 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecFlow: An Industrial Full Flow Recommendation Dataset
Oct 28, 2024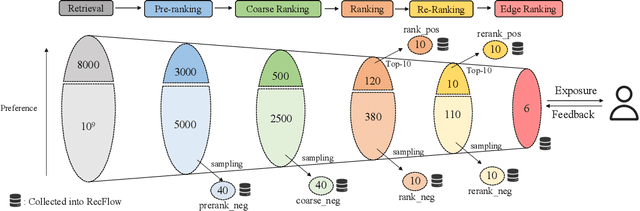
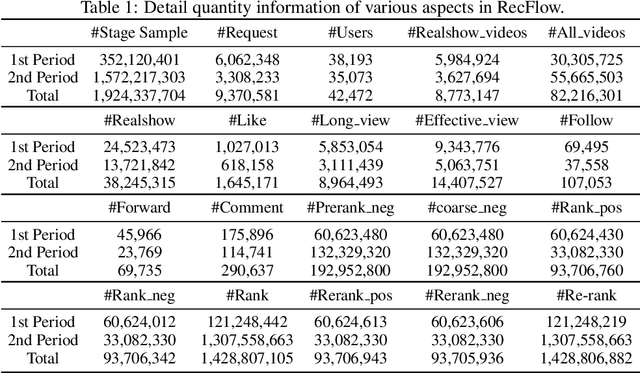

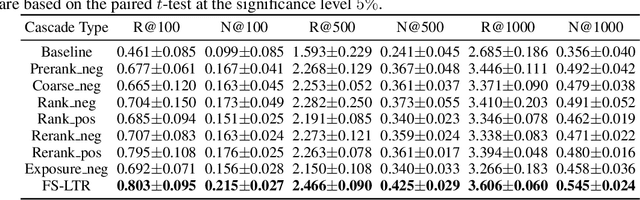
Industrial recommendation systems (RS) rely on the multi-stage pipeline to balance effectiveness and efficiency when delivering items from a vast corpus to users. Existing RS benchmark datasets primarily focus on the exposure space, where novel RS algorithms are trained and evaluated. However, when these algorithms transition to real world industrial RS, they face a critical challenge of handling unexposed items which are a significantly larger space than the exposed one. This discrepancy profoundly impacts their practical performance. Additionally, these algorithms often overlook the intricate interplay between multiple RS stages, resulting in suboptimal overall system performance. To address this issue, we introduce RecFlow, an industrial full flow recommendation dataset designed to bridge the gap between offline RS benchmarks and the real online environment. Unlike existing datasets, RecFlow includes samples not only from the exposure space but also unexposed items filtered at each stage of the RS funnel. Our dataset comprises 38M interactions from 42K users across nearly 9M items with additional 1.9B stage samples collected from 9.3M online requests over 37 days and spanning 6 stages. Leveraging the RecFlow dataset, we conduct courageous exploration experiments, showcasing its potential in designing new algorithms to enhance effectiveness by incorporating stage-specific samples. Some of these algorithms have already been deployed online, consistently yielding significant gains. We propose RecFlow as the first comprehensive benchmark dataset for the RS community, supporting research on designing algorithms at any stage, study of selection bias, debiased algorithms, multi-stage consistency and optimality, multi-task recommendation, and user behavior modeling. The RecFlow dataset, along with the corresponding source code, is available at https://github.com/RecFlow-ICLR/RecFlow.
Cross-Lingual Ability of Multilingual Masked Language Models: A Study of Language Structure
Mar 16, 2022



Multilingual pre-trained language models, such as mBERT and XLM-R, have shown impressive cross-lingual ability. Surprisingly, both of them use multilingual masked language model (MLM) without any cross-lingual supervision or aligned data. Despite the encouraging results, we still lack a clear understanding of why cross-lingual ability could emerge from multilingual MLM. In our work, we argue that cross-language ability comes from the commonality between languages. Specifically, we study three language properties: constituent order, composition and word co-occurrence. First, we create an artificial language by modifying property in source language. Then we study the contribution of modified property through the change of cross-language transfer results on target language. We conduct experiments on six languages and two cross-lingual NLP tasks (textual entailment, sentence retrieval). Our main conclusion is that the contribution of constituent order and word co-occurrence is limited, while the composition is more crucial to the success of cross-linguistic transfer.
CogTree: Cognition Tree Loss for Unbiased Scene Graph Generation
Sep 16, 2020



Scene graphs are semantic abstraction of images that encourage visual understanding and reasoning. However, the performance of Scene Graph Generation (SGG) is unsatisfactory when faced with biased data in real-world scenarios. Conventional debiasing research mainly studies from the view of data representation, e.g. balancing data distribution or learning unbiased models and representations, ignoring the mechanism that how humans accomplish this task. Inspired by the role of the prefrontal cortex (PFC) in hierarchical reasoning, we analyze this problem from a novel cognition perspective: learning a hierarchical cognitive structure of the highly-biased relationships and navigating that hierarchy to locate the classes, making the tail classes receive more attention in a coarse-to-fine mode. To this end, we propose a novel Cognition Tree (CogTree) loss for unbiased SGG. We first build a cognitive structure CogTree to organize the relationships based on the prediction of a biased SGG model. The CogTree distinguishes remarkably different relationships at first and then focuses on a small portion of easily confused ones. Then, we propose a hierarchical loss specially for this cognitive structure, which supports coarse-to-fine distinction for the correct relationships while progressively eliminating the interference of irrelevant ones. The loss is model-independent and can be applied to various SGG models without extra supervision. The proposed CogTree loss consistently boosts the performance of several state-of-the-art models on the Visual Genome benchmark.
Gait Graph Optimization: Generate Variable Gaits from One Base Gait for Lower-limb Rehabilitation Exoskeleton Robots
Jan 15, 2020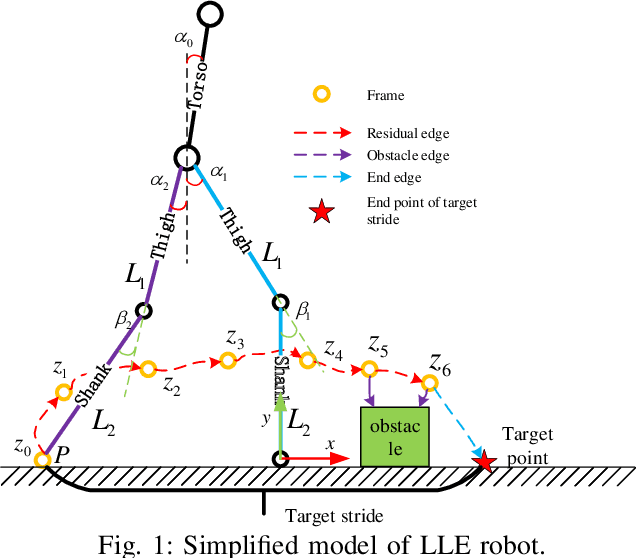

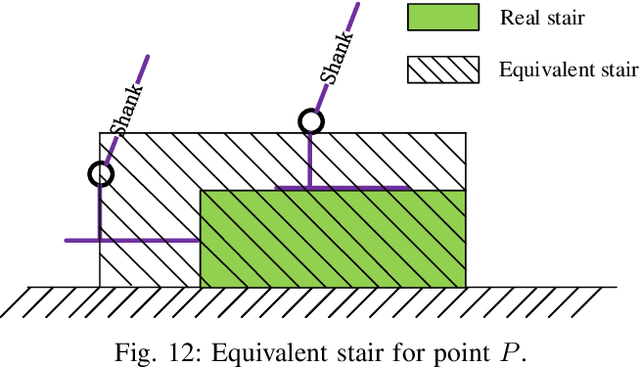

The most concentrated application of lower-limb rehabilitation exoskeleton (LLE) robot is that it can help paraplegics "re-walk". However, "walking" in daily life is more than just walking on flat ground with fixed gait. This paper focuses on variable gaits generation for LLE robot to adapt complex walking environment. Different from traditional gaits generator for biped robot, the generated gaits for LLEs should be comfortable to patients. Inspired by the pose graph optimization algorithm in SLAM, we propose a graph-based gait generation algorithm called gait graph optimization (GGO) to generate variable, functional and comfortable gaits from one base gait collected from healthy individuals to adapt the walking environment. Variants of walking problem, e.g., stride adjustment, obstacle avoidance, and stair ascent and descent, help verify the proposed approach in simulation and experimentation. We open source our implementation.