 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsure Timeliness and Accuracy: A Novel Sliding Window Data Stream Paradigm for Live Streaming Recommendation
Feb 22, 2024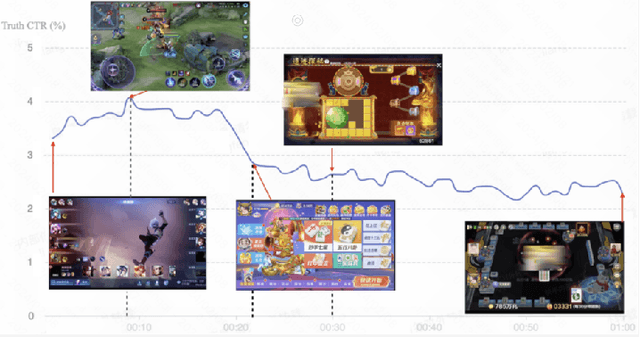

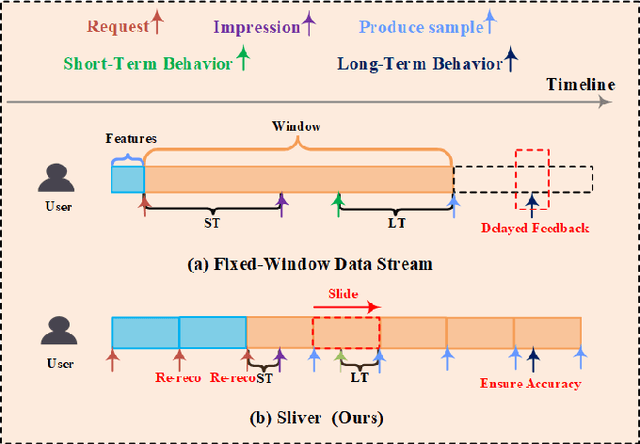

Live streaming recommender system is specifically designed to recommend real-time live streaming of interest to users. Due to the dynamic changes of live content, improving the timeliness of the live streaming recommender system is a critical problem. Intuitively, the timeliness of the data determines the upper bound of the timeliness that models can learn. However, none of the previous works addresses the timeliness problem of the live streaming recommender system from the perspective of data stream design. Employing the conventional fixed window data stream paradigm introduces a trade-off dilemma between labeling accuracy and timeliness. In this paper, we propose a new data stream design paradigm, dubbed Sliver, that addresses the timeliness and accuracy problem of labels by reducing the window size and implementing a sliding window correspondingly. Meanwhile, we propose a time-sensitive re-reco strategy reducing the latency between request and impression to improve the timeliness of the recommendation service and features by periodically requesting the recommendation service. To demonstrate the effectiveness of our approach, we conduct offline experiments on a multi-task live streaming dataset with labeling timestamps collected from the Kuaishou live streaming platform. Experimental results demonstrate that Sliver outperforms two fixed-window data streams with varying window sizes across all targets in four typical multi-task recommendation models. Furthermore, we deployed Sliver on the Kuaishou live streaming platform. Results of the online A/B test show a significant improvement in click-through rate (CTR), and new follow number (NFN), further validating the effectiveness of Sliver.
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training
Oct 21, 2020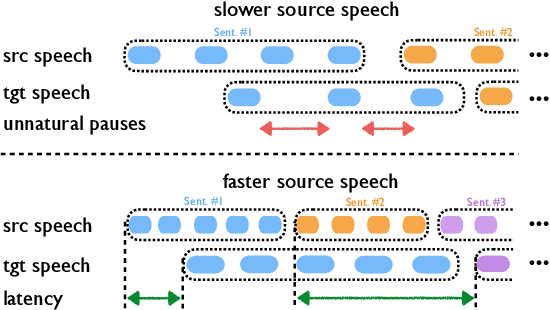
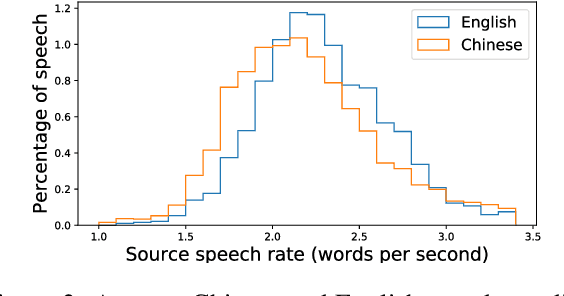
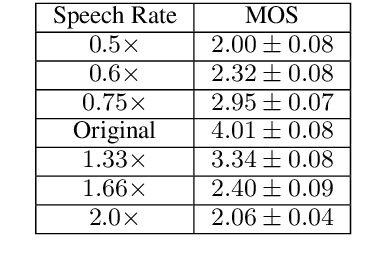
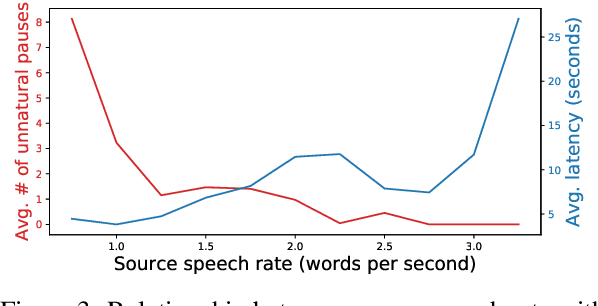
Simultaneous speech-to-speech translation is widely useful but extremely challenging, since it needs to generate target-language speech concurrently with the source-language speech, with only a few seconds delay. In addition, it needs to continuously translate a stream of sentences, but all recent solutions merely focus on the single-sentence scenario. As a result, current approaches accumulate latencies progressively when the speaker talks faster, and introduce unnatural pauses when the speaker talks slower. To overcome these issues, we propose Self-Adaptive Translation (SAT) which flexibly adjusts the length of translations to accommodate different source speech rates. At similar levels of translation quality (as measured by BLEU), our method generates more fluent target speech (as measured by the naturalness metric MOS) with substantially lower latency than the baseline, in both Zh <-> En directions.
* 10 pages, accepted by Findings of EMNLP 2020
Simultaneous Translation Policies: From Fixed to Adaptive
May 02, 2020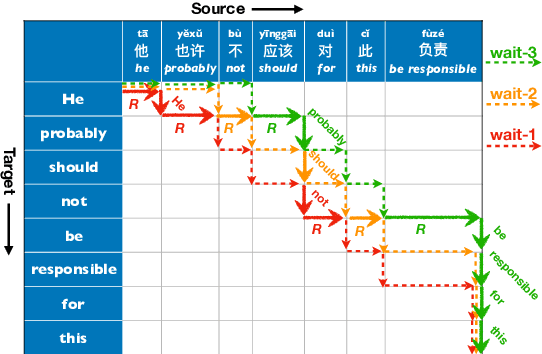

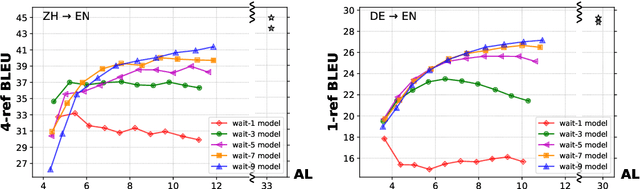

Adaptive policies are better than fixed policies for simultaneous translation, since they can flexibly balance the tradeoff between translation quality and latency based on the current context information. But previous methods on obtaining adaptive policies either rely on complicated training process, or underperform simple fixed policies. We design an algorithm to achieve adaptive policies via a simple heuristic composition of a set of fixed policies. Experiments on Chinese -> English and German -> English show that our adaptive policies can outperform fixed ones by up to 4 BLEU points for the same latency, and more surprisingly, it even surpasses the BLEU score of full-sentence translation in the greedy mode (and very close to beam mode), but with much lower latency.
Opportunistic Decoding with Timely Correction for Simultaneous Translation
May 02, 2020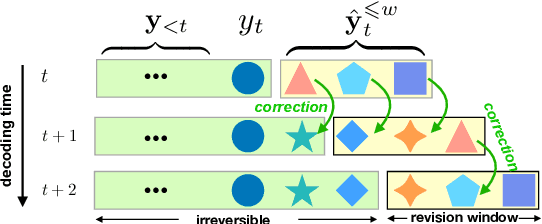

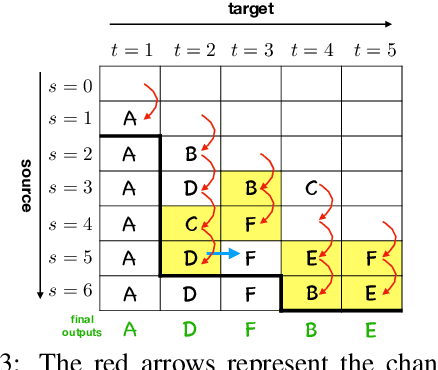
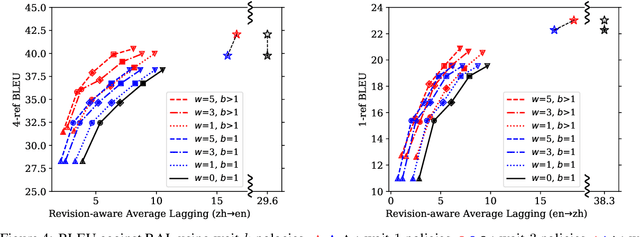
Simultaneous translation has many important application scenarios and attracts much attention from both academia and industry recently. Most existing frameworks, however, have difficulties in balancing between the translation quality and latency, i.e., the decoding policy is usually either too aggressive or too conservative. We propose an opportunistic decoding technique with timely correction ability, which always (over-)generates a certain mount of extra words at each step to keep the audience on track with the latest information. At the same time, it also corrects, in a timely fashion, the mistakes in the former overgenerated words when observing more source context to ensure high translation quality. Experiments show our technique achieves substantial reduction in latency and up to +3.1 increase in BLEU, with revision rate under 8% in Chinese-to-English and English-to-Chinese translation.
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Nov 07, 2019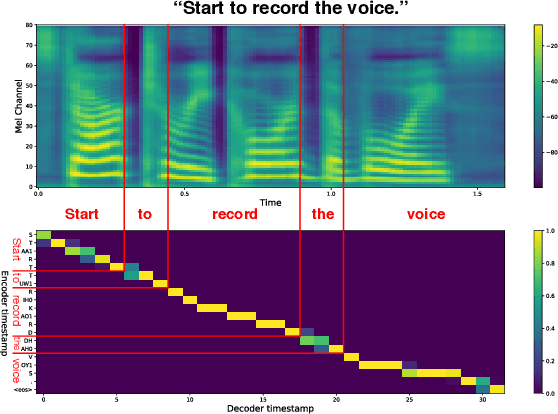
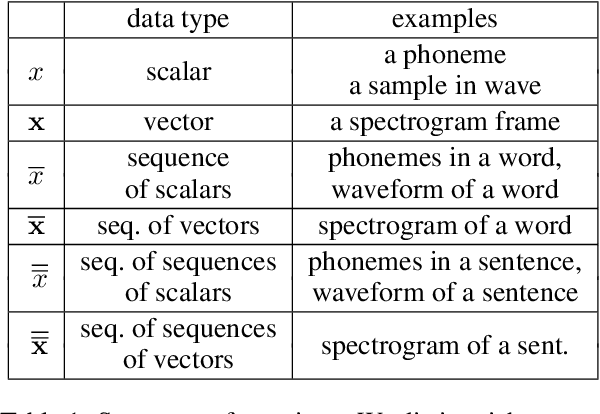
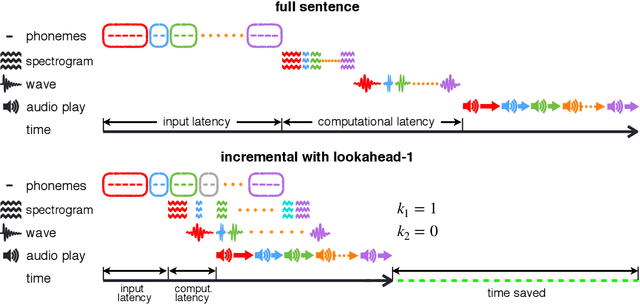
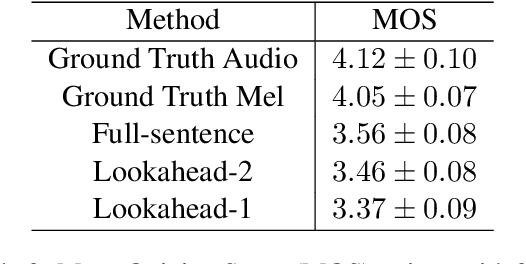
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.
Simpler and Faster Learning of Adaptive Policies for Simultaneous Translation
Sep 12, 2019
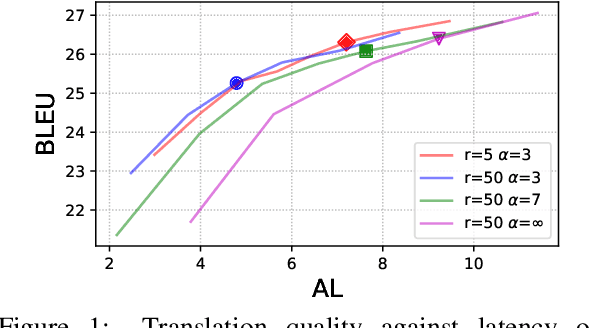
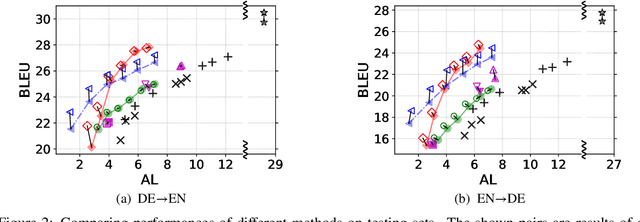
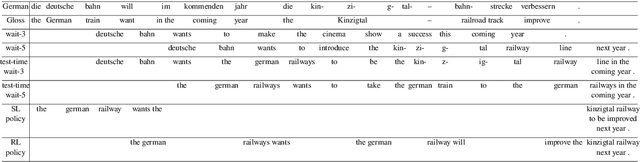
Simultaneous translation is widely useful but remains challenging. Previous work falls into two main categories: (a) fixed-latency policies such as Ma et al. (2019) and (b) adaptive policies such as Gu et al. (2017). The former are simple and effective, but have to aggressively predict future content due to diverging source-target word order; the latter do not anticipate, but suffer from unstable and inefficient training. To combine the merits of both approaches, we propose a simple supervised-learning framework to learn an adaptive policy from oracle READ/WRITE sequences generated from parallel text. At each step, such an oracle sequence chooses to WRITE the next target word if the available source sentence context provides enough information to do so, otherwise READ the next source word. Experiments on German<->English show that our method, without retraining the underlying NMT model, can learn flexible policies with better BLEU scores and similar latencies compared to previous work.
Speculative Beam Search for Simultaneous Translation
Sep 12, 2019

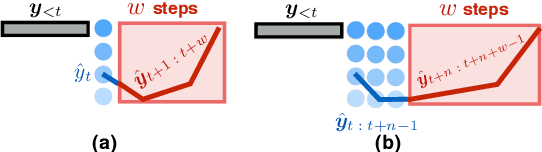
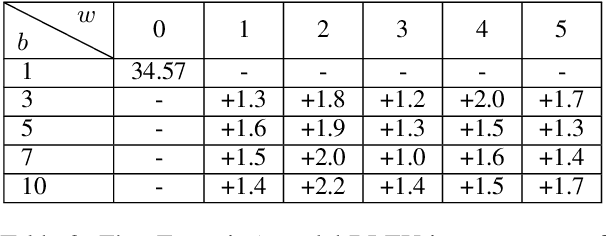
Beam search is universally used in full-sentence translation but its application to simultaneous translation remains non-trivial, where output words are committed on the fly. In particular, the recently proposed wait-k policy (Ma et al., 2019a) is a simple and effective method that (after an initial wait) commits one output word on receiving each input word, making beam search seemingly impossible. To address this challenge, we propose a speculative beam search algorithm that hallucinates several steps into the future in order to reach a more accurate decision, implicitly benefiting from a target language model. This makes beam search applicable for the first time to the generation of a single word in each step. Experiments over diverse language pairs show large improvements over previous work.
Robust Machine Translation with Domain Sensitive Pseudo-Sources: Baidu-OSU WMT19 MT Robustness Shared Task System Report
Jun 22, 2019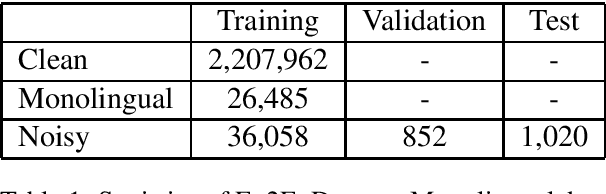
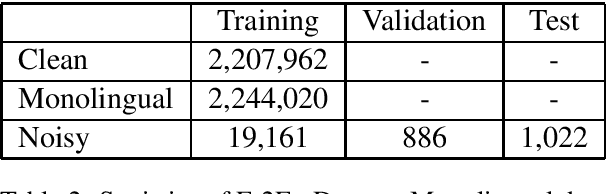
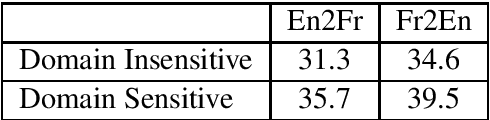
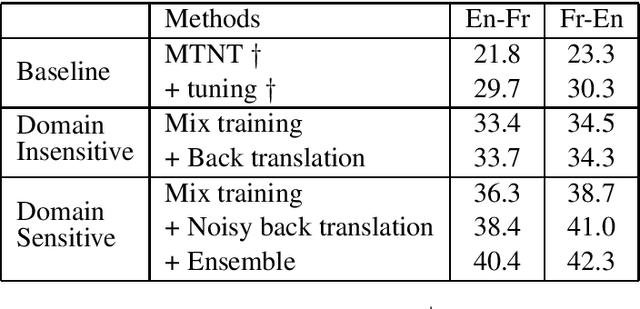
This paper describes the machine translation system developed jointly by Baidu Research and Oregon State University for WMT 2019 Machine Translation Robustness Shared Task. Translation of social media is a very challenging problem, since its style is very different from normal parallel corpora (e.g. News) and also include various types of noises. To make it worse, the amount of social media parallel corpora is extremely limited. In this paper, we use a domain sensitive training method which leverages a large amount of parallel data from popular domains together with a little amount of parallel data from social media. Furthermore, we generate a parallel dataset with pseudo noisy source sentences which are back-translated from monolingual data using a model trained by a similar domain sensitive way. We achieve more than 10 BLEU improvement in both En-Fr and Fr-En translation compared with the baseline methods.
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning
Jun 04, 2019
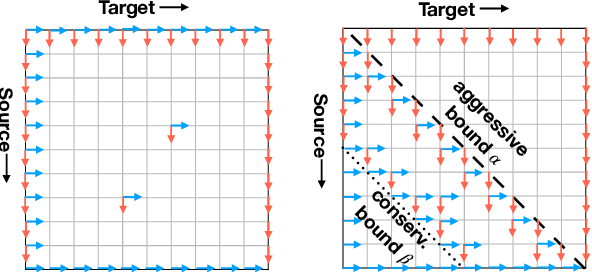
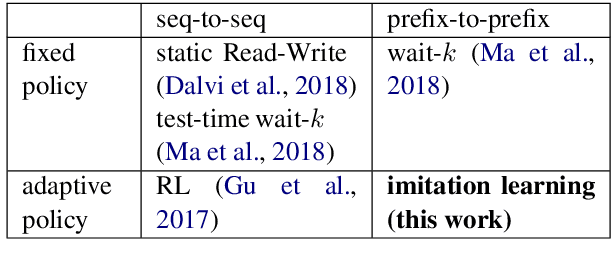
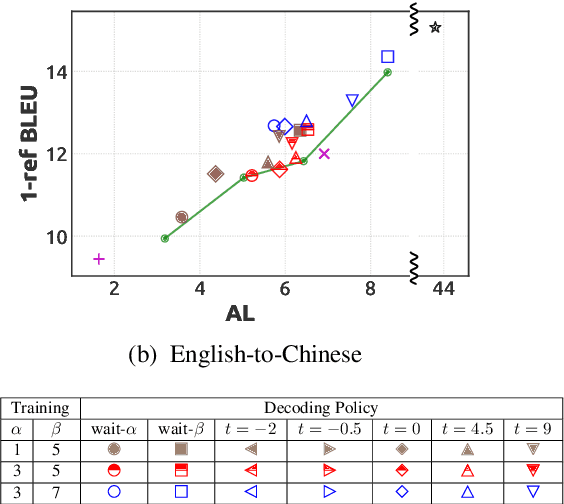
Simultaneous translation is widely useful but remains one of the most difficult tasks in NLP. Previous work either uses fixed-latency policies, or train a complicated two-staged model using reinforcement learning. We propose a much simpler single model that adds a `delay' token to the target vocabulary, and design a restricted dynamic oracle to greatly simplify training. Experiments on Chinese<->English simultaneous translation show that our work leads to flexible policies that achieve better BLEU scores and lower latencies compared to both fixed and RL-learned policies.