 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Song Generation and Singing Voice Conversion with Accompaniment Co-Generation
Jun 05, 2026While song generation and singing voice conversion (SVC) have evolved significantly, they have long been developed isolated: the former lacks zero-shot speaker cloning, while the latter overlooks vocal-accompaniment synergy. To bridge this gap, we propose UniSinger, the first end-to-end framework unifying speaker cloning song generation and accompaniment co-generation SVC. Building on the multimodal diffusion transformer, we construct a unified speaker embedding space transferring speaker representation from SVC to song generation, endowing fine-grained cross-task timbre control. To mitigate multi-task optimization conflicts, we design a curriculum learning strategy using task-specific modality masking to guide the model to gradually master the generative mechanisms among semantic content, vocal timbre, and accompaniment. Experiments show state-of-the-art performance on both tasks and realizes complementary benefits, offering new possibilities for intelligent music production.
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
MM-Sonate: Multimodal Controllable Audio-Video Generation with Zero-Shot Voice Cloning
Jan 08, 2026Joint audio-video generation aims to synthesize synchronized multisensory content, yet current unified models struggle with fine-grained acoustic control, particularly for identity-preserving speech. Existing approaches either suffer from temporal misalignment due to cascaded generation or lack the capability to perform zero-shot voice cloning within a joint synthesis framework. In this work, we present MM-Sonate, a multimodal flow-matching framework that unifies controllable audio-video joint generation with zero-shot voice cloning capabilities. Unlike prior works that rely on coarse semantic descriptions, MM-Sonate utilizes a unified instruction-phoneme input to enforce strict linguistic and temporal alignment. To enable zero-shot voice cloning, we introduce a timbre injection mechanism that effectively decouples speaker identity from linguistic content. Furthermore, addressing the limitations of standard classifier-free guidance in multimodal settings, we propose a noise-based negative conditioning strategy that utilizes natural noise priors to significantly enhance acoustic fidelity. Empirical evaluations demonstrate that MM-Sonate establishes new state-of-the-art performance in joint generation benchmarks, significantly outperforming baselines in lip synchronization and speech intelligibility, while achieving voice cloning fidelity comparable to specialized Text-to-Speech systems.
Cross-Modal Consistency-Guided Active Learning for Affective BCI Systems
Nov 19, 2025

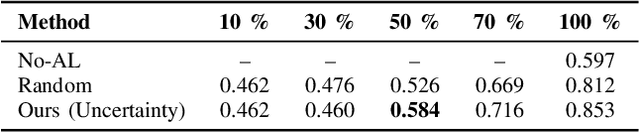
Deep learning models perform best with abundant, high-quality labels, yet such conditions are rarely achievable in EEG-based emotion recognition. Electroencephalogram (EEG) signals are easily corrupted by artifacts and individual variability, while emotional labels often stem from subjective and inconsistent reports-making robust affective decoding particularly difficult. We propose an uncertainty-aware active learning framework that enhances robustness to label noise by jointly leveraging model uncertainty and cross-modal consistency. Instead of relying solely on EEG-based uncertainty estimates, the method evaluates cross-modal alignment to determine whether uncertainty originates from cognitive ambiguity or sensor noise. A representation alignment module embeds EEG and face features into a shared latent space, enforcing semantic coherence between modalities. Residual discrepancies are treated as noise-induced inconsistencies, and these samples are selectively queried for oracle feedback during active learning. This feedback-driven process guides the network toward reliable, informative samples and reduces the impact of noisy labels. Experiments on the ASCERTAIN dataset examine the efficiency and robustness of ours, highlighting its potential as a data-efficient and noise-tolerant approach for EEG-based affective decoding in brain-computer interface systems.
NeuroLex: A Lightweight Domain Language Model for EEG Report Understanding and Generation
Nov 17, 2025



Clinical electroencephalogram (EEG) reports encode domain-specific linguistic conventions that general-purpose language models (LMs) fail to capture. We introduce NeuroLex, a lightweight domain-adaptive language model trained purely on EEG report text from the Harvard Electroencephalography Database. Unlike existing biomedical LMs, NeuroLex is tailored to the linguistic and diagnostic characteristics of EEG reporting, enabling it to serve as both an independent textual model and a decoder backbone for multimodal EEG-language systems. Using span-corruption pretraining and instruction-style fine-tuning on report polishing, paragraph summarization, and terminology question answering, NeuroLex learns the syntax and reasoning patterns characteristic of EEG interpretation. Comprehensive evaluations show that it achieves lower perplexity, higher extraction and summarization accuracy, better label efficiency, and improved robustness to negation and factual hallucination compared with general models of the same scale. With an EEG-aware linguistic backbone, NeuroLex bridges biomedical text modeling and brain-computer interface applications, offering a foundation for interpretable and language-driven neural decoding.
Semantic Prioritization in Visual Counterfactual Explanations with Weighted Segmentation and Auto-Adaptive Region Selection
Nov 17, 2025In the domain of non-generative visual counterfactual explanations (CE), traditional techniques frequently involve the substitution of sections within a query image with corresponding sections from distractor images. Such methods have historically overlooked the semantic relevance of the replacement regions to the target object, thereby impairing the model's interpretability and hindering the editing workflow. Addressing these challenges, the present study introduces an innovative methodology named as Weighted Semantic Map with Auto-adaptive Candidate Editing Network (WSAE-Net). Characterized by two significant advancements: the determination of an weighted semantic map and the auto-adaptive candidate editing sequence. First, the generation of the weighted semantic map is designed to maximize the reduction of non-semantic feature units that need to be computed, thereby optimizing computational efficiency. Second, the auto-adaptive candidate editing sequences are designed to determine the optimal computational order among the feature units to be processed, thereby ensuring the efficient generation of counterfactuals while maintaining the semantic relevance of the replacement feature units to the target object. Through comprehensive experimentation, our methodology demonstrates superior performance, contributing to a more lucid and in-depth understanding of visual counterfactual explanations.
Towards Fine-Grained Interpretability: Counterfactual Explanations for Misclassification with Saliency Partition
Nov 11, 2025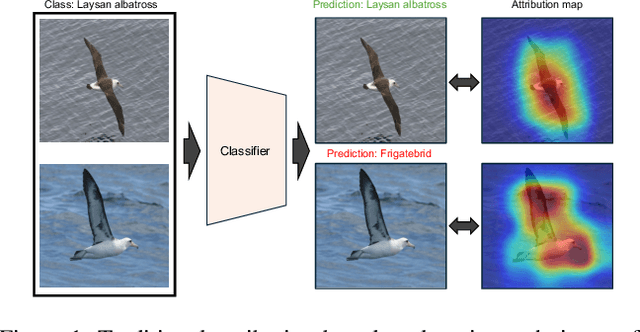
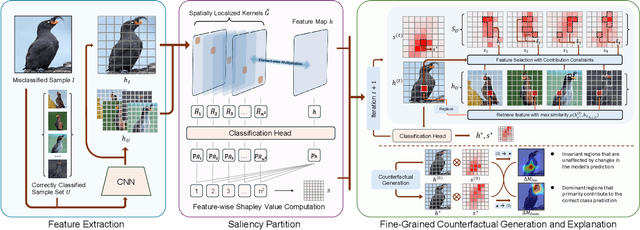

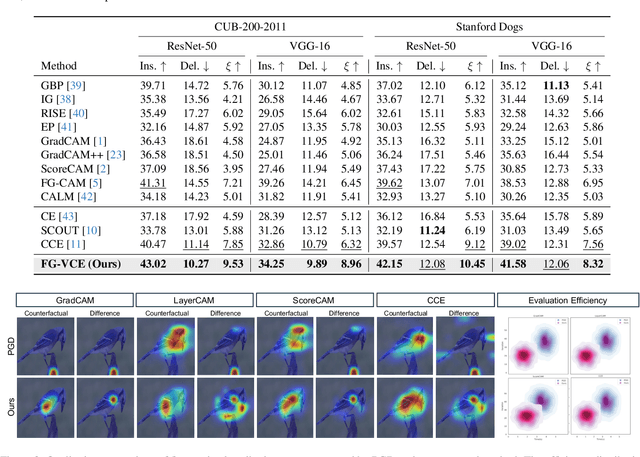
Attribution-based explanation techniques capture key patterns to enhance visual interpretability; however, these patterns often lack the granularity needed for insight in fine-grained tasks, particularly in cases of model misclassification, where explanations may be insufficiently detailed. To address this limitation, we propose a fine-grained counterfactual explanation framework that generates both object-level and part-level interpretability, addressing two fundamental questions: (1) which fine-grained features contribute to model misclassification, and (2) where dominant local features influence counterfactual adjustments. Our approach yields explainable counterfactuals in a non-generative manner by quantifying similarity and weighting component contributions within regions of interest between correctly classified and misclassified samples. Furthermore, we introduce a saliency partition module grounded in Shapley value contributions, isolating features with region-specific relevance. Extensive experiments demonstrate the superiority of our approach in capturing more granular, intuitively meaningful regions, surpassing fine-grained methods.
Reconstructing Unseen Sentences from Speech-related Biosignals for Open-vocabulary Neural Communication
Oct 31, 2025Brain-to-speech (BTS) systems represent a groundbreaking approach to human communication by enabling the direct transformation of neural activity into linguistic expressions. While recent non-invasive BTS studies have largely focused on decoding predefined words or sentences, achieving open-vocabulary neural communication comparable to natural human interaction requires decoding unconstrained speech. Additionally, effectively integrating diverse signals derived from speech is crucial for developing personalized and adaptive neural communication and rehabilitation solutions for patients. This study investigates the potential of speech synthesis for previously unseen sentences across various speech modes by leveraging phoneme-level information extracted from high-density electroencephalography (EEG) signals, both independently and in conjunction with electromyography (EMG) signals. Furthermore, we examine the properties affecting phoneme decoding accuracy during sentence reconstruction and offer neurophysiological insights to further enhance EEG decoding for more effective neural communication solutions. Our findings underscore the feasibility of biosignal-based sentence-level speech synthesis for reconstructing unseen sentences, highlighting a significant step toward developing open-vocabulary neural communication systems adapted to diverse patient needs and conditions. Additionally, this study provides meaningful insights into the development of communication and rehabilitation solutions utilizing EEG-based decoding technologies.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
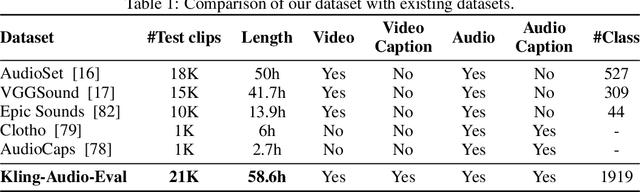
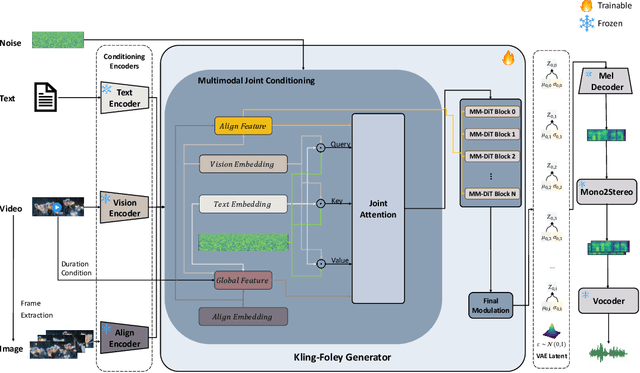
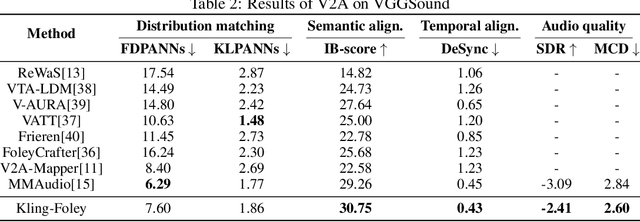
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
EEG-based Multimodal Representation Learning for Emotion Recognition
Oct 29, 2024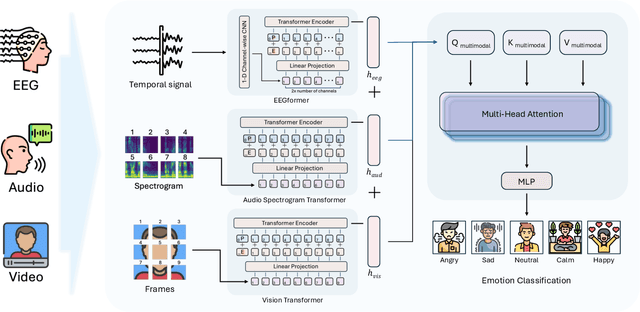
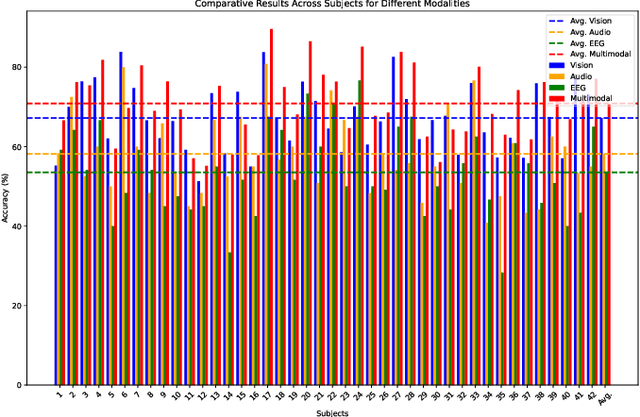
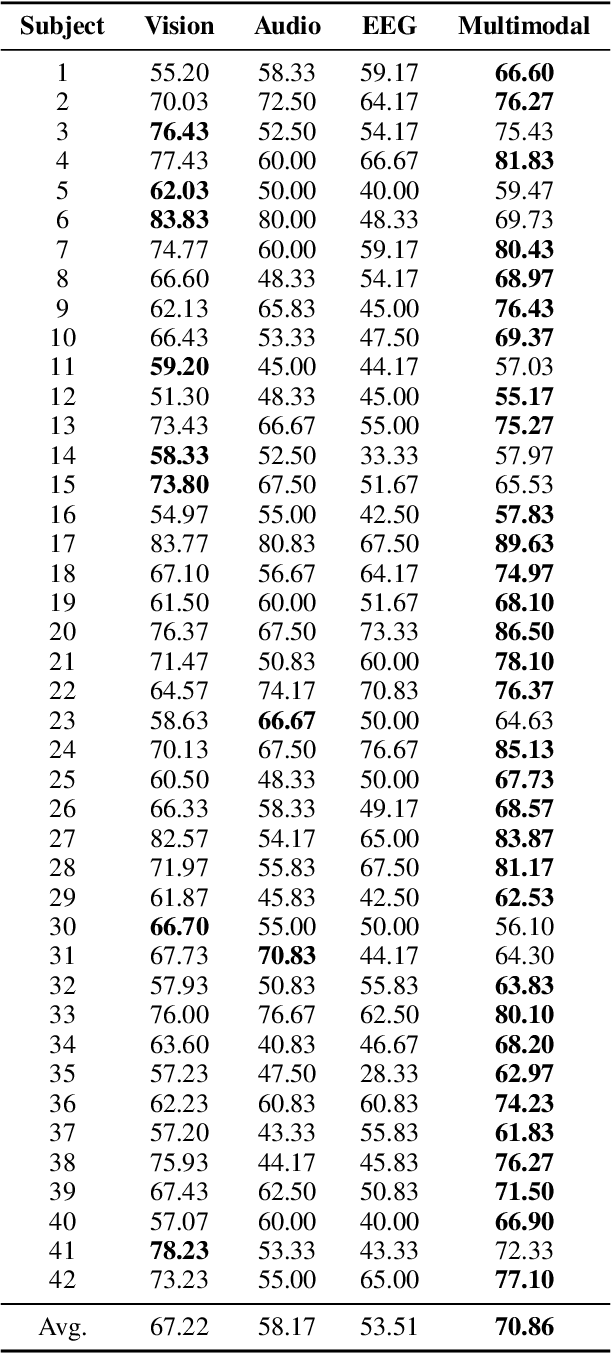
Multimodal learning has been a popular area of research, yet integrating electroencephalogram (EEG) data poses unique challenges due to its inherent variability and limited availability. In this paper, we introduce a novel multimodal framework that accommodates not only conventional modalities such as video, images, and audio, but also incorporates EEG data. Our framework is designed to flexibly handle varying input sizes, while dynamically adjusting attention to account for feature importance across modalities. We evaluate our approach on a recently introduced emotion recognition dataset that combines data from three modalities, making it an ideal testbed for multimodal learning. The experimental results provide a benchmark for the dataset and demonstrate the effectiveness of the proposed framework. This work highlights the potential of integrating EEG into multimodal systems, paving the way for more robust and comprehensive applications in emotion recognition and beyond.