 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSGS: Bi-stage 3D Gaussian Splatting for Camera Motion Deblurring
Oct 14, 20253D Gaussian Splatting has exhibited remarkable capabilities in 3D scene reconstruction.However, reconstructing high-quality 3D scenes from motion-blurred images caused by camera motion poses a significant challenge.The performance of existing 3DGS-based deblurring methods are limited due to their inherent mechanisms, such as extreme dependence on the accuracy of camera poses and inability to effectively control erroneous Gaussian primitives densification caused by motion blur.To solve these problems, we introduce a novel framework, Bi-Stage 3D Gaussian Splatting, to accurately reconstruct 3D scenes from motion-blurred images.BSGS contains two stages. First, Camera Pose Refinement roughly optimizes camera poses to reduce motion-induced distortions. Second, with fixed rough camera poses, Global RigidTransformation further corrects motion-induced blur distortions.To alleviate multi-subframe gradient conflicts, we propose a subframe gradient aggregation strategy to optimize both stages.Furthermore, a space-time bi-stage optimization strategy is introduced to dynamically adjust primitive densification thresholds and prevent premature noisy Gaussian generation in blurred regions. Comprehensive experiments verify the effectiveness of our proposed deblurring method and show its superiority over the state of the arts.
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.
HF-VTON: High-Fidelity Virtual Try-On via Consistent Geometric and Semantic Alignment
May 26, 2025Virtual try-on technology has become increasingly important in the fashion and retail industries, enabling the generation of high-fidelity garment images that adapt seamlessly to target human models. While existing methods have achieved notable progress, they still face significant challenges in maintaining consistency across different poses. Specifically, geometric distortions lead to a lack of spatial consistency, mismatches in garment structure and texture across poses result in semantic inconsistency, and the loss or distortion of fine-grained details diminishes visual fidelity. To address these challenges, we propose HF-VTON, a novel framework that ensures high-fidelity virtual try-on performance across diverse poses. HF-VTON consists of three key modules: (1) the Appearance-Preserving Warp Alignment Module (APWAM), which aligns garments to human poses, addressing geometric deformations and ensuring spatial consistency; (2) the Semantic Representation and Comprehension Module (SRCM), which captures fine-grained garment attributes and multi-pose data to enhance semantic representation, maintaining structural, textural, and pattern consistency; and (3) the Multimodal Prior-Guided Appearance Generation Module (MPAGM), which integrates multimodal features and prior knowledge from pre-trained models to optimize appearance generation, ensuring both semantic and geometric consistency. Additionally, to overcome data limitations in existing benchmarks, we introduce the SAMP-VTONS dataset, featuring multi-pose pairs and rich textual annotations for a more comprehensive evaluation. Experimental results demonstrate that HF-VTON outperforms state-of-the-art methods on both VITON-HD and SAMP-VTONS, excelling in visual fidelity, semantic consistency, and detail preservation.
PointSFDA: Source-free Domain Adaptation for Point Cloud Completion
Mar 19, 2025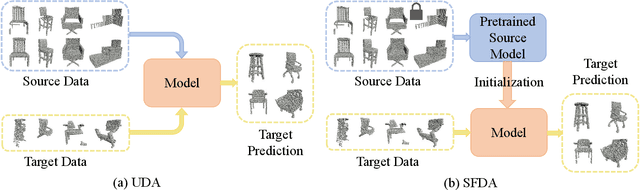



Conventional methods for point cloud completion, typically trained on synthetic datasets, face significant challenges when applied to out-of-distribution real-world scans. In this paper, we propose an effective yet simple source-free domain adaptation framework for point cloud completion, termed \textbf{PointSFDA}. Unlike unsupervised domain adaptation that reduces the domain gap by directly leveraging labeled source data, PointSFDA uses only a pretrained source model and unlabeled target data for adaptation, avoiding the need for inaccessible source data in practical scenarios. Being the first source-free domain adaptation architecture for point cloud completion, our method offers two core contributions. First, we introduce a coarse-to-fine distillation solution to explicitly transfer the global geometry knowledge learned from the source dataset. Second, as noise may be introduced due to domain gaps, we propose a self-supervised partial-mask consistency training strategy to learn local geometry information in the target domain. Extensive experiments have validated that our method significantly improves the performance of state-of-the-art networks in cross-domain shape completion. Our code is available at \emph{\textcolor{magenta}{https://github.com/Starak-x/PointSFDA}}.
GenPC: Zero-shot Point Cloud Completion via 3D Generative Priors
Feb 27, 2025



Existing point cloud completion methods, which typically depend on predefined synthetic training datasets, encounter significant challenges when applied to out-of-distribution, real-world scans. To overcome this limitation, we introduce a zero-shot completion framework, termed GenPC, designed to reconstruct high-quality real-world scans by leveraging explicit 3D generative priors. Our key insight is that recent feed-forward 3D generative models, trained on extensive internet-scale data, have demonstrated the ability to perform 3D generation from single-view images in a zero-shot setting. To harness this for completion, we first develop a Depth Prompting module that links partial point clouds with image-to-3D generative models by leveraging depth images as a stepping stone. To retain the original partial structure in the final results, we design the Geometric Preserving Fusion module that aligns the generated shape with input by adaptively adjusting its pose and scale. Extensive experiments on widely used benchmarks validate the superiority and generalizability of our approach, bringing us a step closer to robust real-world scan completion.
PointSea: Point Cloud Completion via Self-structure Augmentation
Feb 26, 2025Point cloud completion is a fundamental yet not well-solved problem in 3D vision. Current approaches often rely on 3D coordinate information and/or additional data (e.g., images and scanning viewpoints) to fill in missing parts. Unlike these methods, we explore self-structure augmentation and propose PointSea for global-to-local point cloud completion. In the global stage, consider how we inspect a defective region of a physical object, we may observe it from various perspectives for a better understanding. Inspired by this, PointSea augments data representation by leveraging self-projected depth images from multiple views. To reconstruct a compact global shape from the cross-modal input, we incorporate a feature fusion module to fuse features at both intra-view and inter-view levels. In the local stage, to reveal highly detailed structures, we introduce a point generator called the self-structure dual-generator. This generator integrates both learned shape priors and geometric self-similarities for shape refinement. Unlike existing efforts that apply a unified strategy for all points, our dual-path design adapts refinement strategies conditioned on the structural type of each point, addressing the specific incompleteness of each point. Comprehensive experiments on widely-used benchmarks demonstrate that PointSea effectively understands global shapes and generates local details from incomplete input, showing clear improvements over existing methods.
Cross-BERT for Point Cloud Pretraining
Dec 08, 2023



Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
FormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning
Oct 30, 2023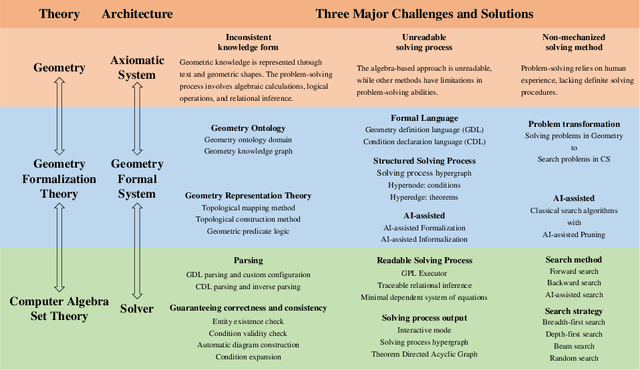
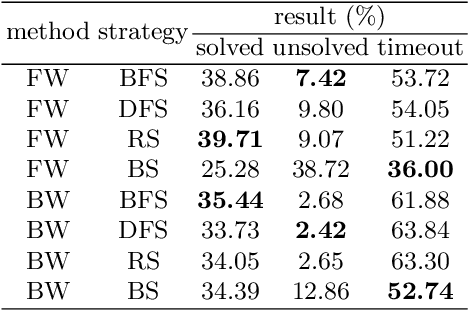
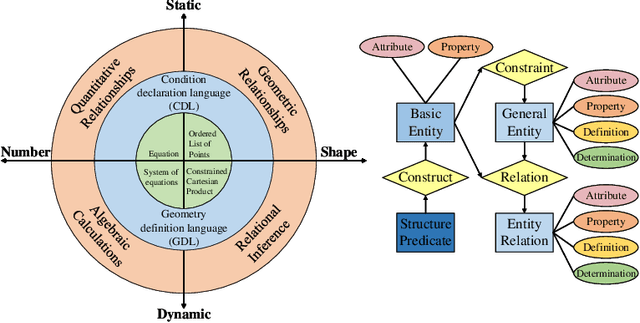
This is the first paper in a series of work we have accomplished over the past three years. In this paper, we have constructed a complete and compatible formal plane geometry system. This will serve as a crucial bridge between IMO-level plane geometry challenges and readable AI automated reasoning. With this formal system in place, we have been able to seamlessly integrate modern AI models with our formal system. Within this formal framework, AI is now capable of providing deductive reasoning solutions to IMO-level plane geometry problems, just like handling other natural languages, and these proofs are readable, traceable, and verifiable. We propose the geometry formalization theory (GFT) to guide the development of the geometry formal system. Based on the GFT, we have established the FormalGeo, which consists of 88 geometric predicates and 196 theorems. It can represent, validate, and solve IMO-level geometry problems. we also have crafted the FGPS (formal geometry problem solver) in Python. It serves as both an interactive assistant for verifying problem-solving processes and an automated problem solver, utilizing various methods such as forward search, backward search and AI-assisted search. We've annotated the FormalGeo7k dataset, containing 6,981 (expand to 186,832 through data augmentation) geometry problems with complete formal language annotations. Implementation of the formal system and experiments on the FormalGeo7k validate the correctness and utility of the GFT. The backward depth-first search method only yields a 2.42% problem-solving failure rate, and we can incorporate deep learning techniques to achieve lower one. The source code of FGPS and FormalGeo7k dataset are available at https://github.com/BitSecret/FormalGeo.
Style Generation: Image Synthesis based on Coarsely Matched Texts
Sep 08, 2023



Previous text-to-image synthesis algorithms typically use explicit textual instructions to generate/manipulate images accurately, but they have difficulty adapting to guidance in the form of coarsely matched texts. In this work, we attempt to stylize an input image using such coarsely matched text as guidance. To tackle this new problem, we introduce a novel task called text-based style generation and propose a two-stage generative adversarial network: the first stage generates the overall image style with a sentence feature, and the second stage refines the generated style with a synthetic feature, which is produced by a multi-modality style synthesis module. We re-filter one existing dataset and collect a new dataset for the task. Extensive experiments and ablation studies are conducted to validate our framework. The practical potential of our work is demonstrated by various applications such as text-image alignment and story visualization. Our datasets are published at https://www.kaggle.com/datasets/mengyaocui/style-generation.
SVDFormer: Complementing Point Cloud via Self-view Augmentation and Self-structure Dual-generator
Jul 17, 2023



In this paper, we propose a novel network, SVDFormer, to tackle two specific challenges in point cloud completion: understanding faithful global shapes from incomplete point clouds and generating high-accuracy local structures. Current methods either perceive shape patterns using only 3D coordinates or import extra images with well-calibrated intrinsic parameters to guide the geometry estimation of the missing parts. However, these approaches do not always fully leverage the cross-modal self-structures available for accurate and high-quality point cloud completion. To this end, we first design a Self-view Fusion Network that leverages multiple-view depth image information to observe incomplete self-shape and generate a compact global shape. To reveal highly detailed structures, we then introduce a refinement module, called Self-structure Dual-generator, in which we incorporate learned shape priors and geometric self-similarities for producing new points. By perceiving the incompleteness of each point, the dual-path design disentangles refinement strategies conditioned on the structural type of each point. SVDFormer absorbs the wisdom of self-structures, avoiding any additional paired information such as color images with precisely calibrated camera intrinsic parameters. Comprehensive experiments indicate that our method achieves state-of-the-art performance on widely-used benchmarks. Code will be available at https://github.com/czvvd/SVDFormer.