 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
Unified Representation Space for 3D Visual Grounding
Jun 17, 20253D visual grounding (3DVG) is a critical task in scene understanding that aims to identify objects in 3D scenes based on text descriptions. However, existing methods rely on separately pre-trained vision and text encoders, resulting in a significant gap between the two modalities in terms of spatial geometry and semantic categories. This discrepancy often causes errors in object positioning and classification. The paper proposes UniSpace-3D, which innovatively introduces a unified representation space for 3DVG, effectively bridging the gap between visual and textual features. Specifically, UniSpace-3D incorporates three innovative designs: i) a unified representation encoder that leverages the pre-trained CLIP model to map visual and textual features into a unified representation space, effectively bridging the gap between the two modalities; ii) a multi-modal contrastive learning module that further reduces the modality gap; iii) a language-guided query selection module that utilizes the positional and semantic information to identify object candidate points aligned with textual descriptions. Extensive experiments demonstrate that UniSpace-3D outperforms baseline models by at least 2.24% on the ScanRefer and Nr3D/Sr3D datasets. The code will be made available upon acceptance of the paper.
I Speak and You Find: Robust 3D Visual Grounding with Noisy and Ambiguous Speech Inputs
Jun 17, 2025Existing 3D visual grounding methods rely on precise text prompts to locate objects within 3D scenes. Speech, as a natural and intuitive modality, offers a promising alternative. Real-world speech inputs, however, often suffer from transcription errors due to accents, background noise, and varying speech rates, limiting the applicability of existing 3DVG methods. To address these challenges, we propose \textbf{SpeechRefer}, a novel 3DVG framework designed to enhance performance in the presence of noisy and ambiguous speech-to-text transcriptions. SpeechRefer integrates seamlessly with xisting 3DVG models and introduces two key innovations. First, the Speech Complementary Module captures acoustic similarities between phonetically related words and highlights subtle distinctions, generating complementary proposal scores from the speech signal. This reduces dependence on potentially erroneous transcriptions. Second, the Contrastive Complementary Module employs contrastive learning to align erroneous text features with corresponding speech features, ensuring robust performance even when transcription errors dominate. Extensive experiments on the SpeechRefer and peechNr3D datasets demonstrate that SpeechRefer improves the performance of existing 3DVG methods by a large margin, which highlights SpeechRefer's potential to bridge the gap between noisy speech inputs and reliable 3DVG, enabling more intuitive and practical multimodal systems.
Hierarchical Error Assessment of CAD Models for Aircraft Manufacturing-and-Measurement
Jun 12, 2025The most essential feature of aviation equipment is high quality, including high performance, high stability and high reliability. In this paper, we propose a novel hierarchical error assessment framework for aircraft CAD models within a manufacturing-and-measurement platform, termed HEA-MM. HEA-MM employs structured light scanners to obtain comprehensive 3D measurements of manufactured workpieces. The measured point cloud is registered with the reference CAD model, followed by an error analysis conducted at three hierarchical levels: global, part, and feature. At the global level, the error analysis evaluates the overall deviation of the scanned point cloud from the reference CAD model. At the part level, error analysis is performed on these patches underlying the point clouds. We propose a novel optimization-based primitive refinement method to obtain a set of meaningful patches of point clouds. Two basic operations, splitting and merging, are introduced to refine the coarse primitives. At the feature level, error analysis is performed on circular holes, which are commonly found in CAD models. To facilitate it, a two-stage algorithm is introduced for the detection of circular holes. First, edge points are identified using a tensor-voting algorithm. Then, multiple circles are fitted through a hypothesize-and-clusterize framework, ensuring accurate detection and analysis of the circular features. Experimental results on various aircraft CAD models demonstrate the effectiveness of our proposed method.
PointSFDA: Source-free Domain Adaptation for Point Cloud Completion
Mar 19, 2025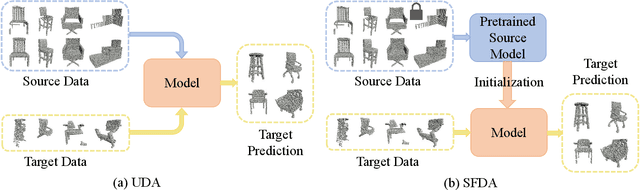



Conventional methods for point cloud completion, typically trained on synthetic datasets, face significant challenges when applied to out-of-distribution real-world scans. In this paper, we propose an effective yet simple source-free domain adaptation framework for point cloud completion, termed \textbf{PointSFDA}. Unlike unsupervised domain adaptation that reduces the domain gap by directly leveraging labeled source data, PointSFDA uses only a pretrained source model and unlabeled target data for adaptation, avoiding the need for inaccessible source data in practical scenarios. Being the first source-free domain adaptation architecture for point cloud completion, our method offers two core contributions. First, we introduce a coarse-to-fine distillation solution to explicitly transfer the global geometry knowledge learned from the source dataset. Second, as noise may be introduced due to domain gaps, we propose a self-supervised partial-mask consistency training strategy to learn local geometry information in the target domain. Extensive experiments have validated that our method significantly improves the performance of state-of-the-art networks in cross-domain shape completion. Our code is available at \emph{\textcolor{magenta}{https://github.com/Starak-x/PointSFDA}}.
PointSea: Point Cloud Completion via Self-structure Augmentation
Feb 26, 2025Point cloud completion is a fundamental yet not well-solved problem in 3D vision. Current approaches often rely on 3D coordinate information and/or additional data (e.g., images and scanning viewpoints) to fill in missing parts. Unlike these methods, we explore self-structure augmentation and propose PointSea for global-to-local point cloud completion. In the global stage, consider how we inspect a defective region of a physical object, we may observe it from various perspectives for a better understanding. Inspired by this, PointSea augments data representation by leveraging self-projected depth images from multiple views. To reconstruct a compact global shape from the cross-modal input, we incorporate a feature fusion module to fuse features at both intra-view and inter-view levels. In the local stage, to reveal highly detailed structures, we introduce a point generator called the self-structure dual-generator. This generator integrates both learned shape priors and geometric self-similarities for shape refinement. Unlike existing efforts that apply a unified strategy for all points, our dual-path design adapts refinement strategies conditioned on the structural type of each point, addressing the specific incompleteness of each point. Comprehensive experiments on widely-used benchmarks demonstrate that PointSea effectively understands global shapes and generates local details from incomplete input, showing clear improvements over existing methods.
Textured 3D Regenerative Morphing with 3D Diffusion Prior
Feb 20, 2025Textured 3D morphing creates smooth and plausible interpolation sequences between two 3D objects, focusing on transitions in both shape and texture. This is important for creative applications like visual effects in filmmaking. Previous methods rely on establishing point-to-point correspondences and determining smooth deformation trajectories, which inherently restrict them to shape-only morphing on untextured, topologically aligned datasets. This restriction leads to labor-intensive preprocessing and poor generalization. To overcome these challenges, we propose a method for 3D regenerative morphing using a 3D diffusion prior. Unlike previous methods that depend on explicit correspondences and deformations, our method eliminates the additional need for obtaining correspondence and uses the 3D diffusion prior to generate morphing. Specifically, we introduce a 3D diffusion model and interpolate the source and target information at three levels: initial noise, model parameters, and condition features. We then explore an Attention Fusion strategy to generate more smooth morphing sequences. To further improve the plausibility of semantic interpolation and the generated 3D surfaces, we propose two strategies: (a) Token Reordering, where we match approximate tokens based on semantic analysis to guide implicit correspondences in the denoising process of the diffusion model, and (b) Low-Frequency Enhancement, where we enhance low-frequency signals in the tokens to improve the quality of generated surfaces. Experimental results show that our method achieves superior smoothness and plausibility in 3D morphing across diverse cross-category object pairs, offering a novel regenerative method for 3D morphing with textured representations.
CrossTracker: Robust Multi-modal 3D Multi-Object Tracking via Cross Correction
Nov 28, 2024



The fusion of camera- and LiDAR-based detections offers a promising solution to mitigate tracking failures in 3D multi-object tracking (MOT). However, existing methods predominantly exploit camera detections to correct tracking failures caused by potential LiDAR detection problems, neglecting the reciprocal benefit of refining camera detections using LiDAR data. This limitation is rooted in their single-stage architecture, akin to single-stage object detectors, lacking a dedicated trajectory refinement module to fully exploit the complementary multi-modal information. To this end, we introduce CrossTracker, a novel two-stage paradigm for online multi-modal 3D MOT. CrossTracker operates in a coarse-to-fine manner, initially generating coarse trajectories and subsequently refining them through an independent refinement process. Specifically, CrossTracker incorporates three essential modules: i) a multi-modal modeling (M^3) module that, by fusing multi-modal information (images, point clouds, and even plane geometry extracted from images), provides a robust metric for subsequent trajectory generation. ii) a coarse trajectory generation (C-TG) module that generates initial coarse dual-stream trajectories, and iii) a trajectory refinement (TR) module that refines coarse trajectories through cross correction between camera and LiDAR streams. Comprehensive experiments demonstrate the superior performance of our CrossTracker over its eighteen competitors, underscoring its effectiveness in harnessing the synergistic benefits of camera and LiDAR sensors for robust multi-modal 3D MOT.
PointCG: Self-supervised Point Cloud Learning via Joint Completion and Generation
Nov 09, 2024


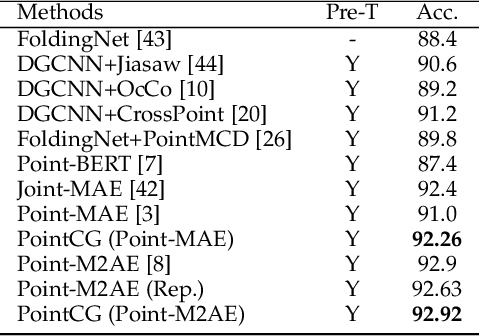
The core of self-supervised point cloud learning lies in setting up appropriate pretext tasks, to construct a pre-training framework that enables the encoder to perceive 3D objects effectively. In this paper, we integrate two prevalent methods, masked point modeling (MPM) and 3D-to-2D generation, as pretext tasks within a pre-training framework. We leverage the spatial awareness and precise supervision offered by these two methods to address their respective limitations: ambiguous supervision signals and insensitivity to geometric information. Specifically, the proposed framework, abbreviated as PointCG, consists of a Hidden Point Completion (HPC) module and an Arbitrary-view Image Generation (AIG) module. We first capture visible points from arbitrary views as inputs by removing hidden points. Then, HPC extracts representations of the inputs with an encoder and completes the entire shape with a decoder, while AIG is used to generate rendered images based on the visible points' representations. Extensive experiments demonstrate the superiority of the proposed method over the baselines in various downstream tasks. Our code will be made available upon acceptance.