 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Machine Translation with Domain Sensitive Pseudo-Sources: Baidu-OSU WMT19 MT Robustness Shared Task System Report
Paper and Code
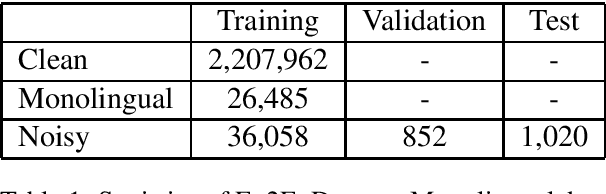
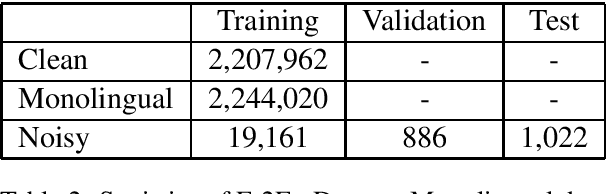
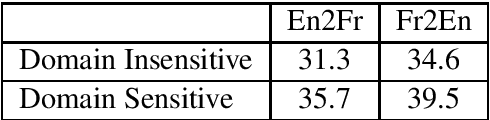
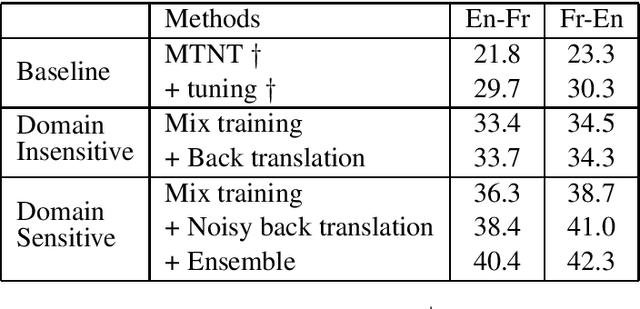
This paper describes the machine translation system developed jointly by Baidu Research and Oregon State University for WMT 2019 Machine Translation Robustness Shared Task. Translation of social media is a very challenging problem, since its style is very different from normal parallel corpora (e.g. News) and also include various types of noises. To make it worse, the amount of social media parallel corpora is extremely limited. In this paper, we use a domain sensitive training method which leverages a large amount of parallel data from popular domains together with a little amount of parallel data from social media. Furthermore, we generate a parallel dataset with pseudo noisy source sentences which are back-translated from monolingual data using a model trained by a similar domain sensitive way. We achieve more than 10 BLEU improvement in both En-Fr and Fr-En translation compared with the baseline methods.