 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak the Inaccessible Boundary: Distilling Post-Conversion Content for User Retention Modeling
Apr 28, 2026User retention is a key metric to measure long-term engagement in modern platforms. In real-time bidding (RTB) advertising system for user re-engagement, the retention model is required to predict future revisit probability at bidding time, before the user converts and consumes any content. Although post-conversion content, termed Onboarding Content, provides highly informative signals for retention prediction, directly using it in training causes severe feature leakage and creates a gap between training and serving. To address this issue, we propose OCARM, a two-stage distillation-aligned framework for Onboarding Content Augmented Retention Modeling, enabling the model to implicitly capture future content using only observable features during inference. In the first stage, we deliberately expose onboarding content to train a hierarchical encoder that produces teacher representations. In the second stage, a user encoder is aligned with the frozen teacher through distillation, allowing the model to approximate the inaccessible onboarding signals without leakage. Extensive offline experiments and online A/B tests demonstrate that our framework achieves consistent improvements in a real-world growth scenario.
UniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems
Apr 02, 2026In recent years, the scaling laws of recommendation models have attracted increasing attention, which govern the relationship between performance and parameters/FLOPs of recommenders. Currently, there are three mainstream architectures for achieving scaling in recommendation models, namely attention-based, TokenMixer-based, and factorization-machine-based methods, which exhibit fundamental differences in both design philosophy and architectural structure. In this paper, we propose a unified scaling architecture for recommendation systems, namely \textbf{UniMixer}, to improve scaling efficiency and establish a unified theoretical framework that unifies the mainstream scaling blocks. By transforming the rule-based TokenMixer to an equivalent parameterized structure, we construct a generalized parameterized feature mixing module that allows the token mixing patterns to be optimized and learned during model training. Meanwhile, the generalized parameterized token mixing removes the constraint in TokenMixer that requires the number of heads to be equal to the number of tokens. Furthermore, we establish a unified scaling module design framework for recommender systems, which bridges the connections among attention-based, TokenMixer-based, and factorization-machine-based methods. To further boost scaling ROI, a lightweight UniMixing module is designed, \textbf{UniMixing-Lite}, which further compresses the model parameters and computational cost while significantly improve the model performance. The scaling curves are shown in the following figure. Extensive offline and online experiments are conducted to verify the superior scaling abilities of \textbf{UniMixer}.
Solar Forecasting with Causality: A Graph-Transformer Approach to Spatiotemporal Dependencies
Sep 18, 2025Accurate solar forecasting underpins effective renewable energy management. We present SolarCAST, a causally informed model predicting future global horizontal irradiance (GHI) at a target site using only historical GHI from site X and nearby stations S - unlike prior work that relies on sky-camera or satellite imagery requiring specialized hardware and heavy preprocessing. To deliver high accuracy with only public sensor data, SolarCAST models three classes of confounding factors behind X-S correlations using scalable neural components: (i) observable synchronous variables (e.g., time of day, station identity), handled via an embedding module; (ii) latent synchronous factors (e.g., regional weather patterns), captured by a spatio-temporal graph neural network; and (iii) time-lagged influences (e.g., cloud movement across stations), modeled with a gated transformer that learns temporal shifts. It outperforms leading time-series and multimodal baselines across diverse geographical conditions, and achieves a 25.9% error reduction over the top commercial forecaster, Solcast. SolarCAST offers a lightweight, practical, and generalizable solution for localized solar forecasting.
* Accepted to CIKM 2025
KuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation
Aug 07, 2025

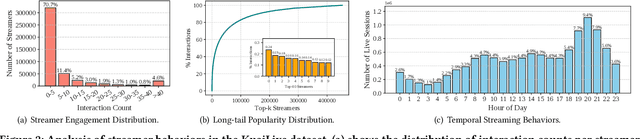
Live streaming platforms have become a dominant form of online content consumption, offering dynamically evolving content, real-time interactions, and highly engaging user experiences. These unique characteristics introduce new challenges that differentiate live streaming recommendation from traditional recommendation settings and have garnered increasing attention from industry in recent years. However, research progress in academia has been hindered by the lack of publicly available datasets that accurately reflect the dynamic nature of live streaming environments. To address this gap, we introduce KuaiLive, the first real-time, interactive dataset collected from Kuaishou, a leading live streaming platform in China with over 400 million daily active users. The dataset records the interaction logs of 23,772 users and 452,621 streamers over a 21-day period. Compared to existing datasets, KuaiLive offers several advantages: it includes precise live room start and end timestamps, multiple types of real-time user interactions (click, comment, like, gift), and rich side information features for both users and streamers. These features enable more realistic simulation of dynamic candidate items and better modeling of user and streamer behaviors. We conduct a thorough analysis of KuaiLive from multiple perspectives and evaluate several representative recommendation methods on it, establishing a strong benchmark for future research. KuaiLive can support a wide range of tasks in the live streaming domain, such as top-K recommendation, click-through rate prediction, watch time prediction, and gift price prediction. Moreover, its fine-grained behavioral data also enables research on multi-behavior modeling, multi-task learning, and fairness-aware recommendation. The dataset and related resources are publicly available at https://imgkkk574.github.io/KuaiLive.
RecFlow: An Industrial Full Flow Recommendation Dataset
Oct 28, 2024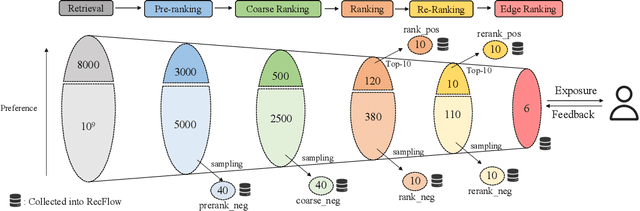
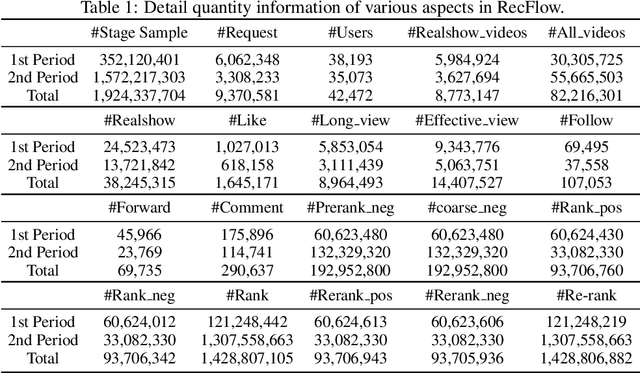

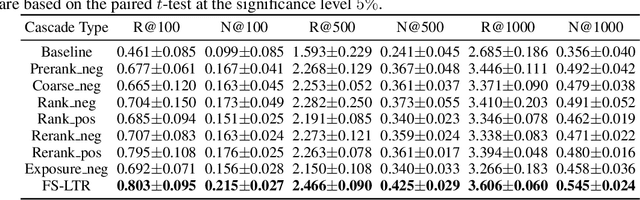
Industrial recommendation systems (RS) rely on the multi-stage pipeline to balance effectiveness and efficiency when delivering items from a vast corpus to users. Existing RS benchmark datasets primarily focus on the exposure space, where novel RS algorithms are trained and evaluated. However, when these algorithms transition to real world industrial RS, they face a critical challenge of handling unexposed items which are a significantly larger space than the exposed one. This discrepancy profoundly impacts their practical performance. Additionally, these algorithms often overlook the intricate interplay between multiple RS stages, resulting in suboptimal overall system performance. To address this issue, we introduce RecFlow, an industrial full flow recommendation dataset designed to bridge the gap between offline RS benchmarks and the real online environment. Unlike existing datasets, RecFlow includes samples not only from the exposure space but also unexposed items filtered at each stage of the RS funnel. Our dataset comprises 38M interactions from 42K users across nearly 9M items with additional 1.9B stage samples collected from 9.3M online requests over 37 days and spanning 6 stages. Leveraging the RecFlow dataset, we conduct courageous exploration experiments, showcasing its potential in designing new algorithms to enhance effectiveness by incorporating stage-specific samples. Some of these algorithms have already been deployed online, consistently yielding significant gains. We propose RecFlow as the first comprehensive benchmark dataset for the RS community, supporting research on designing algorithms at any stage, study of selection bias, debiased algorithms, multi-stage consistency and optimality, multi-task recommendation, and user behavior modeling. The RecFlow dataset, along with the corresponding source code, is available at https://github.com/RecFlow-ICLR/RecFlow.
TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
Jul 23, 2024



The significance of modeling long-term user interests for CTR prediction tasks in large-scale recommendation systems is progressively gaining attention among researchers and practitioners. Existing work, such as SIM and TWIN, typically employs a two-stage approach to model long-term user behavior sequences for efficiency concerns. The first stage rapidly retrieves a subset of sequences related to the target item from a long sequence using a search-based mechanism namely the General Search Unit (GSU), while the second stage calculates the interest scores using the Exact Search Unit (ESU) on the retrieved results. Given the extensive length of user behavior sequences spanning the entire life cycle, potentially reaching up to 10^6 in scale, there is currently no effective solution for fully modeling such expansive user interests. To overcome this issue, we introduced TWIN-V2, an enhancement of TWIN, where a divide-and-conquer approach is applied to compress life-cycle behaviors and uncover more accurate and diverse user interests. Specifically, a hierarchical clustering method groups items with similar characteristics in life-cycle behaviors into a single cluster during the offline phase. By limiting the size of clusters, we can compress behavior sequences well beyond the magnitude of 10^5 to a length manageable for online inference in GSU retrieval. Cluster-aware target attention extracts comprehensive and multi-faceted long-term interests of users, thereby making the final recommendation results more accurate and diverse. Extensive offline experiments on a multi-billion-scale industrial dataset and online A/B tests have demonstrated the effectiveness of TWIN-V2. Under an efficient deployment framework, TWIN-V2 has been successfully deployed to the primary traffic that serves hundreds of millions of daily active users at Kuaishou.
Full Stage Learning to Rank: A Unified Framework for Multi-Stage Systems
May 08, 2024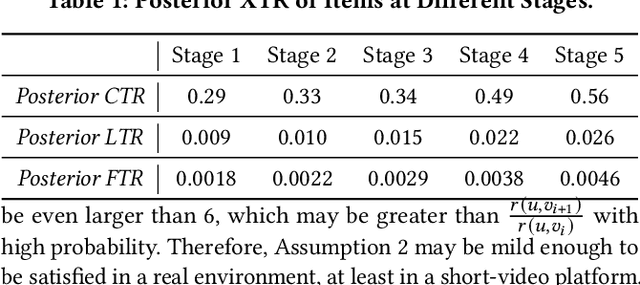
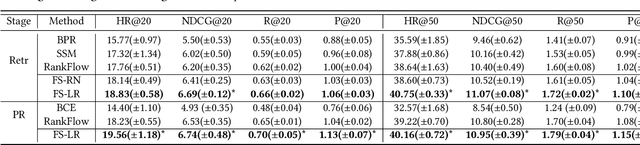

The Probability Ranking Principle (PRP) has been considered as the foundational standard in the design of information retrieval (IR) systems. The principle requires an IR module's returned list of results to be ranked with respect to the underlying user interests, so as to maximize the results' utility. Nevertheless, we point out that it is inappropriate to indiscriminately apply PRP through every stage of a contemporary IR system. Such systems contain multiple stages (e.g., retrieval, pre-ranking, ranking, and re-ranking stages, as examined in this paper). The \emph{selection bias} inherent in the model of each stage significantly influences the results that are ultimately presented to users. To address this issue, we propose an improved ranking principle for multi-stage systems, namely the Generalized Probability Ranking Principle (GPRP), to emphasize both the selection bias in each stage of the system pipeline as well as the underlying interest of users. We realize GPRP via a unified algorithmic framework named Full Stage Learning to Rank. Our core idea is to first estimate the selection bias in the subsequent stages and then learn a ranking model that best complies with the downstream modules' selection bias so as to deliver its top ranked results to the final ranked list in the system's output. We performed extensive experiment evaluations of our developed Full Stage Learning to Rank solution, using both simulations and online A/B tests in one of the leading short-video recommendation platforms. The algorithm is proved to be effective in both retrieval and ranking stages. Since deployed, the algorithm has brought consistent and significant performance gain to the platform.
UniSAR: Modeling User Transition Behaviors between Search and Recommendation
Apr 15, 2024Nowadays, many platforms provide users with both search and recommendation services as important tools for accessing information. The phenomenon has led to a correlation between user search and recommendation behaviors, providing an opportunity to model user interests in a fine-grained way. Existing approaches either model user search and recommendation behaviors separately or overlook the different transitions between user search and recommendation behaviors. In this paper, we propose a framework named UniSAR that effectively models the different types of fine-grained behavior transitions for providing users a Unified Search And Recommendation service. Specifically, UniSAR models the user transition behaviors between search and recommendation through three steps: extraction, alignment, and fusion, which are respectively implemented by transformers equipped with pre-defined masks, contrastive learning that aligns the extracted fine-grained user transitions, and cross-attentions that fuse different transitions. To provide users with a unified service, the learned representations are fed into the downstream search and recommendation models. Joint learning on both search and recommendation data is employed to utilize the knowledge and enhance each other. Experimental results on two public datasets demonstrated the effectiveness of UniSAR in terms of enhancing both search and recommendation simultaneously. The experimental analysis further validates that UniSAR enhances the results by successfully modeling the user transition behaviors between search and recommendation.
Ensure Timeliness and Accuracy: A Novel Sliding Window Data Stream Paradigm for Live Streaming Recommendation
Feb 22, 2024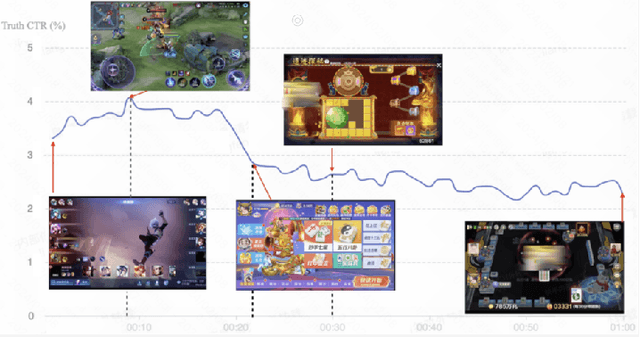

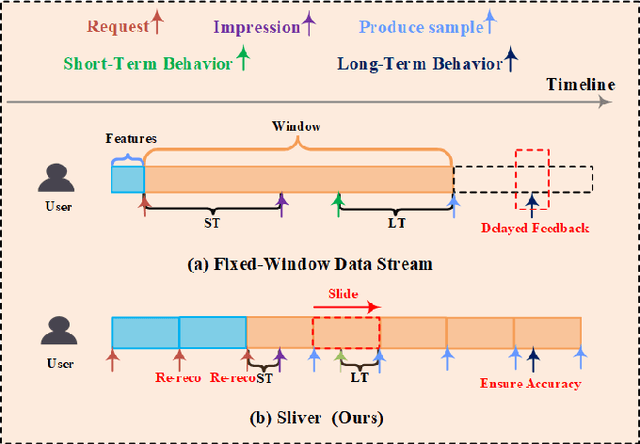

Live streaming recommender system is specifically designed to recommend real-time live streaming of interest to users. Due to the dynamic changes of live content, improving the timeliness of the live streaming recommender system is a critical problem. Intuitively, the timeliness of the data determines the upper bound of the timeliness that models can learn. However, none of the previous works addresses the timeliness problem of the live streaming recommender system from the perspective of data stream design. Employing the conventional fixed window data stream paradigm introduces a trade-off dilemma between labeling accuracy and timeliness. In this paper, we propose a new data stream design paradigm, dubbed Sliver, that addresses the timeliness and accuracy problem of labels by reducing the window size and implementing a sliding window correspondingly. Meanwhile, we propose a time-sensitive re-reco strategy reducing the latency between request and impression to improve the timeliness of the recommendation service and features by periodically requesting the recommendation service. To demonstrate the effectiveness of our approach, we conduct offline experiments on a multi-task live streaming dataset with labeling timestamps collected from the Kuaishou live streaming platform. Experimental results demonstrate that Sliver outperforms two fixed-window data streams with varying window sizes across all targets in four typical multi-task recommendation models. Furthermore, we deployed Sliver on the Kuaishou live streaming platform. Results of the online A/B test show a significant improvement in click-through rate (CTR), and new follow number (NFN), further validating the effectiveness of Sliver.
LabelCraft: Empowering Short Video Recommendations with Automated Label Crafting
Dec 18, 2023Short video recommendations often face limitations due to the quality of user feedback, which may not accurately depict user interests. To tackle this challenge, a new task has emerged: generating more dependable labels from original feedback. Existing label generation methods rely on manual rules, demanding substantial human effort and potentially misaligning with the desired objectives of the platform. To transcend these constraints, we introduce LabelCraft, a novel automated label generation method explicitly optimizing pivotal operational metrics for platform success. By formulating label generation as a higher-level optimization problem above recommender model optimization, LabelCraft introduces a trainable labeling model for automatic label mechanism modeling. Through meta-learning techniques, LabelCraft effectively addresses the bi-level optimization hurdle posed by the recommender and labeling models, enabling the automatic acquisition of intricate label generation mechanisms.Extensive experiments on real-world datasets corroborate LabelCraft's excellence across varied operational metrics, encompassing usage time, user engagement, and retention. Codes are available at https://github.com/baiyimeng/LabelCraft.