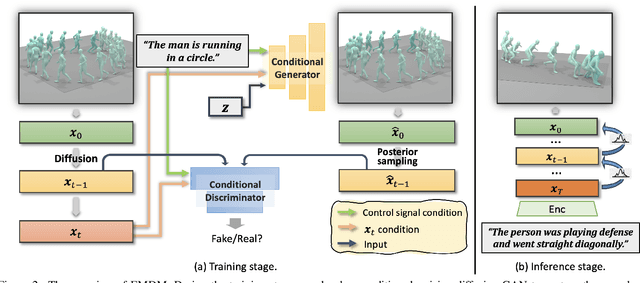
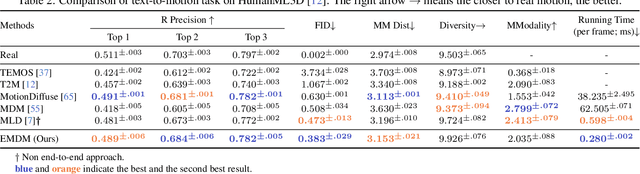
We introduce Efficient Motion Diffusion Model (EMDM) for fast and high-quality human motion generation. Although previous motion diffusion models have shown impressive results, they struggle to achieve fast generation while maintaining high-quality human motions. Motion latent diffusion has been proposed for efficient motion generation. However, effectively learning a latent space can be non-trivial in such a two-stage manner. Meanwhile, accelerating motion sampling by increasing the step size, e.g., DDIM, typically leads to a decline in motion quality due to the inapproximation of complex data distributions when naively increasing the step size. In this paper, we propose EMDM that allows for much fewer sample steps for fast motion generation by modeling the complex denoising distribution during multiple sampling steps. Specifically, we develop a Conditional Denoising Diffusion GAN to capture multimodal data distributions conditioned on both control signals, i.e., textual description and denoising time step. By modeling the complex data distribution, a larger sampling step size and fewer steps are achieved during motion synthesis, significantly accelerating the generation process. To effectively capture the human dynamics and reduce undesired artifacts, we employ motion geometric loss during network training, which improves the motion quality and training efficiency. As a result, EMDM achieves a remarkable speed-up at the generation stage while maintaining high-quality motion generation in terms of fidelity and diversity.
LC-NeRF: Local Controllable Face Generation in Neural Randiance Field
Feb 19, 2023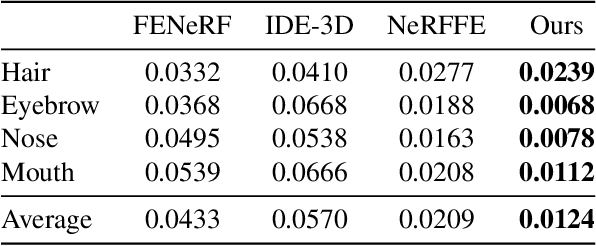
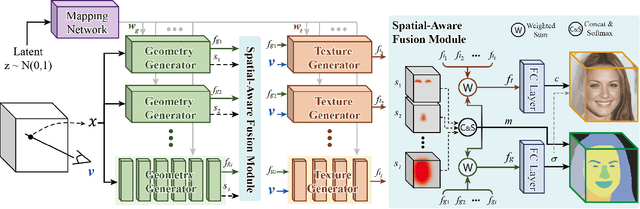
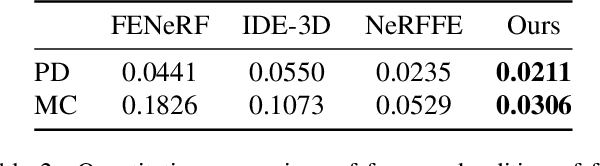

3D face generation has achieved high visual quality and 3D consistency thanks to the development of neural radiance fields (NeRF). Recently, to generate and edit 3D faces with NeRF representation, some methods are proposed and achieve good results in decoupling geometry and texture. The latent codes of these generative models affect the whole face, and hence modifications to these codes cause the entire face to change. However, users usually edit a local region when editing faces and do not want other regions to be affected. Since changes to the latent code affect global generation results, these methods do not allow for fine-grained control of local facial regions. To improve local controllability in NeRF-based face editing, we propose LC-NeRF, which is composed of a Local Region Generators Module and a Spatial-Aware Fusion Module, allowing for local geometry and texture control of local facial regions. Qualitative and quantitative evaluations show that our method provides better local editing than state-of-the-art face editing methods. Our method also performs well in downstream tasks, such as text-driven facial image editing.