 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Safety-Aware Decoding
Aug 25, 2025Despite extensive efforts to align Large Language Models (LLMs) with human values and safety rules, jailbreak attacks that exploit certain vulnerabilities continuously emerge, highlighting the need to strengthen existing LLMs with additional safety properties to defend against these attacks. However, tuning large models has become increasingly resource-intensive and may have difficulty ensuring consistent performance. We introduce Speculative Safety-Aware Decoding (SSD), a lightweight decoding-time approach that equips LLMs with the desired safety property while accelerating inference. We assume that there exists a small language model that possesses this desired property. SSD integrates speculative sampling during decoding and leverages the match ratio between the small and composite models to quantify jailbreak risks. This enables SSD to dynamically switch between decoding schemes to prioritize utility or safety, to handle the challenge of different model capacities. The output token is then sampled from a new distribution that combines the distributions of the original and the small models. Experimental results show that SSD successfully equips the large model with the desired safety property, and also allows the model to remain helpful to benign queries. Furthermore, SSD accelerates the inference time, thanks to the speculative sampling design.
A Simple DropConnect Approach to Transfer-based Targeted Attack
Apr 24, 2025We study the problem of transfer-based black-box attack, where adversarial samples generated using a single surrogate model are directly applied to target models. Compared with untargeted attacks, existing methods still have lower Attack Success Rates (ASRs) in the targeted setting, i.e., the obtained adversarial examples often overfit the surrogate model but fail to mislead other models. In this paper, we hypothesize that the pixels or features in these adversarial examples collaborate in a highly dependent manner to maximize the success of an adversarial attack on the surrogate model, which we refer to as perturbation co-adaptation. Then, we propose to Mitigate perturbation Co-adaptation by DropConnect (MCD) to enhance transferability, by creating diverse variants of surrogate model at each optimization iteration. We conduct extensive experiments across various CNN- and Transformer-based models to demonstrate the effectiveness of MCD. In the challenging scenario of transferring from a CNN-based model to Transformer-based models, MCD achieves 13% higher average ASRs compared with state-of-the-art baselines. MCD boosts the performance of self-ensemble methods by bringing in more diversification across the variants while reserving sufficient semantic information for each variant. In addition, MCD attains the highest performance gain when scaling the compute of crafting adversarial examples.
Causal Discovery by Kernel Deviance Measures with Heterogeneous Transforms
Jan 31, 2024The discovery of causal relationships in a set of random variables is a fundamental objective of science and has also recently been argued as being an essential component towards real machine intelligence. One class of causal discovery techniques are founded based on the argument that there are inherent structural asymmetries between the causal and anti-causal direction which could be leveraged in determining the direction of causation. To go about capturing these discrepancies between cause and effect remains to be a challenge and many current state-of-the-art algorithms propose to compare the norms of the kernel mean embeddings of the conditional distributions. In this work, we argue that such approaches based on RKHS embeddings are insufficient in capturing principal markers of cause-effect asymmetry involving higher-order structural variabilities of the conditional distributions. We propose Kernel Intrinsic Invariance Measure with Heterogeneous Transform (KIIM-HT) which introduces a novel score measure based on heterogeneous transformation of RKHS embeddings to extract relevant higher-order moments of the conditional densities for causal discovery. Inference is made via comparing the score of each hypothetical cause-effect direction. Tests and comparisons on a synthetic dataset, a two-dimensional synthetic dataset and the real-world benchmark dataset T\"ubingen Cause-Effect Pairs verify our approach. In addition, we conduct a sensitivity analysis to the regularization parameter to faithfully compare previous work to our method and an experiment with trials on varied hyperparameter values to showcase the robustness of our algorithm.
RIS-Assisted Joint Uplink Communication and Imaging: Phase Optimization and Bayesian Echo Decoupling
Jan 10, 2023Achieving integrated sensing and communication (ISAC) via uplink transmission is challenging due to the unknown waveform and the coupling of communication and sensing echoes. In this paper, a joint uplink communication and imaging system is proposed for the first time, where a reconfigurable intelligent surface (RIS) is used to manipulate the electromagnetic signals for echo decoupling at the base station (BS). Aiming to enhance the transmission gain in desired directions and generate required radiation pattern in the region of interest (RoI), a phase optimization problem for RIS is formulated, which is high dimensional and nonconvex with discrete constraints. To tackle this problem, a back propagation based phase design scheme for both continuous and discrete phase models is developed. Moreover, the echo decoupling problem is tackled using the Bayesian method with the factor graph technique, where the problem is represented by a graph model which consists of difficult local functions. Based on the graph model, a message-passing algorithm is derived, which can efficiently cooperate with the adaptive sparse Bayesian learning (SBL) to achieve joint communication and imaging. Numerical results show that the proposed method approaches the relevant lower bound asymptotically, and the communication performance can be enhanced with the utilization of imaging echoes.
GFlowCausal: Generative Flow Networks for Causal Discovery
Oct 15, 2022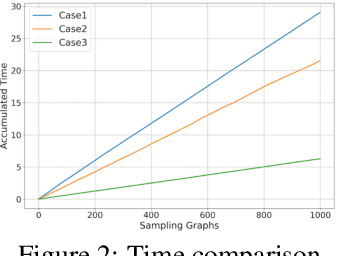

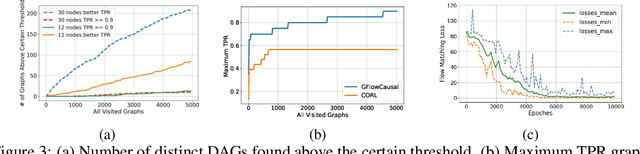

Causal discovery aims to uncover causal structure among a set of variables. Score-based approaches mainly focus on searching for the best Directed Acyclic Graph (DAG) based on a predefined score function. However, most of them are not applicable on a large scale due to the limited searchability. Inspired by the active learning in generative flow networks, we propose a novel approach to learning a DAG from observational data called GFlowCausal. It converts the graph search problem to a generation problem, in which direct edges are added gradually. GFlowCausal aims to learn the best policy to generate high-reward DAGs by sequential actions with probabilities proportional to predefined rewards. We propose a plug-and-play module based on transitive closure to ensure efficient sampling. Theoretical analysis shows that this module could guarantee acyclicity properties effectively and the consistency between final states and fully-connected graphs. We conduct extensive experiments on both synthetic and real datasets, and results show the proposed approach to be superior and also performs well in a large-scale setting.
Reframed GES with a Neural Conditional Dependence Measure
Jun 17, 2022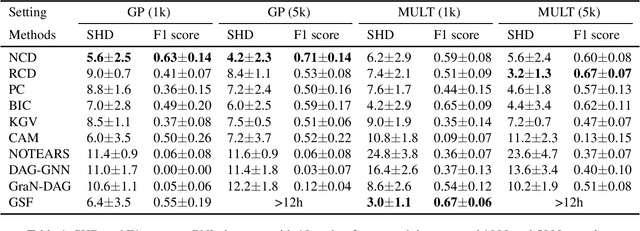
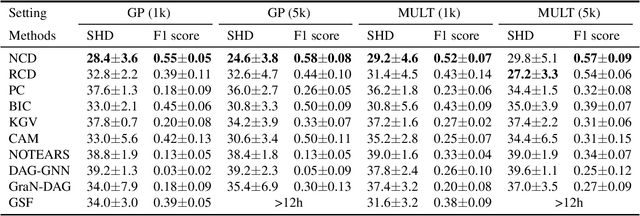
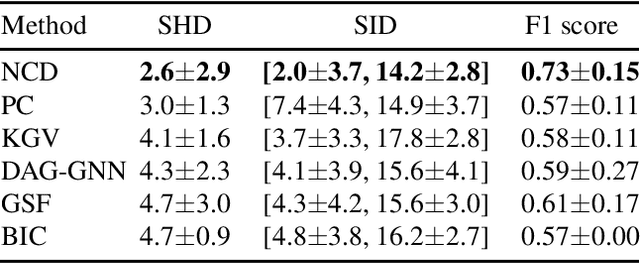
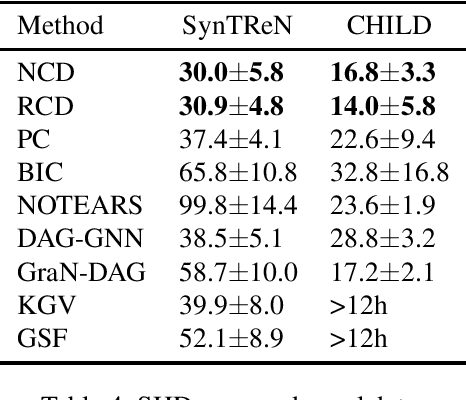
In a nonparametric setting, the causal structure is often identifiable only up to Markov equivalence, and for the purpose of causal inference, it is useful to learn a graphical representation of the Markov equivalence class (MEC). In this paper, we revisit the Greedy Equivalence Search (GES) algorithm, which is widely cited as a score-based algorithm for learning the MEC of the underlying causal structure. We observe that in order to make the GES algorithm consistent in a nonparametric setting, it is not necessary to design a scoring metric that evaluates graphs. Instead, it suffices to plug in a consistent estimator of a measure of conditional dependence to guide the search. We therefore present a reframing of the GES algorithm, which is more flexible than the standard score-based version and readily lends itself to the nonparametric setting with a general measure of conditional dependence. In addition, we propose a neural conditional dependence (NCD) measure, which utilizes the expressive power of deep neural networks to characterize conditional independence in a nonparametric manner. We establish the optimality of the reframed GES algorithm under standard assumptions and the consistency of using our NCD estimator to decide conditional independence. Together these results justify the proposed approach. Experimental results demonstrate the effectiveness of our method in causal discovery, as well as the advantages of using our NCD measure over kernel-based measures.
Out-of-distribution Generalization with Causal Invariant Transformations
Mar 24, 2022
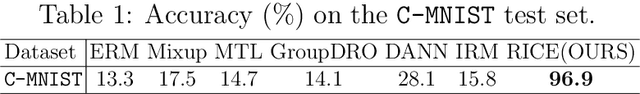
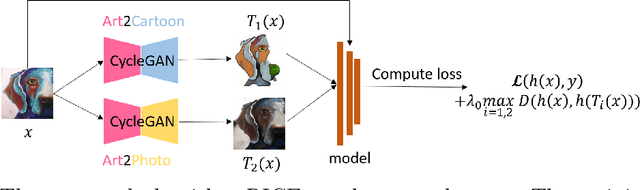
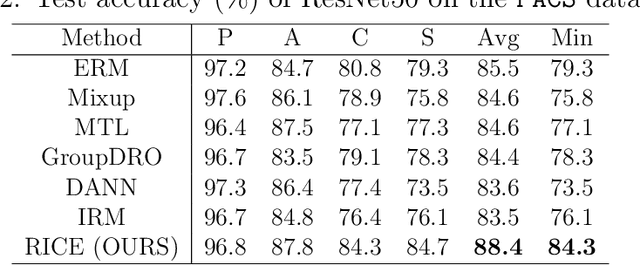
In real-world applications, it is important and desirable to learn a model that performs well on out-of-distribution (OOD) data. Recently, causality has become a powerful tool to tackle the OOD generalization problem, with the idea resting on the causal mechanism that is invariant across domains of interest. To leverage the generally unknown causal mechanism, existing works assume a linear form of causal feature or require sufficiently many and diverse training domains, which are usually restrictive in practice. In this work, we obviate these assumptions and tackle the OOD problem without explicitly recovering the causal feature. Our approach is based on transformations that modify the non-causal feature but leave the causal part unchanged, which can be either obtained from prior knowledge or learned from the training data in the multi-domain scenario. Under the setting of invariant causal mechanism, we theoretically show that if all such transformations are available, then we can learn a minimax optimal model across the domains using only single domain data. Noticing that knowing a complete set of these causal invariant transformations may be impractical, we further show that it suffices to know only a subset of these transformations. Based on the theoretical findings, a regularized training procedure is proposed to improve the OOD generalization capability. Extensive experimental results on both synthetic and real datasets verify the effectiveness of the proposed algorithm, even with only a few causal invariant transformations.
ZIN: When and How to Learn Invariance by Environment Inference?
Mar 11, 2022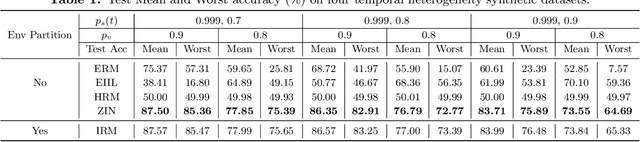
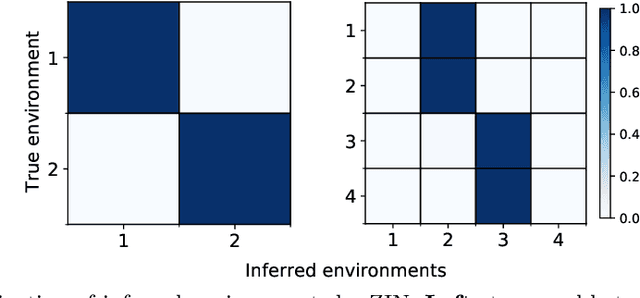
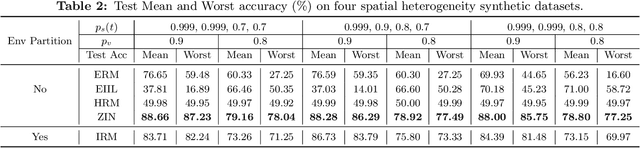
It is commonplace to encounter heterogeneous data, of which some aspects of the data distribution may vary but the underlying causal mechanisms remain constant. When data are divided into distinct environments according to the heterogeneity, recent invariant learning methods have proposed to learn robust and invariant models based on this environment partition. It is hence tempting to utilize the inherent heterogeneity even when environment partition is not provided. Unfortunately, in this work, we show that learning invariant features under this circumstance is fundamentally impossible without further inductive biases or additional information. Then, we propose a framework to jointly learn environment partition and invariant representation, assisted by additional auxiliary information. We derive sufficient and necessary conditions for our framework to provably identify invariant features under a fairly general setting. Experimental results on both synthetic and real world datasets validate our analysis and demonstrate an improved performance of the proposed framework over existing methods. Finally, our results also raise the need of making the role of inductive biases more explicit in future works, when considering learning invariant models without environment partition.
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
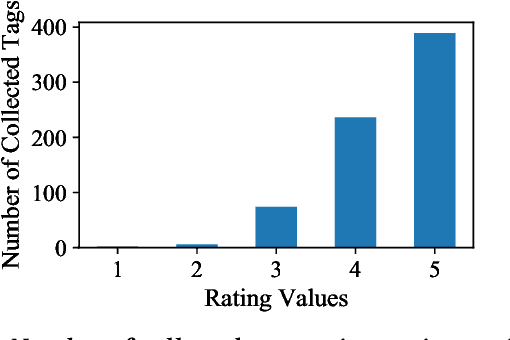
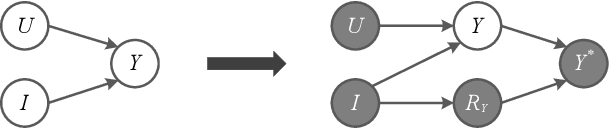
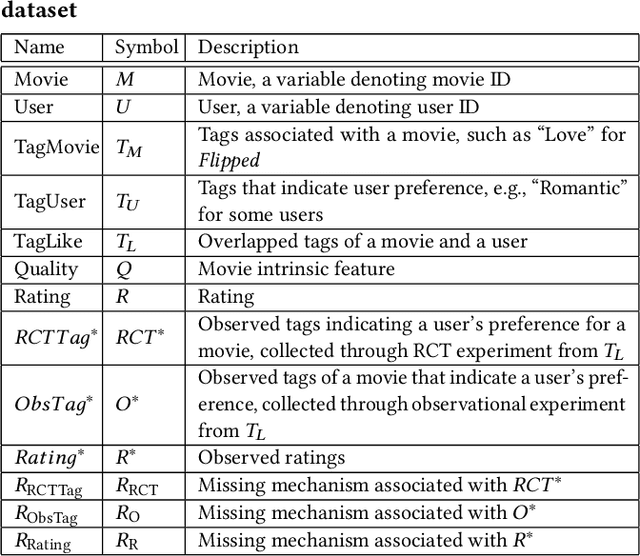
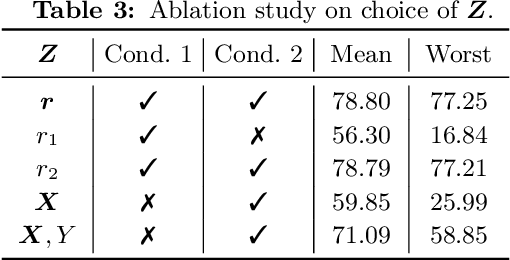
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.
Universality of parametric Coupling Flows over parametric diffeomorphisms
Feb 08, 2022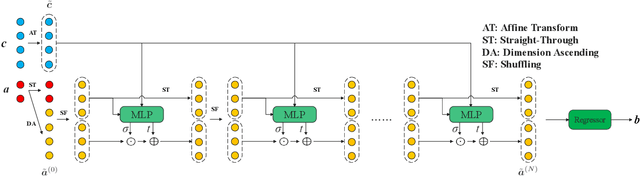

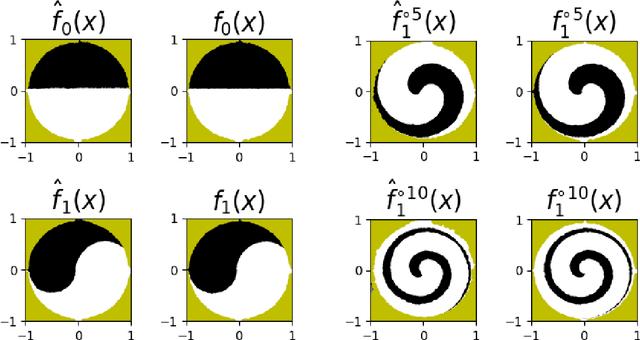

Invertible neural networks based on Coupling Flows CFlows) have various applications such as image synthesis and data compression. The approximation universality for CFlows is of paramount importance to ensure the model expressiveness. In this paper, we prove that CFlows can approximate any diffeomorphism in C^k-norm if its layers can approximate certain single-coordinate transforms. Specifically, we derive that a composition of affine coupling layers and invertible linear transforms achieves this universality. Furthermore, in parametric cases where the diffeomorphism depends on some extra parameters, we prove the corresponding approximation theorems for our proposed parametric coupling flows named Para-CFlows. In practice, we apply Para-CFlows as a neural surrogate model in contextual Bayesian optimization tasks, to demonstrate its superiority over other neural surrogate models in terms of optimization performance.