 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrevent the Language Model from being Overconfident in Neural Machine Translation
Paper and Code
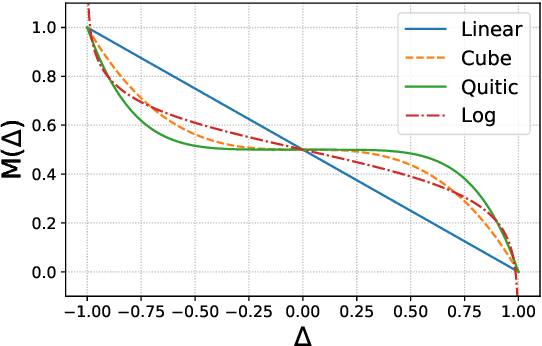
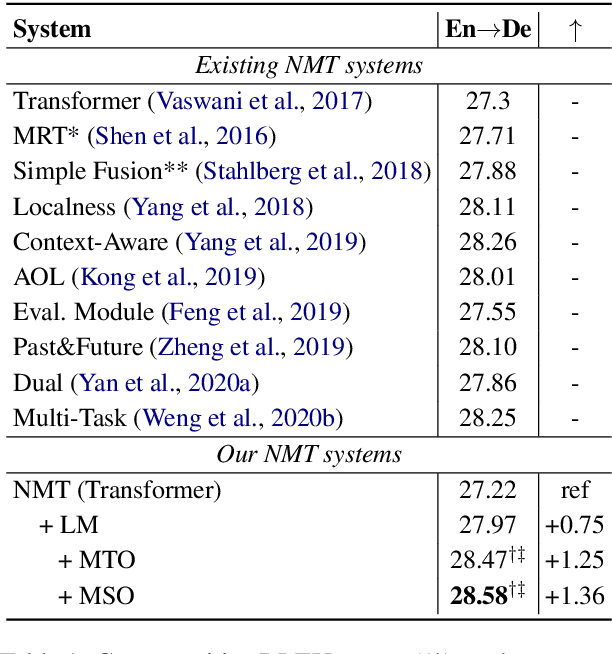

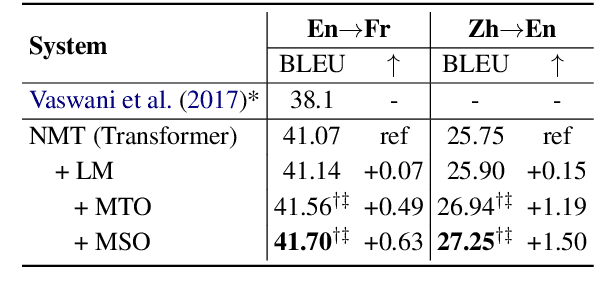
The Neural Machine Translation (NMT) model is essentially a joint language model conditioned on both the source sentence and partial translation. Therefore, the NMT model naturally involves the mechanism of the Language Model (LM) that predicts the next token only based on partial translation. Despite its success, NMT still suffers from the hallucination problem, generating fluent but inadequate translations. The main reason is that NMT pays excessive attention to the partial translation while neglecting the source sentence to some extent, namely overconfidence of the LM. Accordingly, we define the Margin between the NMT and the LM, calculated by subtracting the predicted probability of the LM from that of the NMT model for each token. The Margin is negatively correlated to the overconfidence degree of the LM. Based on the property, we propose a Margin-based Token-level Objective (MTO) and a Margin-based Sentencelevel Objective (MSO) to maximize the Margin for preventing the LM from being overconfident. Experiments on WMT14 English-to-German, WMT19 Chinese-to-English, and WMT14 English-to-French translation tasks demonstrate the effectiveness of our approach, with 1.36, 1.50, and 0.63 BLEU improvements, respectively, compared to the Transformer baseline. The human evaluation further verifies that our approaches improve translation adequacy as well as fluency.