 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-to-More: High-Fidelity Training-Free Anomaly Generation with Attention Control
Mar 18, 2026Industrial anomaly detection (AD) is characterized by an abundance of normal images but a scarcity of anomalous ones. Although numerous few-shot anomaly synthesis methods have been proposed to augment anomalous data for downstream AD tasks, most existing approaches require time-consuming training and struggle to learn distributions that are faithful to real anomalies, thereby restricting the efficacy of AD models trained on such data. To address these limitations, we propose a training-free few-shot anomaly generation method, namely O2MAG, which leverages the self-attention in One reference anomalous image to synthesize More realistic anomalies, supporting effective downstream anomaly detection. Specifically, O2MAG manipulates three parallel diffusion processes via self-attention grafting and incorporates the anomaly mask to mitigate foreground-background query confusion, synthesizing text-guided anomalies that closely adhere to real anomalous distributions. To bridge the semantic gap between the encoded anomaly text prompts and the true anomaly semantics, Anomaly-Guided Optimization is further introduced to align the synthesis process with the target anomalous distribution, steering the generation toward realistic and text-consistent anomalies. Moreover, to mitigate faint anomaly synthesis inside anomaly masks, Dual-Attention Enhancement is adopted during generation to reinforce both self- and cross-attention on masked regions. Extensive experiments validate the effectiveness of O2MAG, demonstrating its superior performance over prior state-of-the-art methods on downstream AD tasks.
Refine and Purify: Orthogonal Basis Optimization with Null-Space Denoising for Conditional Representation Learning
Feb 05, 2026Conditional representation learning aims to extract criterion-specific features for customized tasks. Recent studies project universal features onto the conditional feature subspace spanned by an LLM-generated text basis to obtain conditional representations. However, such methods face two key limitations: sensitivity to subspace basis and vulnerability to inter-subspace interference. To address these challenges, we propose OD-CRL, a novel framework integrating Adaptive Orthogonal Basis Optimization (AOBO) and Null-Space Denoising Projection (NSDP). Specifically, AOBO constructs orthogonal semantic bases via singular value decomposition with a curvature-based truncation. NSDP suppresses non-target semantic interference by projecting embeddings onto the null space of irrelevant subspaces. Extensive experiments conducted across customized clustering, customized classification, and customized retrieval tasks demonstrate that OD-CRL achieves a new state-of-the-art performance with superior generalization.
UGOD: Uncertainty-Guided Differentiable Opacity and Soft Dropout for Enhanced Sparse-View 3DGS
Aug 07, 20253D Gaussian Splatting (3DGS) has become a competitive approach for novel view synthesis (NVS) due to its advanced rendering efficiency through 3D Gaussian projection and blending. However, Gaussians are treated equally weighted for rendering in most 3DGS methods, making them prone to overfitting, which is particularly the case in sparse-view scenarios. To address this, we investigate how adaptive weighting of Gaussians affects rendering quality, which is characterised by learned uncertainties proposed. This learned uncertainty serves two key purposes: first, it guides the differentiable update of Gaussian opacity while preserving the 3DGS pipeline integrity; second, the uncertainty undergoes soft differentiable dropout regularisation, which strategically transforms the original uncertainty into continuous drop probabilities that govern the final Gaussian projection and blending process for rendering. Extensive experimental results over widely adopted datasets demonstrate that our method outperforms rivals in sparse-view 3D synthesis, achieving higher quality reconstruction with fewer Gaussians in most datasets compared to existing sparse-view approaches, e.g., compared to DropGaussian, our method achieves 3.27\% PSNR improvements on the MipNeRF 360 dataset.
Personalized Federated Learning via Learning Dynamic Graphs
Mar 07, 2025Personalized Federated Learning (PFL) aims to train a personalized model for each client that is tailored to its local data distribution, learning fails to perform well on individual clients due to variations in their local data distributions. Most existing PFL methods focus on personalizing the aggregated global model for each client, neglecting the fundamental aspect of federated learning: the regulation of how client models are aggregated. Additionally, almost all of them overlook the graph structure formed by clients in federated learning. In this paper, we propose a novel method, Personalized Federated Learning with Graph Attention Network (pFedGAT), which captures the latent graph structure between clients and dynamically determines the importance of other clients for each client, enabling fine-grained control over the aggregation process. We evaluate pFedGAT across multiple data distribution scenarios, comparing it with twelve state of the art methods on three datasets: Fashion MNIST, CIFAR-10, and CIFAR-100, and find that it consistently performs well.
i-Rebalance: Personalized Vehicle Repositioning for Supply Demand Balance
Jan 09, 2024



Ride-hailing platforms have been facing the challenge of balancing demand and supply. Existing vehicle reposition techniques often treat drivers as homogeneous agents and relocate them deterministically, assuming compliance with the reposition. In this paper, we consider a more realistic and driver-centric scenario where drivers have unique cruising preferences and can decide whether to take the recommendation or not on their own. We propose i-Rebalance, a personalized vehicle reposition technique with deep reinforcement learning (DRL). i-Rebalance estimates drivers' decisions on accepting reposition recommendations through an on-field user study involving 99 real drivers. To optimize supply-demand balance and enhance preference satisfaction simultaneously, i-Rebalance has a sequential reposition strategy with dual DRL agents: Grid Agent to determine the reposition order of idle vehicles, and Vehicle Agent to provide personalized recommendations to each vehicle in the pre-defined order. This sequential learning strategy facilitates more effective policy training within a smaller action space compared to traditional joint-action methods. Evaluation of real-world trajectory data shows that i-Rebalance improves driver acceptance rate by 38.07% and total driver income by 9.97%.
Doubly Robust Collaborative Targeted Learning for Recommendation on Data Missing Not at Random
Mar 19, 2022
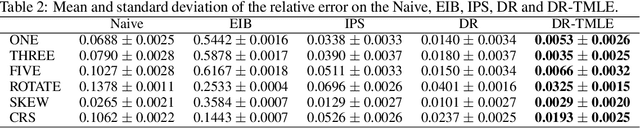
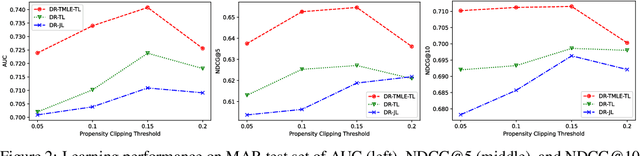

In recommender systems, the feedback data received is always missing not at random (MNAR), which poses challenges for accurate rating prediction. To address this issue, many recent studies have been conducted on the doubly robust (DR) method and its variants to reduce bias. However, theoretical analysis shows that the DR method has a relatively large variance, while that of the error imputation-based (EIB) method is smaller. In this paper, we propose {\bf DR-TMLE} that effectively captures the merits of both EIB and DR, by leveraging the targeted maximum likelihood estimation (TMLE) technique. DR-TMLE first obtains an initial EIB estimator and then updates the error imputation model along with the bias-reduced direction. Furthermore, we propose a novel RCT-free collaborative targeted learning algorithm for DR-TMLE, called {\bf DR-TMLE-TL}, which updates the propensity model adaptively to reduce the bias of imputed errors. Both theoretical analysis and experiments demonstrate the advantages of the proposed methods compared with existing debiasing methods.
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
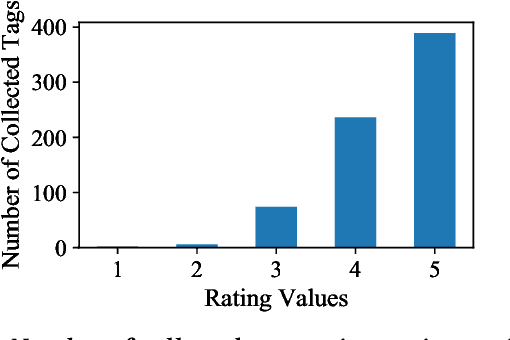
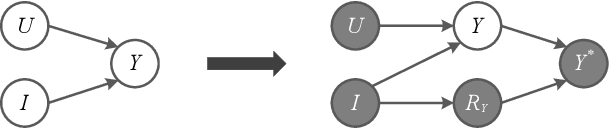
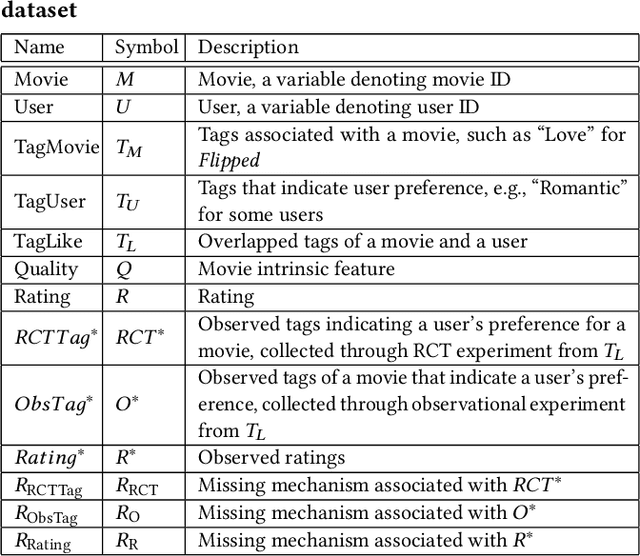
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.