 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy3E: Feed-Forward 3D Asset Editing via Rectified Voxel Flow
Feb 25, 2026Existing 3D editing methods rely on computationally intensive scene-by-scene iterative optimization and suffer from multi-view inconsistency. We propose an effective and fully feedforward 3D editing framework based on the TRELLIS generative backbone, capable of modifying 3D models from a single editing view. Our framework addresses two key issues: adapting training-free 2D editing to structured 3D representations, and overcoming the bottleneck of appearance fidelity in compressed 3D features. To ensure geometric consistency, we introduce Voxel FlowEdit, an edit-driven flow in the sparse voxel latent space that achieves globally consistent 3D deformation in a single pass. To restore high-fidelity details, we develop a normal-guided single to multi-view generation module as an external appearance prior, successfully recovering high-frequency textures. Experiments demonstrate that our method enables fast, globally consistent, and high-fidelity 3D model editing.
Vision-Based Early Fault Diagnosis and Self-Recovery for Strawberry Harvesting Robots
Jan 05, 2026Strawberry harvesting robots faced persistent challenges such as low integration of visual perception, fruit-gripper misalignment, empty grasping, and strawberry slippage from the gripper due to insufficient gripping force, all of which compromised harvesting stability and efficiency in orchard environments. To overcome these issues, this paper proposed a visual fault diagnosis and self-recovery framework that integrated multi-task perception with corrective control strategies. At the core of this framework was SRR-Net, an end-to-end multi-task perception model that simultaneously performed strawberry detection, segmentation, and ripeness estimation, thereby unifying visual perception with fault diagnosis. Based on this integrated perception, a relative error compensation method based on the simultaneous target-gripper detection was designed to address positional misalignment, correcting deviations when error exceeded the tolerance threshold. To mitigate empty grasping and fruit-slippage faults, an early abort strategy was implemented. A micro-optical camera embedded in the end-effector provided real-time visual feedback, enabling grasp detection during the deflating stage and strawberry slip prediction during snap-off through MobileNet V3-Small classifier and a time-series LSTM classifier. Experiments demonstrated that SRR-Net maintained high perception accuracy. For detection, it achieved a precision of 0.895 and recall of 0.813 on strawberries, and 0.972/0.958 on hands. In segmentation, it yielded a precision of 0.887 and recall of 0.747 for strawberries, and 0.974/0.947 for hands. For ripeness estimation, SRR-Net attained a mean absolute error of 0.035, while simultaneously supporting multi-task perception and sustaining a competitive inference speed of 163.35 FPS.
A Fast Path-Planning Method for Continuous Harvesting of Table-Top Grown Strawberries
Jan 09, 2025



Continuous harvesting and storage of multiple fruits in a single operation allow robots to significantly reduce the travel distance required for repetitive back-and-forth movements. Traditional collision-free path planning algorithms, such as Rapidly-Exploring Random Tree (RRT) and A-star (A), often fail to meet the demands of efficient continuous fruit harvesting due to their low search efficiency and the generation of excessive redundant points. This paper presents the Interactive Local Minima Search Algorithm (ILMSA), a fast path-planning method designed for the continuous harvesting of table-top grown strawberries. The algorithm featured an interactive node expansion strategy that iteratively extended and refined collision-free path segments based on local minima points. To enable the algorithm to function in 3D, the 3D environment was projected onto multiple 2D planes, generating optimal paths on each plane. The best path was then selected, followed by integrating and smoothing the 3D path segments. Simulations demonstrated that ILMSA outperformed existing methods, reducing path length by 21.5% and planning time by 97.1% compared to 3D-RRT, while achieving 11.6% shorter paths and 25.4% fewer nodes than the Lowest Point of the Strawberry (LPS) algorithm in 3D environments. In 2D, ILMSA achieved path lengths 16.2% shorter than A, 23.4% shorter than RRT, and 20.9% shorter than RRT-Connect, while being over 96% faster and generating significantly fewer nodes. Field tests confirmed ILMSA's suitability for complex agricultural tasks, having a combined planning and execution time and an average path length that were approximately 58% and 69%, respectively, of those achieved by the LPS algorithm.
LC-NeRF: Local Controllable Face Generation in Neural Randiance Field
Feb 19, 2023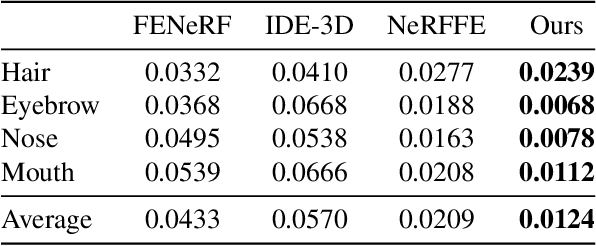
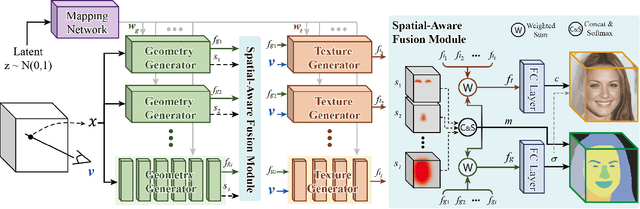
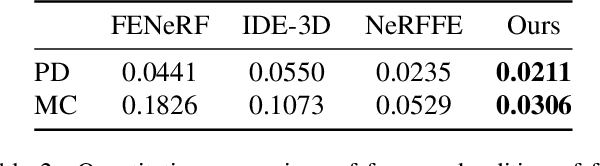

3D face generation has achieved high visual quality and 3D consistency thanks to the development of neural radiance fields (NeRF). Recently, to generate and edit 3D faces with NeRF representation, some methods are proposed and achieve good results in decoupling geometry and texture. The latent codes of these generative models affect the whole face, and hence modifications to these codes cause the entire face to change. However, users usually edit a local region when editing faces and do not want other regions to be affected. Since changes to the latent code affect global generation results, these methods do not allow for fine-grained control of local facial regions. To improve local controllability in NeRF-based face editing, we propose LC-NeRF, which is composed of a Local Region Generators Module and a Spatial-Aware Fusion Module, allowing for local geometry and texture control of local facial regions. Qualitative and quantitative evaluations show that our method provides better local editing than state-of-the-art face editing methods. Our method also performs well in downstream tasks, such as text-driven facial image editing.
Temporally Coherent Video Harmonization Using Adversarial Networks
Sep 05, 2018
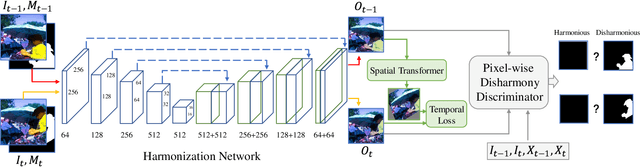


Compositing is one of the most important editing operations for images and videos. The process of improving the realism of composite results is often called harmonization. Previous approaches for harmonization mainly focus on images. In this work, we take one step further to attack the problem of video harmonization. Specifically, we train a convolutional neural network in an adversarial way, exploiting a pixel-wise disharmony discriminator to achieve more realistic harmonized results and introducing a temporal loss to increase temporal consistency between consecutive harmonized frames. Thanks to the pixel-wise disharmony discriminator, we are also able to relieve the need of input foreground masks. Since existing video datasets which have ground-truth foreground masks and optical flows are not sufficiently large, we propose a simple yet efficient method to build up a synthetic dataset supporting supervised training of the proposed adversarial network. Experiments show that training on our synthetic dataset generalizes well to the real-world composite dataset. Also, our method successfully incorporates temporal consistency during training and achieves more harmonious results than previous methods.
LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments
Jul 16, 2018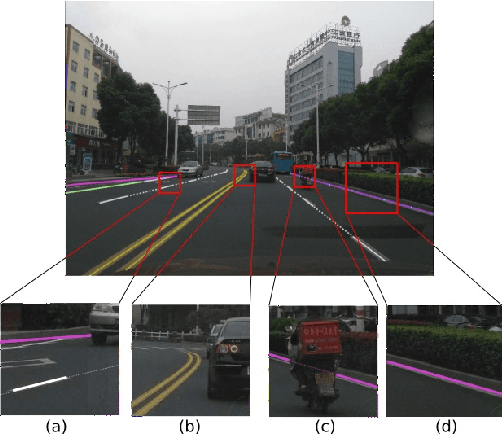
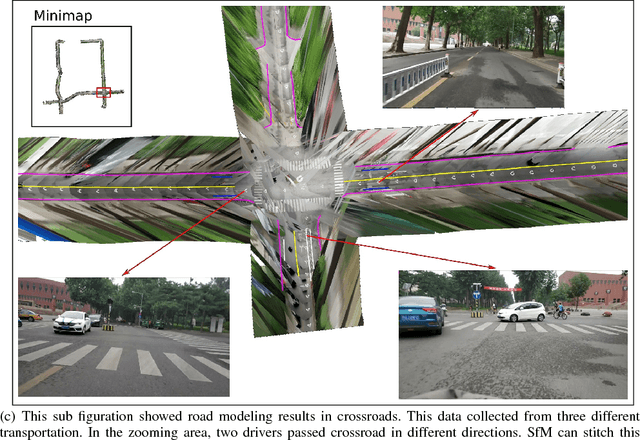
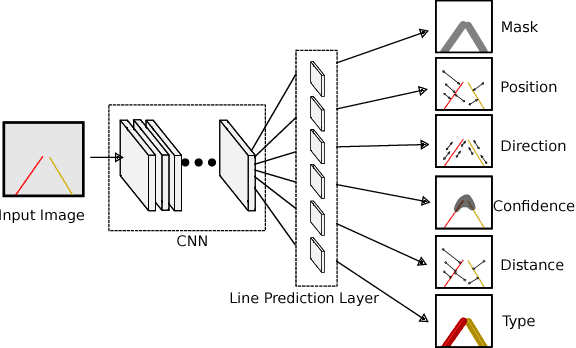
High Definition (HD) maps play an important role in modern traffic scenes. However, the development of HD maps coverage grows slowly because of the cost limitation. To efficiently model HD maps, we proposed a convolutional neural network with a novel prediction layer and a zoom module, called LineNet. It is designed for state-of-the-art lane detection in an unordered crowdsourced image dataset. And we introduced TTLane, a dataset for efficient lane detection in urban road modeling applications. Combining LineNet and TTLane, we proposed a pipeline to model HD maps with crowdsourced data for the first time. And the maps can be constructed precisely even with inaccurate crowdsourced data.
A Comparative Study of Algorithms for Realtime Panoramic Video Blending
Dec 24, 2016
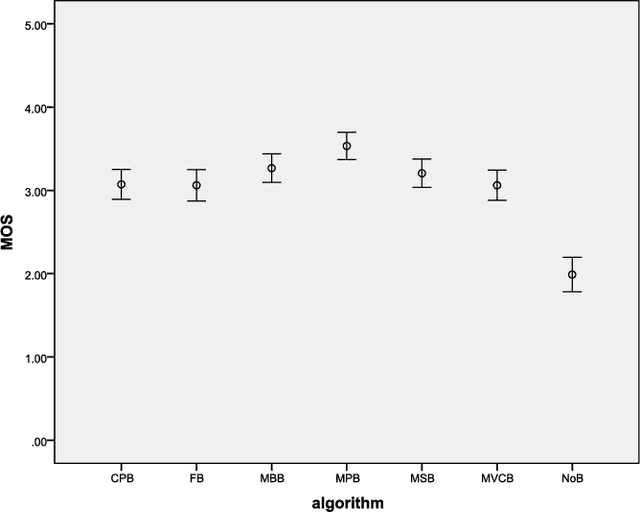


Unlike image blending algorithms, video blending algorithms have been little studied. In this paper, we investigate 6 popular blending algorithms---feather blending, multi-band blending, modified Poisson blending, mean value coordinate blending, multi-spline blending and convolution pyramid blending. We consider in particular realtime panoramic video blending, a key problem in various virtual reality tasks. To evaluate the performance of the 6 algorithms on this problem, we have created a video benchmark of several videos captured under various conditions. We analyze the time and memory needed by the above 6 algorithms, for both CPU and GPU implementations (where readily parallelizable). The visual quality provided by these algorithms is also evaluated both objectively and subjectively. The video benchmark and algorithm implementations are publicly available.
Appearance Harmonization for Single Image Shadow Removal
Mar 21, 2016
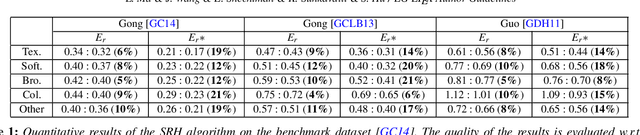


Shadows often create unwanted artifacts in photographs, and removing them can be very challenging. Previous shadow removal methods often produce de-shadowed regions that are visually inconsistent with the rest of the image. In this work we propose a fully automatic shadow region harmonization approach that improves the appearance compatibility of the de-shadowed region as typically produced by previous methods. It is based on a shadow-guided patch-based image synthesis approach that reconstructs the shadow region using patches sampled from non-shadowed regions. The result is then refined based on the reconstruction confidence to handle unique image patterns. Many shadow removal results and comparisons are show the effectiveness of our improvement. Quantitative evaluation on a benchmark dataset suggests that our automatic shadow harmonization approach effectively improves upon the state-of-the-art.