 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025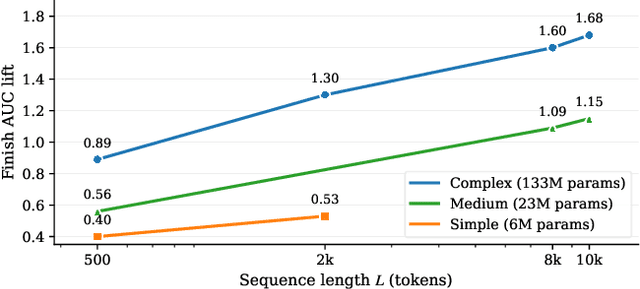
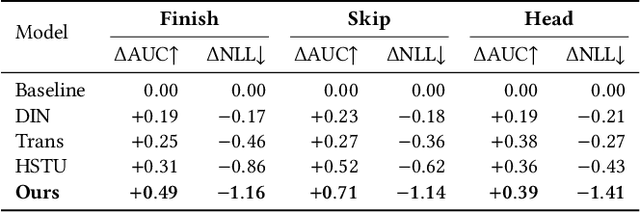
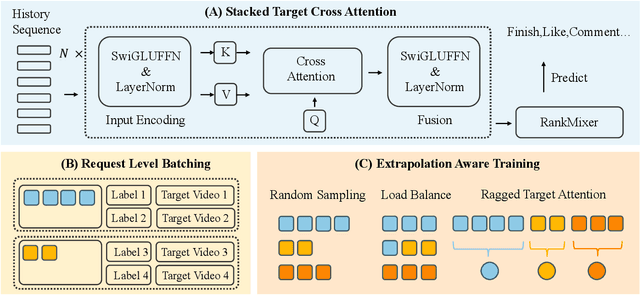

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
Full Stage Learning to Rank: A Unified Framework for Multi-Stage Systems
May 08, 2024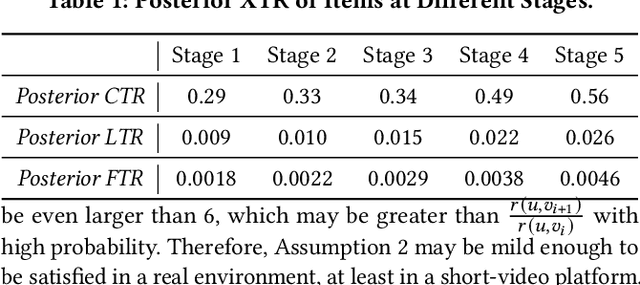
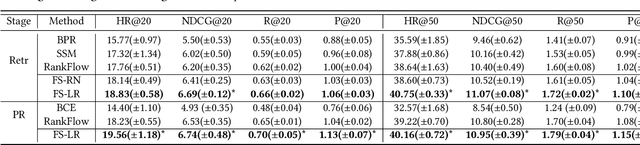
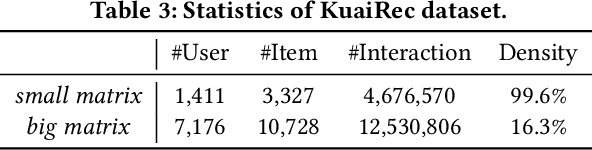

The Probability Ranking Principle (PRP) has been considered as the foundational standard in the design of information retrieval (IR) systems. The principle requires an IR module's returned list of results to be ranked with respect to the underlying user interests, so as to maximize the results' utility. Nevertheless, we point out that it is inappropriate to indiscriminately apply PRP through every stage of a contemporary IR system. Such systems contain multiple stages (e.g., retrieval, pre-ranking, ranking, and re-ranking stages, as examined in this paper). The \emph{selection bias} inherent in the model of each stage significantly influences the results that are ultimately presented to users. To address this issue, we propose an improved ranking principle for multi-stage systems, namely the Generalized Probability Ranking Principle (GPRP), to emphasize both the selection bias in each stage of the system pipeline as well as the underlying interest of users. We realize GPRP via a unified algorithmic framework named Full Stage Learning to Rank. Our core idea is to first estimate the selection bias in the subsequent stages and then learn a ranking model that best complies with the downstream modules' selection bias so as to deliver its top ranked results to the final ranked list in the system's output. We performed extensive experiment evaluations of our developed Full Stage Learning to Rank solution, using both simulations and online A/B tests in one of the leading short-video recommendation platforms. The algorithm is proved to be effective in both retrieval and ranking stages. Since deployed, the algorithm has brought consistent and significant performance gain to the platform.
SHARK: A Lightweight Model Compression Approach for Large-scale Recommender Systems
Aug 18, 2023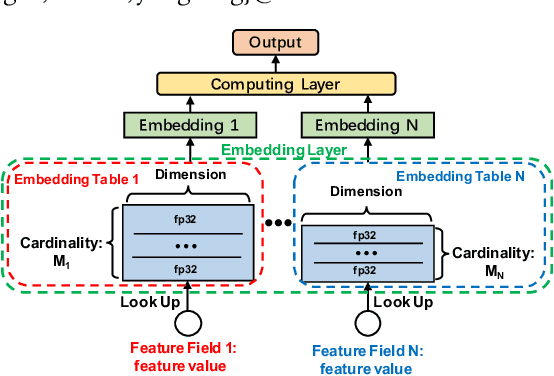


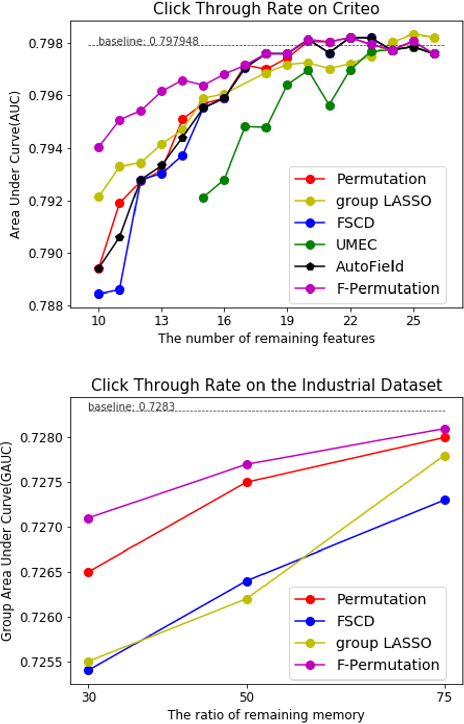
Increasing the size of embedding layers has shown to be effective in improving the performance of recommendation models, yet gradually causing their sizes to exceed terabytes in industrial recommender systems, and hence the increase of computing and storage costs. To save resources while maintaining model performances, we propose SHARK, the model compression practice we have summarized in the recommender system of industrial scenarios. SHARK consists of two main components. First, we use the novel first-order component of Taylor expansion as importance scores to prune the number of embedding tables (feature fields). Second, we introduce a new row-wise quantization method to apply different quantization strategies to each embedding. We conduct extensive experiments on both public and industrial datasets, demonstrating that each component of our proposed SHARK framework outperforms previous approaches. We conduct A/B tests in multiple models on Kuaishou, such as short video, e-commerce, and advertising recommendation models. The results of the online A/B test showed SHARK can effectively reduce the memory footprint of the embedded layer. For the short-video scenarios, the compressed model without any performance drop significantly saves 70% storage and thousands of machines, improves 30\% queries per second (QPS), and has been deployed to serve hundreds of millions of users and process tens of billions of requests every day.