 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARK: A Lightweight Model Compression Approach for Large-scale Recommender Systems
Aug 18, 2023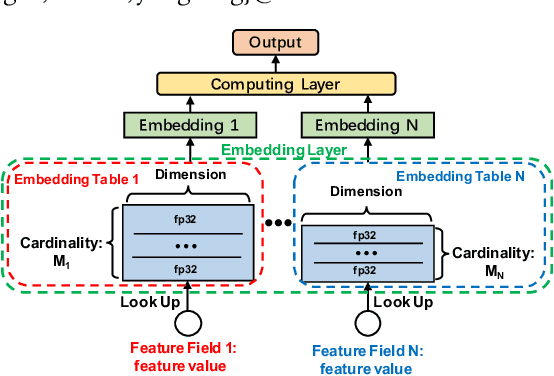


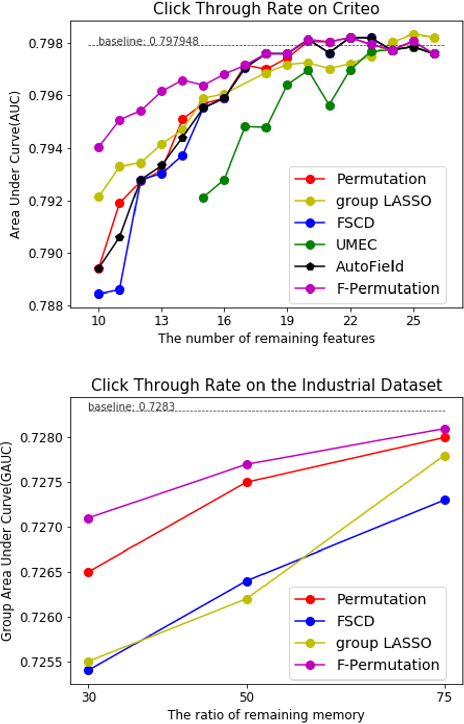
Increasing the size of embedding layers has shown to be effective in improving the performance of recommendation models, yet gradually causing their sizes to exceed terabytes in industrial recommender systems, and hence the increase of computing and storage costs. To save resources while maintaining model performances, we propose SHARK, the model compression practice we have summarized in the recommender system of industrial scenarios. SHARK consists of two main components. First, we use the novel first-order component of Taylor expansion as importance scores to prune the number of embedding tables (feature fields). Second, we introduce a new row-wise quantization method to apply different quantization strategies to each embedding. We conduct extensive experiments on both public and industrial datasets, demonstrating that each component of our proposed SHARK framework outperforms previous approaches. We conduct A/B tests in multiple models on Kuaishou, such as short video, e-commerce, and advertising recommendation models. The results of the online A/B test showed SHARK can effectively reduce the memory footprint of the embedded layer. For the short-video scenarios, the compressed model without any performance drop significantly saves 70% storage and thousands of machines, improves 30\% queries per second (QPS), and has been deployed to serve hundreds of millions of users and process tens of billions of requests every day.
Prevent the Language Model from being Overconfident in Neural Machine Translation
May 31, 2021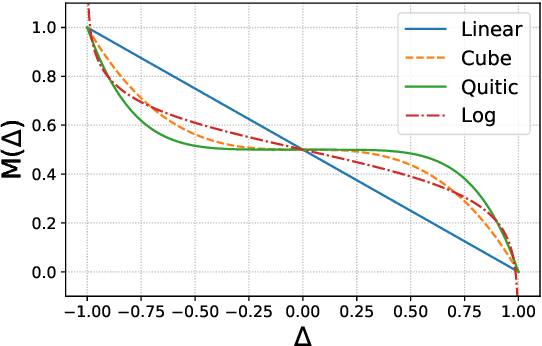
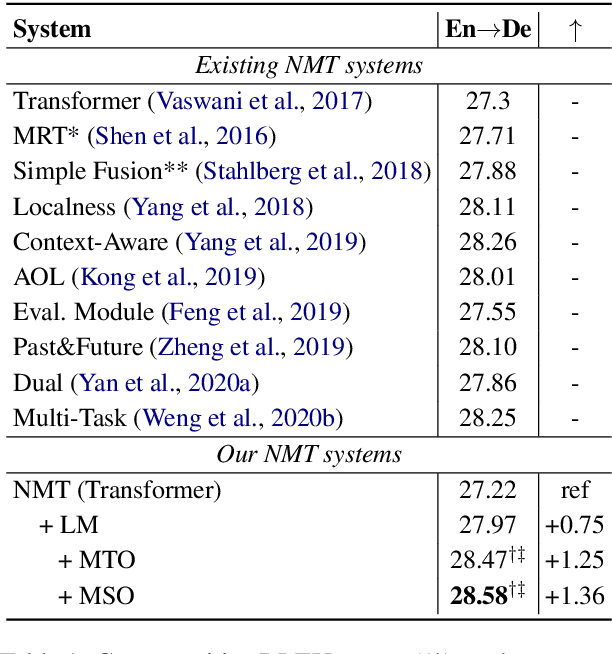

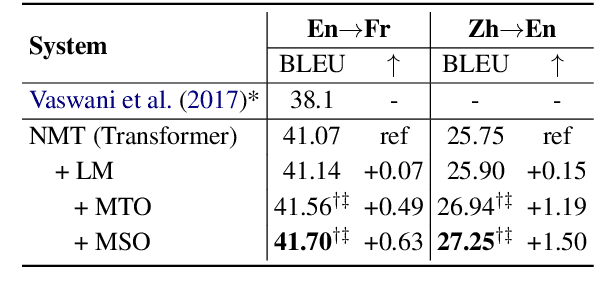
The Neural Machine Translation (NMT) model is essentially a joint language model conditioned on both the source sentence and partial translation. Therefore, the NMT model naturally involves the mechanism of the Language Model (LM) that predicts the next token only based on partial translation. Despite its success, NMT still suffers from the hallucination problem, generating fluent but inadequate translations. The main reason is that NMT pays excessive attention to the partial translation while neglecting the source sentence to some extent, namely overconfidence of the LM. Accordingly, we define the Margin between the NMT and the LM, calculated by subtracting the predicted probability of the LM from that of the NMT model for each token. The Margin is negatively correlated to the overconfidence degree of the LM. Based on the property, we propose a Margin-based Token-level Objective (MTO) and a Margin-based Sentencelevel Objective (MSO) to maximize the Margin for preventing the LM from being overconfident. Experiments on WMT14 English-to-German, WMT19 Chinese-to-English, and WMT14 English-to-French translation tasks demonstrate the effectiveness of our approach, with 1.36, 1.50, and 0.63 BLEU improvements, respectively, compared to the Transformer baseline. The human evaluation further verifies that our approaches improve translation adequacy as well as fluency.