 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneConductor: 3D Scene Generation from Single Image with Multi-Agent Orchestration
Jun 07, 2026Generating complete 3D scenes from a single image requires inferring globally consistent geometry, object relationships, and environmental context from inherently ambiguous visual evidence. Despite recent progress in joint layout-and-mesh generation, existing methods often rely on holistic or weakly decomposed pipelines that entangle many factors at once and demand extensive scene-level supervision, limiting their generalization to complex real-world environments. We propose a multi-agent orchestration framework that decomposes single-image 3D scene generation into three structured stages: scene initialization, environment construction, and multi-agent refinement. The initialization stage extracts image-derived object masks, builds object-level 3D representations, and predicts an initial spatial layout to form a coarse 3D scene. The environment-construction stage then leverages this initialization together with point-map geometry to build an environmental scaffold of supporting surfaces, room boundaries, materials, and illumination. Finally, in the refinement stage, a planner agent identifies structural and visual inconsistencies, applies simple corrections directly, and dispatches specialist agents for complex localized revisions that are reintegrated into the global scene. To provide reliable structural initialization while reducing reliance on scene-level annotations, we further introduce a geometry-aware layout predictor supervised by sparse geometric priors derived from point maps. Unlike fully supervised layout generators, the predictor can be trained from segmentation-level data and generalizes robustly to diverse real-world scenes. Extensive experiments on benchmark datasets show that our method consistently outperforms prior approaches in geometric accuracy, spatial consistency, and perceptual realism.
PnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
PI-Light: Physics-Inspired Diffusion for Full-Image Relighting
Jan 29, 2026Full-image relighting remains a challenging problem due to the difficulty of collecting large-scale structured paired data, the difficulty of maintaining physical plausibility, and the limited generalizability imposed by data-driven priors. Existing attempts to bridge the synthetic-to-real gap for full-scene relighting remain suboptimal. To tackle these challenges, we introduce Physics-Inspired diffusion for full-image reLight ($π$-Light, or PI-Light), a two-stage framework that leverages physics-inspired diffusion models. Our design incorporates (i) batch-aware attention, which improves the consistency of intrinsic predictions across a collection of images, (ii) a physics-guided neural rendering module that enforces physically plausible light transport, (iii) physics-inspired losses that regularize training dynamics toward a physically meaningful landscape, thereby enhancing generalizability to real-world image editing, and (iv) a carefully curated dataset of diverse objects and scenes captured under controlled lighting conditions. Together, these components enable efficient finetuning of pretrained diffusion models while also providing a solid benchmark for downstream evaluation. Experiments demonstrate that $π$-Light synthesizes specular highlights and diffuse reflections across a wide variety of materials, achieving superior generalization to real-world scenes compared with prior approaches.
FastMesh: Efficient Artistic Mesh Generation via Component Decoupling
Aug 27, 2025Recent mesh generation approaches typically tokenize triangle meshes into sequences of tokens and train autoregressive models to generate these tokens sequentially. Despite substantial progress, such token sequences inevitably reuse vertices multiple times to fully represent manifold meshes, as each vertex is shared by multiple faces. This redundancy leads to excessively long token sequences and inefficient generation processes. In this paper, we propose an efficient framework that generates artistic meshes by treating vertices and faces separately, significantly reducing redundancy. We employ an autoregressive model solely for vertex generation, decreasing the token count to approximately 23\% of that required by the most compact existing tokenizer. Next, we leverage a bidirectional transformer to complete the mesh in a single step by capturing inter-vertex relationships and constructing the adjacency matrix that defines the mesh faces. To further improve the generation quality, we introduce a fidelity enhancer to refine vertex positioning into more natural arrangements and propose a post-processing framework to remove undesirable edge connections. Experimental results show that our method achieves more than 8$\times$ faster speed on mesh generation compared to state-of-the-art approaches, while producing higher mesh quality.
SAR3D: Autoregressive 3D Object Generation and Understanding via Multi-scale 3D VQVAE
Nov 25, 2024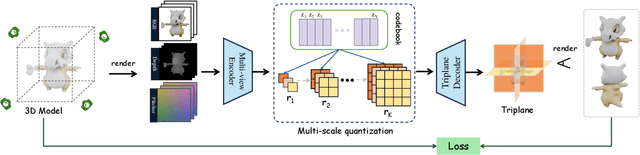
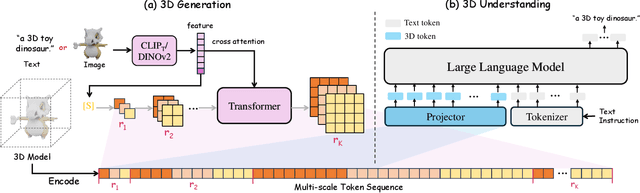
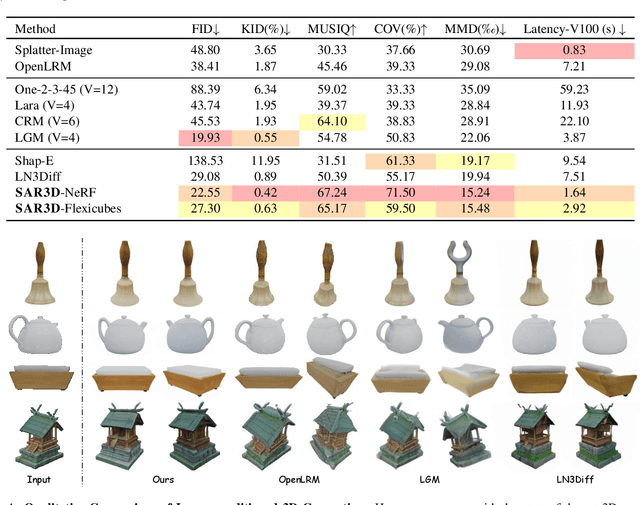

Autoregressive models have demonstrated remarkable success across various fields, from large language models (LLMs) to large multimodal models (LMMs) and 2D content generation, moving closer to artificial general intelligence (AGI). Despite these advances, applying autoregressive approaches to 3D object generation and understanding remains largely unexplored. This paper introduces Scale AutoRegressive 3D (SAR3D), a novel framework that leverages a multi-scale 3D vector-quantized variational autoencoder (VQVAE) to tokenize 3D objects for efficient autoregressive generation and detailed understanding. By predicting the next scale in a multi-scale latent representation instead of the next single token, SAR3D reduces generation time significantly, achieving fast 3D object generation in just 0.82 seconds on an A6000 GPU. Additionally, given the tokens enriched with hierarchical 3D-aware information, we finetune a pretrained LLM on them, enabling multimodal comprehension of 3D content. Our experiments show that SAR3D surpasses current 3D generation methods in both speed and quality and allows LLMs to interpret and caption 3D models comprehensively.
MvDrag3D: Drag-based Creative 3D Editing via Multi-view Generation-Reconstruction Priors
Oct 21, 2024Drag-based editing has become popular in 2D content creation, driven by the capabilities of image generative models. However, extending this technique to 3D remains a challenge. Existing 3D drag-based editing methods, whether employing explicit spatial transformations or relying on implicit latent optimization within limited-capacity 3D generative models, fall short in handling significant topology changes or generating new textures across diverse object categories. To overcome these limitations, we introduce MVDrag3D, a novel framework for more flexible and creative drag-based 3D editing that leverages multi-view generation and reconstruction priors. At the core of our approach is the usage of a multi-view diffusion model as a strong generative prior to perform consistent drag editing over multiple rendered views, which is followed by a reconstruction model that reconstructs 3D Gaussians of the edited object. While the initial 3D Gaussians may suffer from misalignment between different views, we address this via view-specific deformation networks that adjust the position of Gaussians to be well aligned. In addition, we propose a multi-view score function that distills generative priors from multiple views to further enhance the view consistency and visual quality. Extensive experiments demonstrate that MVDrag3D provides a precise, generative, and flexible solution for 3D drag-based editing, supporting more versatile editing effects across various object categories and 3D representations.
ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance
Mar 19, 2024



Generating high-quality 3D assets from a given image is highly desirable in various applications such as AR/VR. Recent advances in single-image 3D generation explore feed-forward models that learn to infer the 3D model of an object without optimization. Though promising results have been achieved in single object generation, these methods often struggle to model complex 3D assets that inherently contain multiple objects. In this work, we present ComboVerse, a 3D generation framework that produces high-quality 3D assets with complex compositions by learning to combine multiple models. 1) We first perform an in-depth analysis of this ``multi-object gap'' from both model and data perspectives. 2) Next, with reconstructed 3D models of different objects, we seek to adjust their sizes, rotation angles, and locations to create a 3D asset that matches the given image. 3) To automate this process, we apply spatially-aware score distillation sampling (SSDS) from pretrained diffusion models to guide the positioning of objects. Our proposed framework emphasizes spatial alignment of objects, compared with standard score distillation sampling, and thus achieves more accurate results. Extensive experiments validate ComboVerse achieves clear improvements over existing methods in generating compositional 3D assets.
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation
Mar 28, 2023Automatic 3D content creation has achieved rapid progress recently due to the availability of pre-trained, large language models and image diffusion models, forming the emerging topic of text-to-3D content creation. Existing text-to-3D methods commonly use implicit scene representations, which couple the geometry and appearance via volume rendering and are suboptimal in terms of recovering finer geometries and achieving photorealistic rendering; consequently, they are less effective for generating high-quality 3D assets. In this work, we propose a new method of Fantasia3D for high-quality text-to-3D content creation. Key to Fantasia3D is the disentangled modeling and learning of geometry and appearance. For geometry learning, we rely on a hybrid scene representation, and propose to encode surface normal extracted from the representation as the input of the image diffusion model. For appearance modeling, we introduce the spatially varying bidirectional reflectance distribution function (BRDF) into the text-to-3D task, and learn the surface material for photorealistic rendering of the generated surface. Our disentangled framework is more compatible with popular graphics engines, supporting relighting, editing, and physical simulation of the generated 3D assets. We conduct thorough experiments that show the advantages of our method over existing ones under different text-to-3D task settings. Project page and source codes: https://fantasia3d.github.io/.
TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition
Oct 20, 2022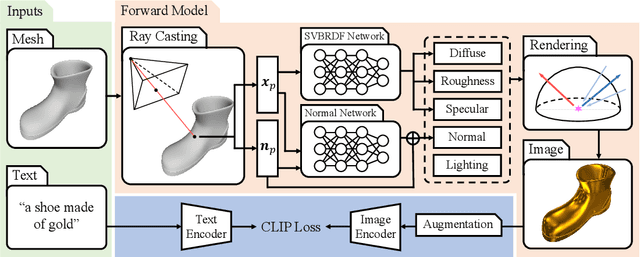



Creation of 3D content by stylization is a promising yet challenging problem in computer vision and graphics research. In this work, we focus on stylizing photorealistic appearance renderings of a given surface mesh of arbitrary topology. Motivated by the recent surge of cross-modal supervision of the Contrastive Language-Image Pre-training (CLIP) model, we propose TANGO, which transfers the appearance style of a given 3D shape according to a text prompt in a photorealistic manner. Technically, we propose to disentangle the appearance style as the spatially varying bidirectional reflectance distribution function, the local geometric variation, and the lighting condition, which are jointly optimized, via supervision of the CLIP loss, by a spherical Gaussians based differentiable renderer. As such, TANGO enables photorealistic 3D style transfer by automatically predicting reflectance effects even for bare, low-quality meshes, without training on a task-specific dataset. Extensive experiments show that TANGO outperforms existing methods of text-driven 3D style transfer in terms of photorealistic quality, consistency of 3D geometry, and robustness when stylizing low-quality meshes. Our codes and results are available at our project webpage https://cyw-3d.github.io/tango/.
Coarse Retinal Lesion Annotations Refinement via Prototypical Learning
Aug 30, 2022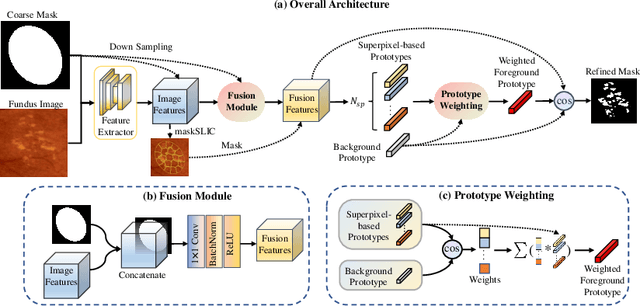
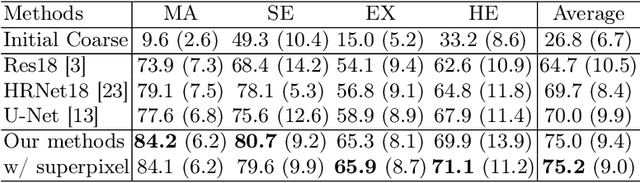

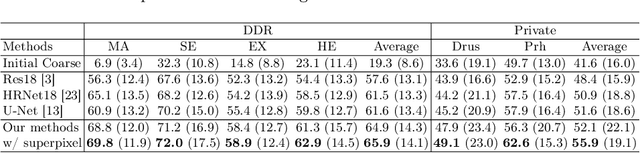
Deep-learning-based approaches for retinal lesion segmentation often require an abundant amount of precise pixel-wise annotated data. However, coarse annotations such as circles or ellipses for outlining the lesion area can be six times more efficient than pixel-level annotation. Therefore, this paper proposes an annotation refinement network to convert a coarse annotation into a pixel-level segmentation mask. Our main novelty is the application of the prototype learning paradigm to enhance the generalization ability across different datasets or types of lesions. We also introduce a prototype weighing module to handle challenging cases where the lesion is overly small. The proposed method was trained on the publicly available IDRiD dataset and then generalized to the public DDR and our real-world private datasets. Experiments show that our approach substantially improved the initial coarse mask and outperformed the non-prototypical baseline by a large margin. Moreover, we demonstrate the usefulness of the prototype weighing module in both cross-dataset and cross-class settings.