 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Recommendation with Noisy Feedback
Jun 24, 2024Ratings of a user to most items in recommender systems are usually missing not at random (MNAR), largely because users are free to choose which items to rate. To achieve unbiased learning of the prediction model under MNAR data, three typical solutions have been proposed, including error-imputation-based (EIB), inverse-propensity-scoring (IPS), and doubly robust (DR) methods. However, these methods ignore an alternative form of bias caused by the inconsistency between the observed ratings and the users' true preferences, also known as noisy feedback or outcome measurement errors (OME), e.g., due to public opinion or low-quality data collection process. In this work, we study intersectional threats to the unbiased learning of the prediction model from data MNAR and OME in the collected data. First, we design OME-EIB, OME-IPS, and OME-DR estimators, which largely extend the existing estimators to combat OME in real-world recommendation scenarios. Next, we theoretically prove the unbiasedness and generalization bound of the proposed estimators. We further propose an alternate denoising training approach to achieve unbiased learning of the prediction model under MNAR data with OME. Extensive experiments are conducted on three real-world datasets and one semi-synthetic dataset to show the effectiveness of our proposed approaches. The code is available at https://github.com/haoxuanli-pku/KDD24-OME-DR.
Phased Instruction Fine-Tuning for Large Language Models
Jun 01, 2024



Instruction Fine-Tuning, a method enhancing pre-trained language models' capabilities from mere next-word prediction to complex instruction following, often employs a one-off training approach on diverse instruction dataset. However, this method may not effectively enhance models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To address this, we propose a novel phased instruction fine-tuning (Phased IFT) method, grounded in the hypothesis of progressive alignment, which posits that the transition of a pre-trained language model from simple next-word prediction to sophisticated instruction following is a gradual learning process. Specifically, we obtain the score of difficulty for each instruction via GPT-4, stratify the instruction data into subsets of increasing difficulty, and sequentially uptrain on these subsets using the standard supervised loss. Through extensive experiments on the pre-trained models Llama-2 7B/13B, and Mistral-7B using the 52K Alpaca instruction data, we demonstrate that Phased IFT significantly surpasses traditional one-off instruction fine-tuning (One-off IFT) method in win rate, empirically validating the progressive alignment hypothesis. Our findings suggest that Phased IFT offers a simple yet effective pathway for elevating the instruction-following capabilities of pre-trained language models. Models and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Apr 14, 2024Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
ADRNet: A Generalized Collaborative Filtering Framework Combining Clinical and Non-Clinical Data for Adverse Drug Reaction Prediction
Aug 03, 2023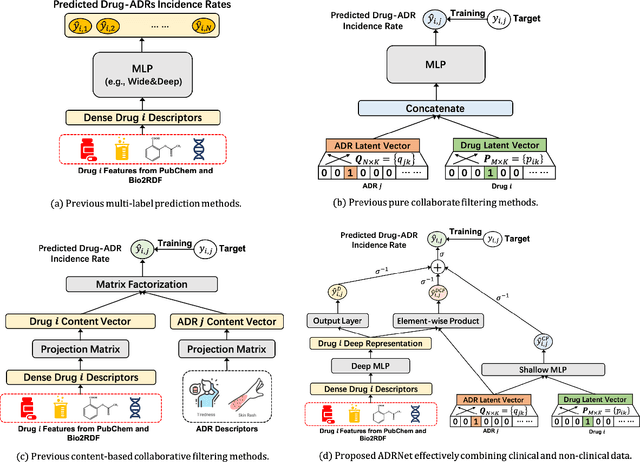
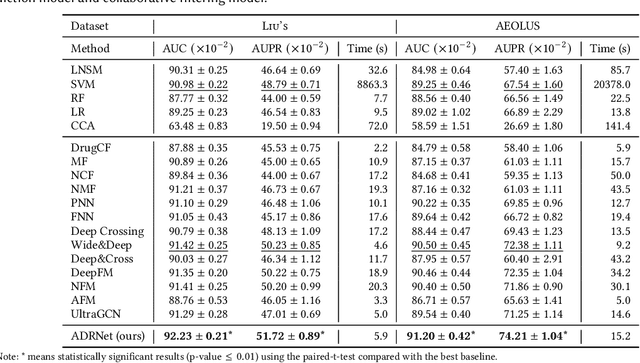
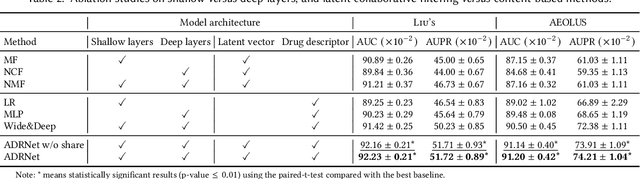

Adverse drug reaction (ADR) prediction plays a crucial role in both health care and drug discovery for reducing patient mortality and enhancing drug safety. Recently, many studies have been devoted to effectively predict the drug-ADRs incidence rates. However, these methods either did not effectively utilize non-clinical data, i.e., physical, chemical, and biological information about the drug, or did little to establish a link between content-based and pure collaborative filtering during the training phase. In this paper, we first formulate the prediction of multi-label ADRs as a drug-ADR collaborative filtering problem, and to the best of our knowledge, this is the first work to provide extensive benchmark results of previous collaborative filtering methods on two large publicly available clinical datasets. Then, by exploiting the easy accessible drug characteristics from non-clinical data, we propose ADRNet, a generalized collaborative filtering framework combining clinical and non-clinical data for drug-ADR prediction. Specifically, ADRNet has a shallow collaborative filtering module and a deep drug representation module, which can exploit the high-dimensional drug descriptors to further guide the learning of low-dimensional ADR latent embeddings, which incorporates both the benefits of collaborative filtering and representation learning. Extensive experiments are conducted on two publicly available real-world drug-ADR clinical datasets and two non-clinical datasets to demonstrate the accuracy and efficiency of the proposed ADRNet. The code is available at https://github.com/haoxuanli-pku/ADRnet.
A Generalized Doubly Robust Learning Framework for Debiasing Post-Click Conversion Rate Prediction
Nov 12, 2022



Post-click conversion rate (CVR) prediction is an essential task for discovering user interests and increasing platform revenues in a range of industrial applications. One of the most challenging problems of this task is the existence of severe selection bias caused by the inherent self-selection behavior of users and the item selection process of systems. Currently, doubly robust (DR) learning approaches achieve the state-of-the-art performance for debiasing CVR prediction. However, in this paper, by theoretically analyzing the bias, variance and generalization bounds of DR methods, we find that existing DR approaches may have poor generalization caused by inaccurate estimation of propensity scores and imputation errors, which often occur in practice. Motivated by such analysis, we propose a generalized learning framework that not only unifies existing DR methods, but also provides a valuable opportunity to develop a series of new debiasing techniques to accommodate different application scenarios. Based on the framework, we propose two new DR methods, namely DR-BIAS and DR-MSE. DR-BIAS directly controls the bias of DR loss, while DR-MSE balances the bias and variance flexibly, which achieves better generalization performance. In addition, we propose a novel tri-level joint learning optimization method for DR-MSE in CVR prediction, and an efficient training algorithm correspondingly. We conduct extensive experiments on both real-world and semi-synthetic datasets, which validate the effectiveness of our proposed methods.
Stabilized Doubly Robust Learning for Recommendation on Data Missing Not at Random
May 17, 2022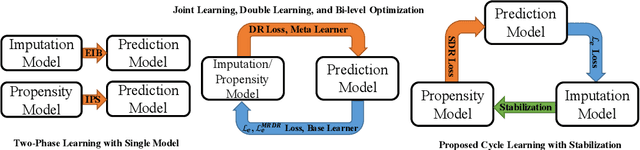

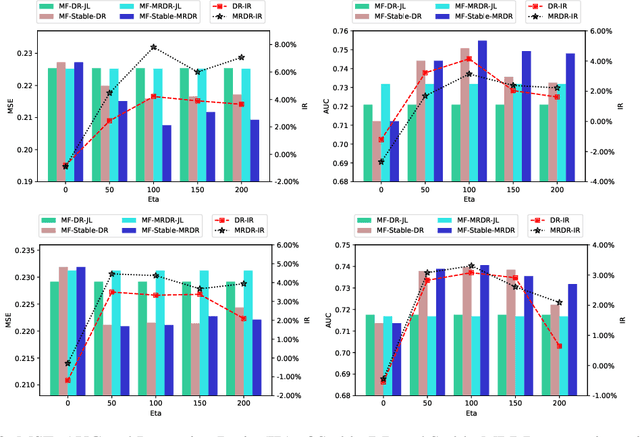
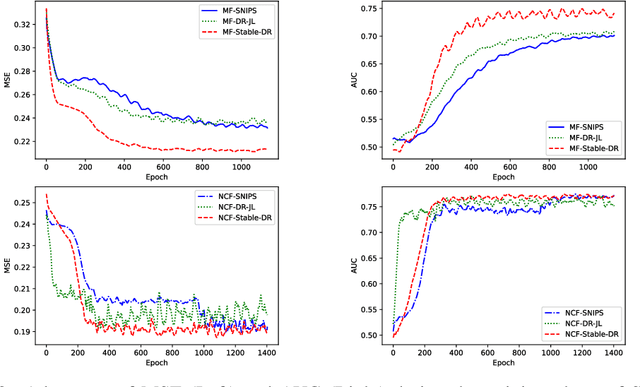
In recommender systems, users always choose the favorite items to rate, which leads to data missing not at random and poses a great challenge for unbiased evaluation and learning of prediction models. Currently, the doubly robust (DR) method and its variants have been widely studied and demonstrate superior performance. However, in this paper, we show that DR methods are unstable and have unbounded bias, variance, and generalization bounds to extremely small propensities. Moreover, the fact that DR relies more on extrapolation will lead to suboptimal performance. To address the above limitations while retaining double robustness, we propose a stabilized doubly robust (SDR) estimator with a weaker reliance on extrapolation. Theoretical analysis shows that SDR has bounded bias, variance, and generalization error bound simultaneously under inaccurate imputed errors and arbitrarily small propensities. In addition, we propose a novel learning approach for SDR that updates the imputation, propensity, and prediction models cyclically, achieving more stable and accurate predictions. Extensive experiments show that our approaches significantly outperform the existing methods.
Doubly Robust Collaborative Targeted Learning for Recommendation on Data Missing Not at Random
Mar 19, 2022
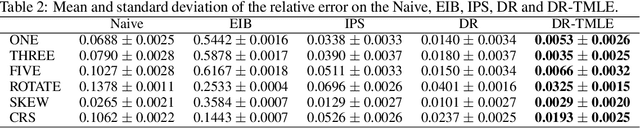
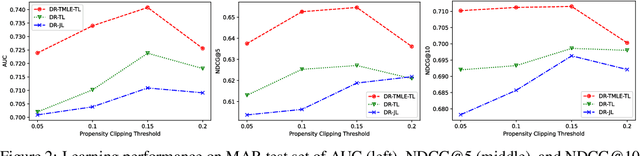

In recommender systems, the feedback data received is always missing not at random (MNAR), which poses challenges for accurate rating prediction. To address this issue, many recent studies have been conducted on the doubly robust (DR) method and its variants to reduce bias. However, theoretical analysis shows that the DR method has a relatively large variance, while that of the error imputation-based (EIB) method is smaller. In this paper, we propose {\bf DR-TMLE} that effectively captures the merits of both EIB and DR, by leveraging the targeted maximum likelihood estimation (TMLE) technique. DR-TMLE first obtains an initial EIB estimator and then updates the error imputation model along with the bias-reduced direction. Furthermore, we propose a novel RCT-free collaborative targeted learning algorithm for DR-TMLE, called {\bf DR-TMLE-TL}, which updates the propensity model adaptively to reduce the bias of imputed errors. Both theoretical analysis and experiments demonstrate the advantages of the proposed methods compared with existing debiasing methods.
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
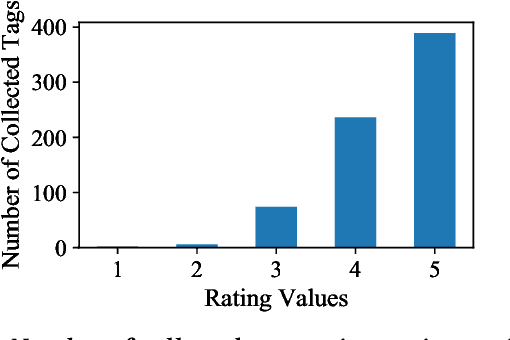
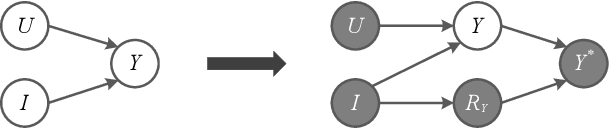
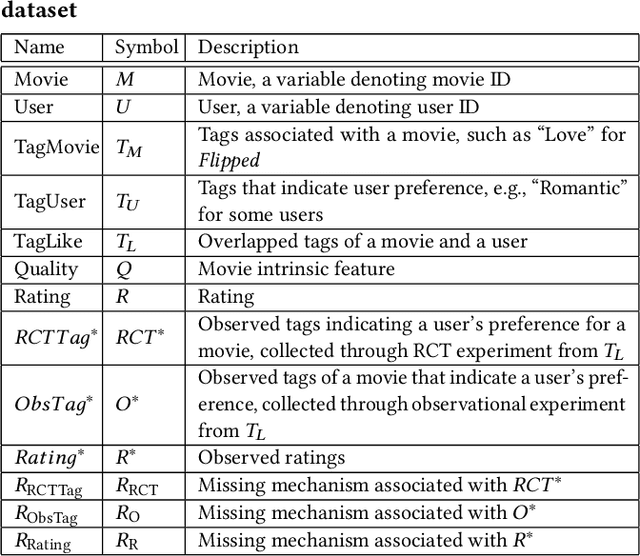
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.
Causal Analysis Framework for Recommendation
Jan 18, 2022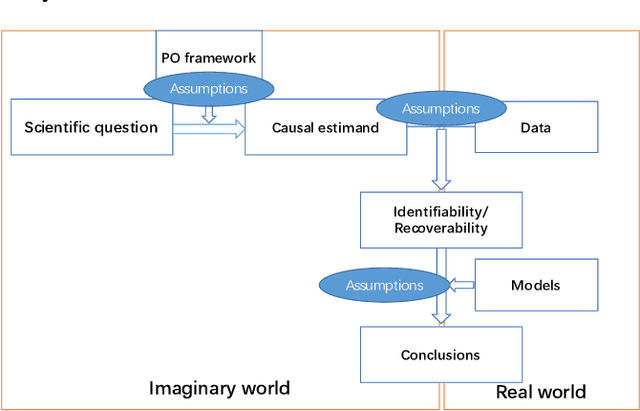
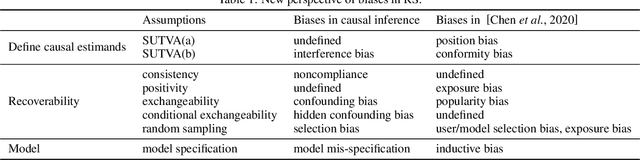
Recently, recommendation based on causal inference has gained much attention in the industrial community. The introduction of causal techniques into recommender systems (RS) has brought great development to this field and has gradually become a trend. However, a unified causal analysis framework has not been established yet. On one hand, the existing causal methods in RS lack a clear causal and mathematical formalization on the scientific questions of interest. Many confusions need to be clarified: what exactly is being estimated, for what purpose, in which scenario, by which technique, and under what plausible assumptions. On the other hand, technically speaking, the existence of various biases is the main obstacle to drawing causal conclusions from observed data. Yet, formal definitions of the biases in RS are still not clear. Both of the limitations greatly hinder the development of RS. In this paper, we attempt to give a causal analysis framework to accommodate different scenarios in RS, thereby providing a principled and rigorous operational guideline for causal recommendation. We first propose a step-by-step guideline on how to clarify and investigate problems in RS using causal concepts. Then, we provide a new taxonomy and give a formal definition of various biases in RS from the perspective of violating what assumptions are adopted in standard causal analysis. Finally, we find that many problems in RS can be well formalized into a few scenarios using the proposed causal analysis framework.
Prevent the Language Model from being Overconfident in Neural Machine Translation
May 31, 2021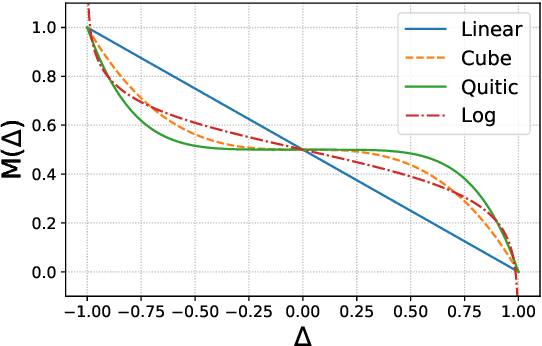
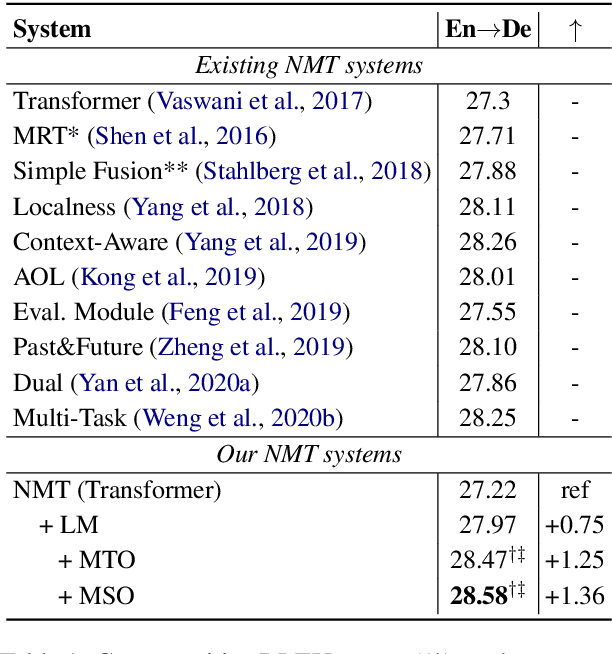

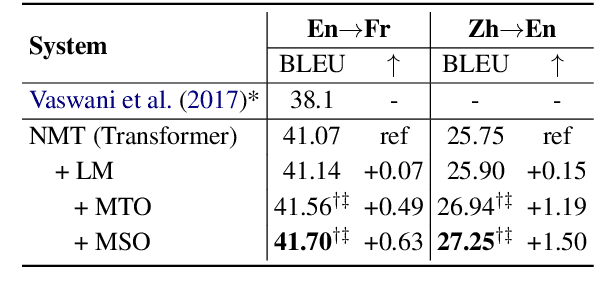
The Neural Machine Translation (NMT) model is essentially a joint language model conditioned on both the source sentence and partial translation. Therefore, the NMT model naturally involves the mechanism of the Language Model (LM) that predicts the next token only based on partial translation. Despite its success, NMT still suffers from the hallucination problem, generating fluent but inadequate translations. The main reason is that NMT pays excessive attention to the partial translation while neglecting the source sentence to some extent, namely overconfidence of the LM. Accordingly, we define the Margin between the NMT and the LM, calculated by subtracting the predicted probability of the LM from that of the NMT model for each token. The Margin is negatively correlated to the overconfidence degree of the LM. Based on the property, we propose a Margin-based Token-level Objective (MTO) and a Margin-based Sentencelevel Objective (MSO) to maximize the Margin for preventing the LM from being overconfident. Experiments on WMT14 English-to-German, WMT19 Chinese-to-English, and WMT14 English-to-French translation tasks demonstrate the effectiveness of our approach, with 1.36, 1.50, and 0.63 BLEU improvements, respectively, compared to the Transformer baseline. The human evaluation further verifies that our approaches improve translation adequacy as well as fluency.